Trong thập kỷ qua, lĩnh vực trí tuệ nhân tạo (AI) đã trải qua một sự chuyển đổi sâu sắc, phần lớn nhờ vào những thành công trong học sâu. Những tiến bộ đáng chú ý này đã định nghĩa lại ranh giới của năng lực AI, thách thức nhiều quan niệm định sẵn về những gì máy móc có thể đạt được. Các phần sau đây trình bày chi tiết một số tiến bộ này.
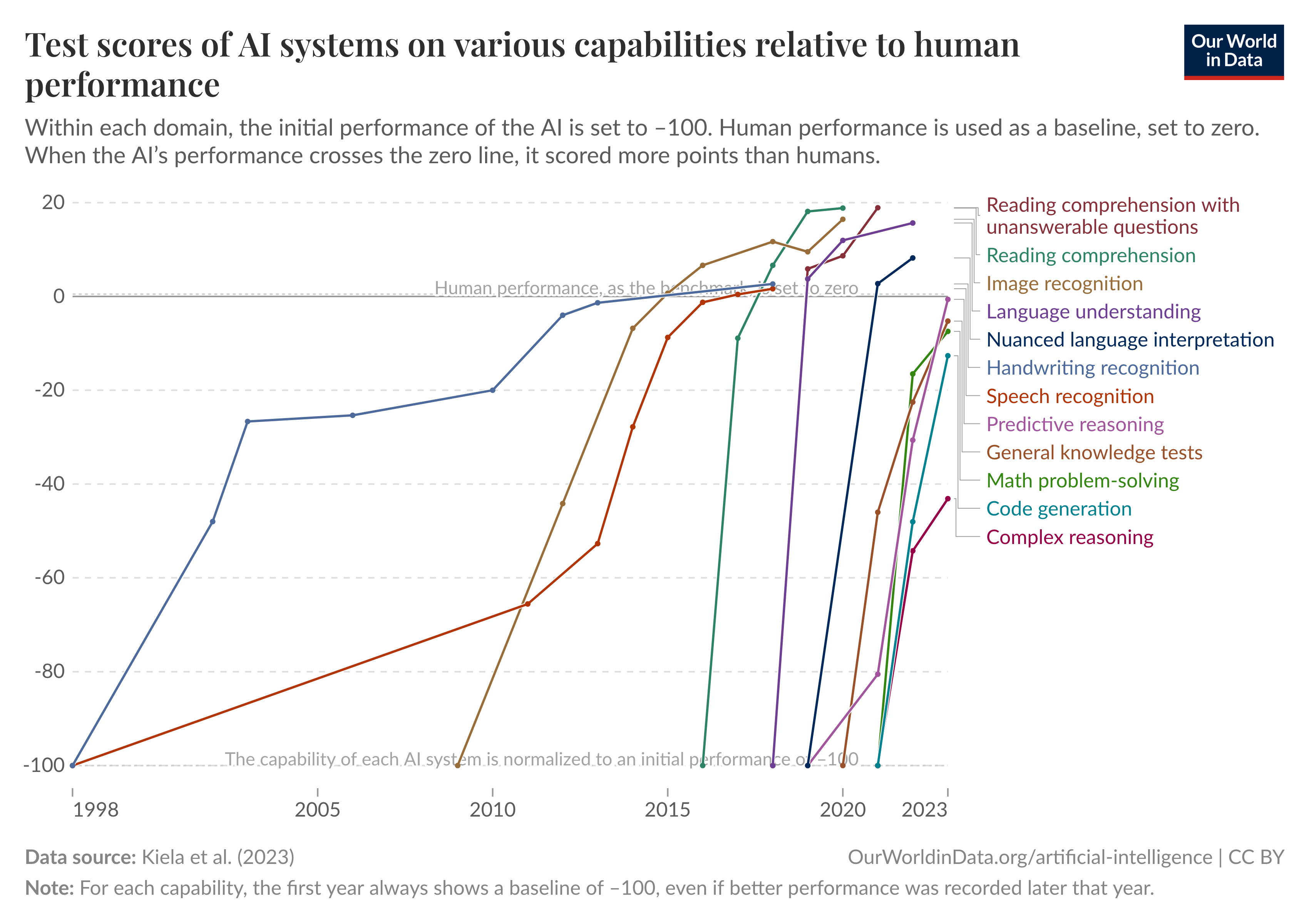
Khi một tiêu chuẩn được công bố, thời gian để giải quyết nó sẽ ngày càng ngắn hơn. Điều này có thể minh họa cho sự tiến bộ nhanh chóng của AI và tại sao các tiêu chuẩn AI đang "bão hòa" và bắt đầu vượt qua hiệu suất của con người trong nhiều nhiệm vụ khác nhau. (Our World in Data, 2023)
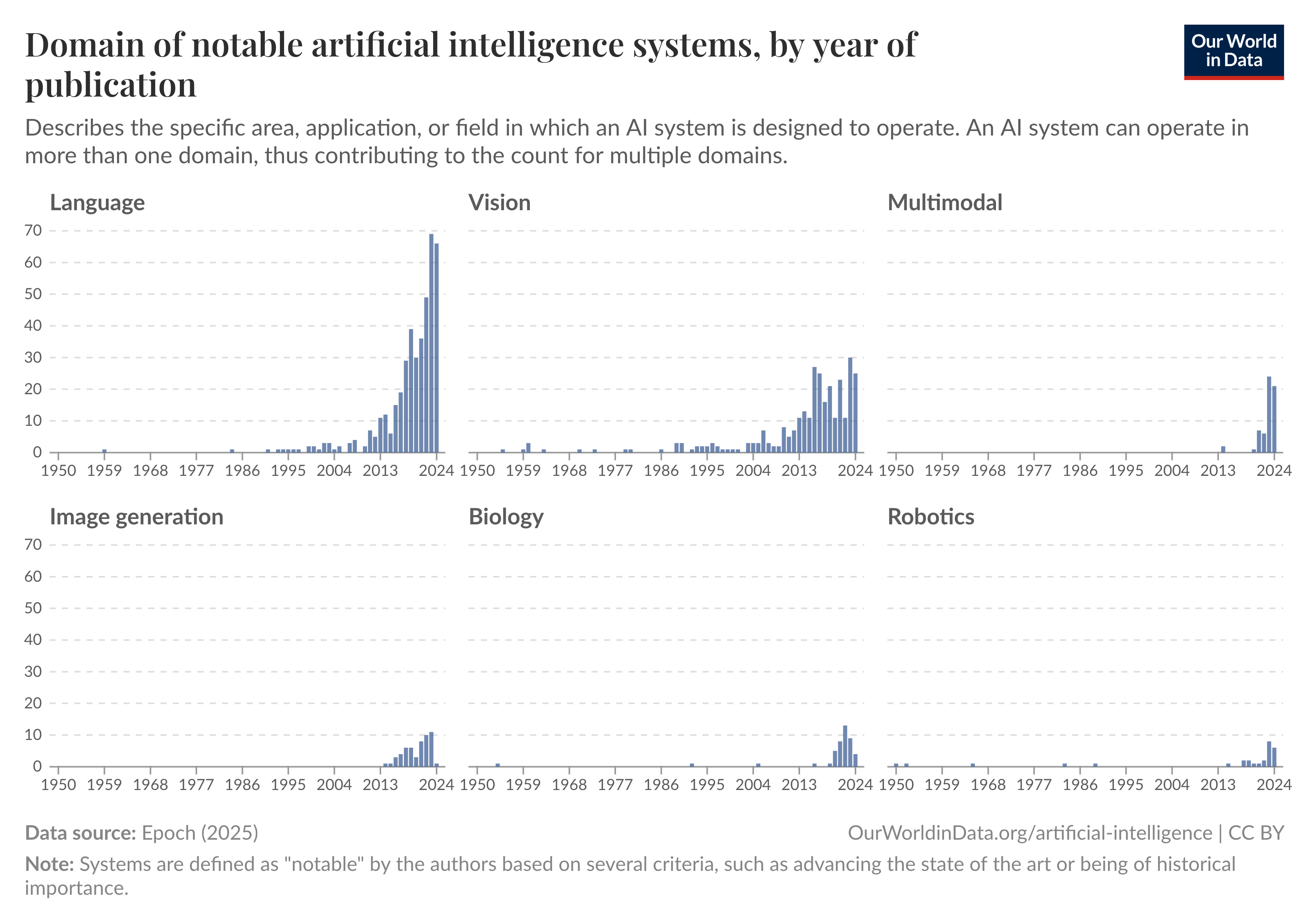
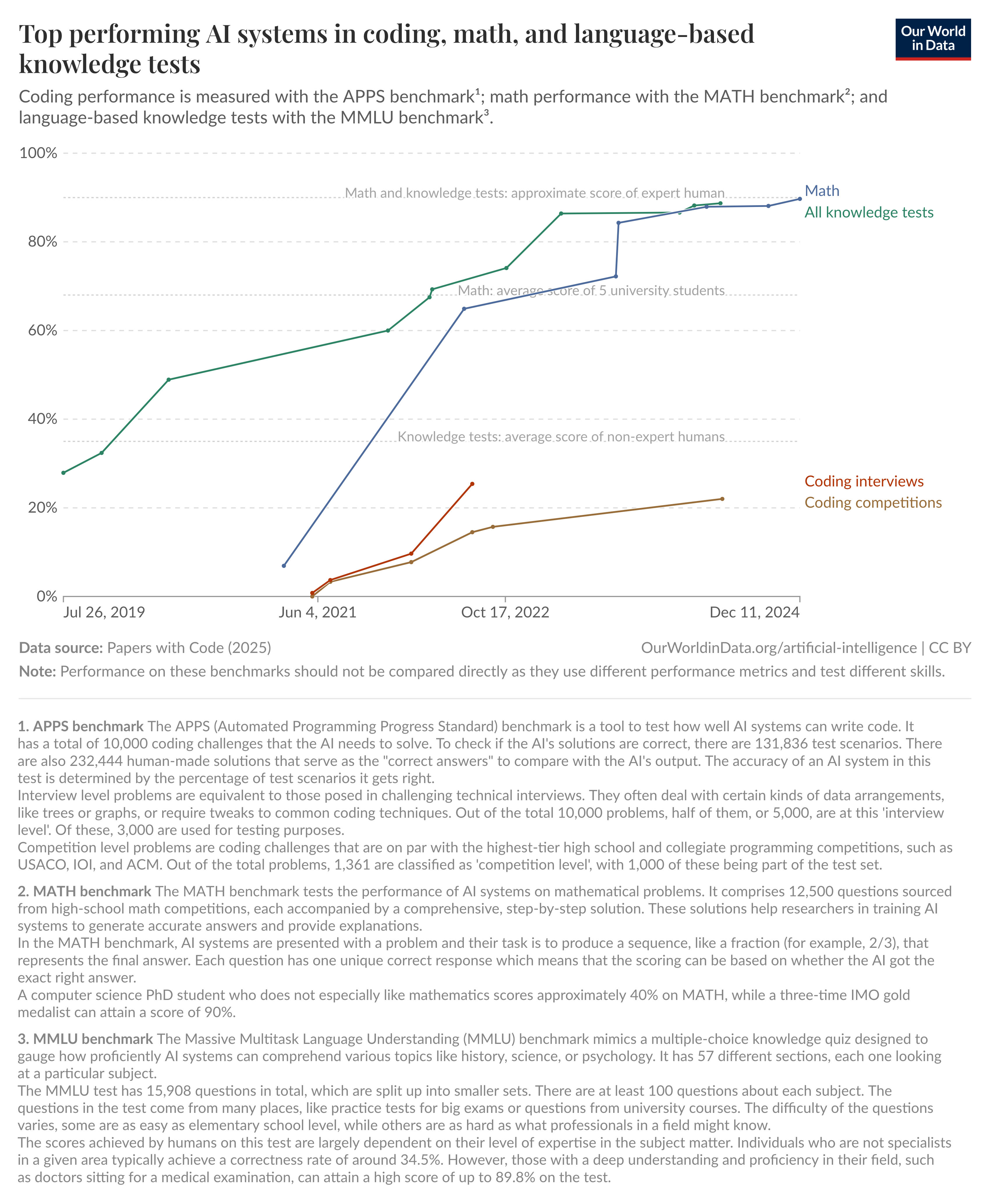
Các tác vụ dựa trên ngôn ngữ. Đã có những thay đổi mang tính cách mạng trong các tác vụ xoay quanh trình tự và ngôn ngữ, chủ yếu nhờ sự phát triển của các mô hình ngôn ngữ lớn (LLMs). Các mô hình ngôn ngữ ban đầu vào năm 2018 gặp khó khăn trong việc xây dựng các câu mạch lạc. Sự phát triển từ những mô hình này thành các năng lực tiên tiến của GPT-3 (Generative Pre-Trained Transformer) và ChatGPT trong vòng chưa đầy 5 năm thực sự đáng chú ý. Các mô hình này không chỉ thể hiện khả năng tạo văn bản tốt hơn mà còn có thể trả lời các câu hỏi phức tạp bằng lý luận tinh tế, hợp lý. Hiệu suất của chúng trong các nhiệm vụ trả lời câu hỏi khác nhau, bao gồm cả những nhiệm vụ đòi hỏi tư duy chiến lược, thực sự rất ấn tượng.
Trái ngược với GPT-3 và các phiên bản tiếp theo chỉ có văn bản, GPT-4 hỗ trợ đa phương thức: nó được huấn luyện trên cả văn bản và hình ảnh. Điều này có nghĩa là giờ đây nó không chỉ có thể tạo văn bản dựa trên hình ảnh mà còn có được một số năng lực khác. GPT-4 có cửa sổ ngữ cảnh được nâng cấp với tối đa 32k token (token ≈ từ). Giới hạn bộ nhớ ngắn hạn của một mô hình ngôn ngữ lớn (LLM) có thể được hiểu là khả năng của mô hình trong việc lưu trữ thông tin từ các token trước đó trong một cửa sổ ngữ cảnh nhất định. GPT-4 được đào tạo thông qua dự đoán token tiếp theo (học tự giám sát tự hồi quy - autoregressive self-supervised learning). Năm 2018, GPT-1 chỉ có thể đếm đến 10, trong khi đến năm 2024, GPT-4 có thể thực hiện các chức năng lập trình phức tạp và nhiều tác vụ khác.

Mở rộng quy mô. Điều đáng chú ý là GPT-4 được huấn luyện bằng các phương pháp gần giống với GPT-1, 2 và 3. Điểm khác biệt duy nhất nằm ở kích thước của mô hình và dữ liệu được cung cấp trong quá trình huấn luyện. Kích thước của mô hình đã tăng từ 1,5 tỷ tham số lên hàng trăm tỷ tham số, và các tập dữ liệu cũng trở nên lớn hơn và đa dạng hơn.
Chúng tôi đã quan sát thấy rằng chỉ riêng việc mở rộng quy mô đã góp phần nâng cao hiệu suất, bao gồm các cải tiến trong khả năng tạo ra các phản hồi phù hợp với ngữ cảnh và văn bản rất đa dạng trong nhiều lĩnh vực. Điều này cũng góp phần cải thiện chất lượng hiếu biết và độ mạch lạc của văn bản. Hầu hết những tiến bộ trong các phiên bản GPT đều đến từ việc tăng kích thước và sức mạnh tính toán của các mô hình, chứ không phải từ những thay đổi cơ bản trong kiến trúc hoặc quá trình huấn luyện.
Dưới đây là một số năng lực đã xuất hiện trong vài năm qua:


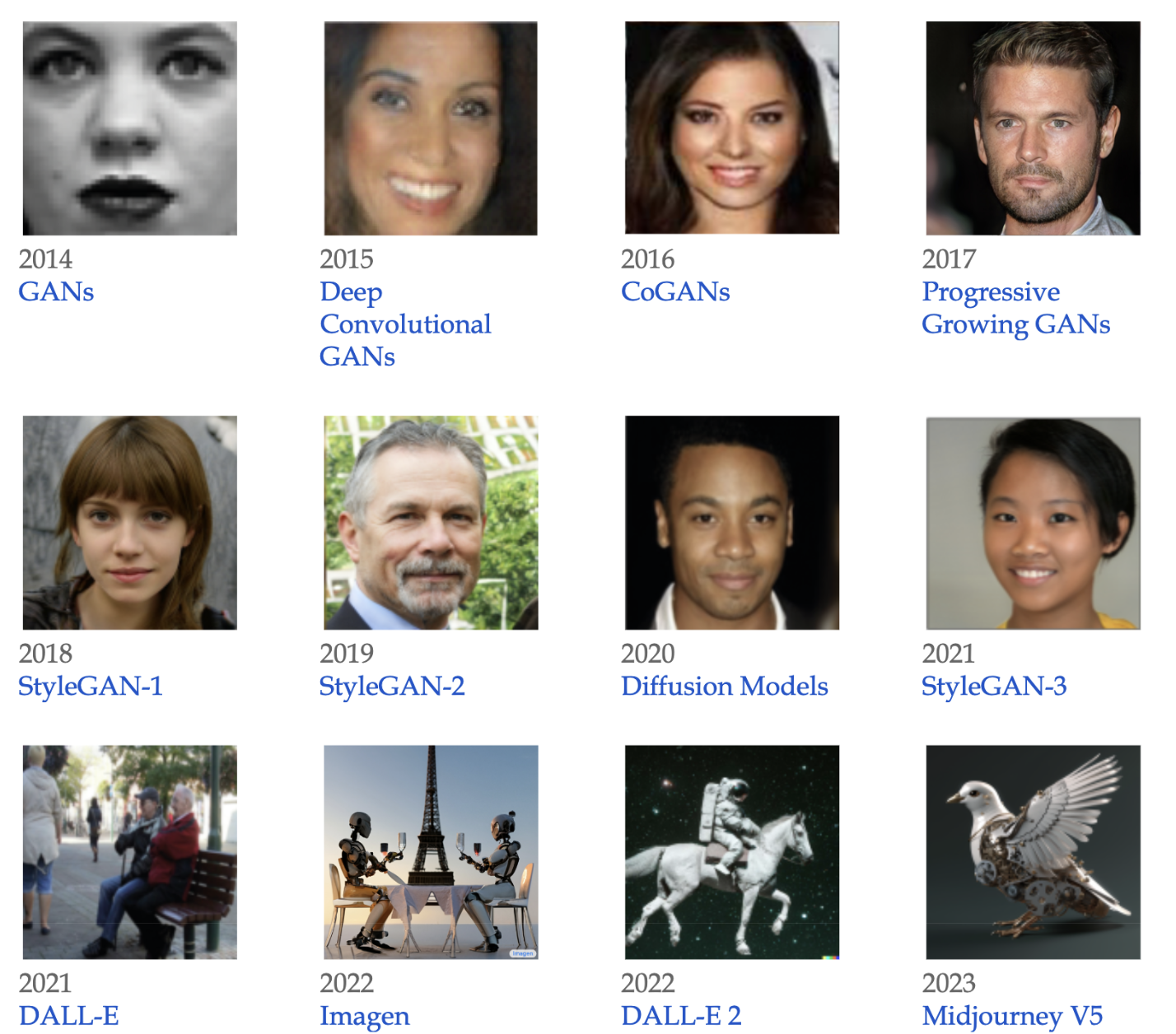
Bước tiến dài trong lĩnh vực tạo hình ảnh không chỉ nằm ở độ chính xác, mà còn ở khả năng xử lý các hình ảnh phức tạp trong thế giới thực. Khả năng này, đặc biệt là với sự ra đời của Mạng đối nghịch tạo sinh (GAN) vào năm 2014, đã cho thấy tốc độ phát triển đáng kinh ngạc. Chất lượng hình ảnh do AI tạo ra đã phát triển từ những hình ảnh đơn giản, mờ nhạt đến những cảnh rất chi tiết và sáng tạo, phần lớn là để đáp ứng các yêu cầu bằng ngôn ngữ phức tạp.

Tốc độ phát triển trong vòng một năm thực sự đáng kinh ngạc, thể hiện rõ qua sự cải tiến từ phiên bản V1 của mô hình tạo hình ảnh MidJourney vào đầu năm 2022 đến phiên bản V6 vào tháng 12 năm 2023.

Hệ thống AI đang ngày càng trở nên đa phương tiện. Điều này có nghĩa là chúng có thể xử lý hình ảnh, văn bản, âm thanh, thị giác và robot bằng cùng một mô hình. Do đó, chúng được huấn luyện bằng nhiều "chế độ" khác nhau và có thể dịch giữa các chế độ sau khi triển khai.
Phối hợp đa phương tiện. Một mô hình được gọi là phối hợp đa phương tiện khi đầu vào của mô hình ở một phương tiện (ví dụ: văn bản) và đầu ra ở một phương tiện khác (ví dụ: hình ảnh). Phần về thị giác máy tính cho thấy sự tiến bộ nhanh chóng trong phối hợp đa phương tiện từ năm 2014 đến năm 2020. Chúng ta đã đi từ các mô hình chuyển đổi văn bản thành hình ảnh chỉ có khả năng tạo ra hình ảnh khuôn mặt pixel đen trắng, đến các mô hình có khả năng tạo ra hình ảnh từ bất kỳ văn bản nào. Các ví dụ khác về phối hợp đa phương tiện bao gồm OpenAIs Whisper (Radford et al., 2022) có khả năng chuyển đổi giọng nói thành văn bản.
Đa phương tiện. Một mô hình được gọi là đa phương tiện khi cả đầu vào và đầu ra của mô hình có thể ở nhiều hơn một phương tiện. Ví dụ: âm thanh sang văn bản, video sang văn bản, văn bản sang hình ảnh, v.v…

Mô hình Flamingo 2022 của DeepMind có thể "nhanh chóng thích ứng với các nhiệm vụ hiểu hình ảnh/video khác nhau" và "cũng có khả năng đối thoại trực quan đa hình ảnh". (Alayrac et al., 2022) Tương tự, mô hình Gato 2022 của DeepMind được gọi là "Tác nhân tổng hợp". Đây là một mạng đơn với cùng trọng số có thể "chơi Atari, chú thích hình ảnh, trò chuyện, xếp khối bằng cánh tay robot thực và nhiều hơn nữa". (Reed et al., 2022) Tiếp tục xu hướng này, mô hình Google Gemini 2023 của DeepMind có thể được gọi là Mô hình đa phương tiện lớn (LMM). Bài báo mô tả Gemini là "đa phương tiện bẩm sinh" và tuyên bố có thể "kết hợp liền mạch các năng lực của mình trên các phương tiện (ví dụ: trích xuất thông tin và bố cục không gian từ bảng, biểu đồ hoặc hình vẽ) với năng lực suy luận mạnh mẽ của mô hình ngôn ngữ (ví dụ: hiệu suất tối tân trong toán học và mã hóa)" (Google, 2024)

Lĩnh vực công nghệ robot cũng đang phát triển song song với trí tuệ nhân tạo. Trong phần này, chúng tôi cung cấp một số ví dụ về sự kết hợp giữa hai lĩnh vực này, trong đó đề cập đến một số robot sử dụng kỹ thuật học máy để phát triển.


Những tiến bộ trong công nghệ robot. Đi đầu trong những tiến bộ về robot là PaLM-E, một mô hình đa năng với 562 tỷ tham số, tích hợp dữ liệu thị giác, ngôn ngữ và robot để điều khiển bộ điều khiển thời gian thực và xuất sắc trong các tác vụ ngôn ngữ liên quan đến suy luận địa lý (Driess et al., 2023).
Đồng thời, sự phát triển của các mô hình thị giác-ngôn ngữ đã dẫn đến những đột phá trong việc điều khiển robot với độ chính xác cao, với các mô hình như RT-2 thể hiện năng lực đáng kể trong thao tác đồ vật và suy luận đa phương tiện. RT-2 chứng minh tại sao chúng ta có thể sử dụng các phương pháp lấy cảm hứng từ việc tạo câu lệnh LLM (với khả năng chuỗi suy nghĩ) để học một mô hình độc lập có thể lập kế hoạch các chuỗi kỹ năng dài hạn và dự đoán hành động của robot (Brohan et al., 2023).
Mobile ALOHA là một ví dụ khác về việc kết hợp các kỹ thuật học máy hiện đại với công nghệ robot. Được huấn luyện bằng phương pháp nhân bản hành vi có giám sát, robot có thể tự động thực hiện các tác vụ phức tạp "như xào và phục vụ một con tôm, mở tủ tường hai cửa để cất nồi nấu ăn cồng kềnh, gọi và vào thang máy, và rửa sơ qua chảo đã sử dụng bằng vòi nước nhà bếp" (Fu et al., 2024). Những tiến bộ này không chỉ chứng tỏ sự tinh vi và khả năng ứng dụng ngày càng cao của các hệ thống robot, mà còn nêu bật tiềm năng phát triển đột phá hơn nữa của các công nghệ tự động.

Video giới thiệu một ví dụ về tình trạng hiện tại của công nghệ robot.
AI và board game. AI đã đạt được những tiến bộ liên tục trong lĩnh vực chơi game trong nhiều thập kỷ qua. Bắt đầu từ việc AI đánh bại nhà vô địch thế giới cờ vua vào năm 1997, Scrabble vào năm 2006 đến DeepMind’s AlphaGo vào năm 2016 (DeepMind, 2016), đủ giỏi để đánh bại nhà vô địch thế giới trong trò chơi Go, một trò chơi được cho là cực kỳ khó đối với AI. Chỉ trong vòng một năm, mô hình tiếp theo AlphaGo Zero, được đào tạo thông qua tự chơi, đã thành thạo nhiều trò chơi cờ vây, cờ vua và shogi, đạt đến trình độ vượt trội so với con người sau chưa đầy ba ngày đào tạo (Silver et al., 2017).
AI và trò chơi điện tử. Các nhà nghiên cứu bắt đầu áp dụng các kỹ thuật học máy trên các trò chơi Atari đơn giản vào năm 2013 (Mnih et al. 2013). Đến năm 2019, OpenAI Five đã đánh bại các nhà vô địch thế giới trong DOTA2 (OpenAI, 2019), trong khi cùng năm đó, AlphaStar của DeepMind đã đánh bại các game thủ chuyên nghiệp trong StarCraft II (DeepMind, 2019). Cả hai trò chơi này đều yêu cầu hàng ngàn hành động liên tiếp với số lượng hành động mỗi phút rất cao. Trong mô hình DeepMind MuZero năm 2020, được mô tả là "một bước tiến quan trọng trong việc theo đuổi các thuật toán đa năng" (DeepMind, 2020), có thể chơi các trò chơi Atari, cờ vây, cờ vua và shogi mà không cần được dạy luật chơi.
Trong những năm gần đây, năng lực của AI đã mở rộng sang các trò ch7i môi trường mở như Minecraft, thể hiện khả năng thực hiện các chuỗi hành động phức tạp. Trong các trò chơi chiến lược, Cicero của Meta đã thể hiện kỹ năng đàm phán chiến lược và lừa gạt phức tạp bằng ngôn ngữ tự nhiên trong trò chơi Diplomacy (Bakhtin et al., 2022).