
An toàn AI là một vấn đề xã hội-kỹ thuật đòi hỏi giải pháp xã hội-kỹ thuật. Đảm bảo an toàn AI cũng yêu cầu các tiếp cận hệ thống vững chắc. Những tiếp cận này bao gồm các cấu trúc quản trị, thực hành tổ chức và chuẩn mực văn hóa định hình sự phát triển và triển khai AI. Các biện pháp an toàn kỹ thuật có thể bị suy yếu do quản trị yếu kém, thực hành bảo mật kém trong các phòng thí nghiệm hoặc văn hóa ưu tiên tốc độ hơn thận trọng. Phần này xem xét các chiến lược nhằm tích hợp an toàn vào hệ sinh thái rộng lớn xung quanh AI.
Đối phó với các rủi ro hệ thống do AI gây ra không hề dễ dàng. Điều này đòi hỏi sự hợp tác liên ngành liên tục và giải quyết các trò chơi phối hợp phức tạp. Sự đa dạng trong trách nhiệm đối với vấn đề này khiến việc triển khai các giải pháp trở nên khó khăn.

Một minh họa về khung làm việc mà chúng tôi cho là đủ mạnh mẽ để quản lý rủi ro. Rủi ro từ AI quá đa dạng và phức tạp. Để đối phó với những rủi ro này, chúng ta cần một khung làm việc linh hoạt có thể thích ứng và phát triển cùng với sự tiến bộ của AI.
Hãy giữ vững nguyên tắc trong thời điểm mà phần lớn thế giới đang trở nên phân mảnh, và không chỉ xây dựng bất cứ thứ gì - mà chúng ta muốn xây dựng những thứ cụ thể giúp thế giới an toàn và tốt đẹp hơn.
Tăng tốc phòng thủ (d/acc) là một chiến lược ưu tiên các công nghệ củng cố khả năng phòng thủ và sự bền bỉ xã hội trước các rủi ro từ AI. Tăng tốc phòng thủ, hay d/acc, xuất hiện như một chiến lược vào năm 2023, là con đường trung dung giữa việc tăng tốc không giới hạn (tăng tốc chủ nghĩa hiệu quả (e/acc)) và những người bi quan công nghệ/bi quan (Buterin, 2023; Buterin, 2025). Thay vì chỉ dựa vào việc hạn chế truy cập vào các năng lực tiềm ẩn nguy hiểm, d/acc đề xuất chỉ tăng tốc các công nghệ vốn có xu hướng ưu tiên phòng thủ hơn tấn công, từ đó giúp xã hội trở nên bền vững hơn trước các mối đe dọa đa dạng, bao gồm việc lợi dụng sai mục đích AI bởi con người hoặc hành vi mất căn chỉnh của chính AI. D/acc có thể được hiểu thông qua câu hỏi - nếu AI chiếm quyền kiểm soát thế giới (hoặc làm suy yếu con người), nó sẽ làm điều đó như thế nào?

Một minh họa về các lĩnh vực chúng ta có thể tập trung vào trong triết lý d/acc để ưu tiên công nghệ phòng thủ (Buterin, 2023).
Một ứng dụng quan trọng là sử dụng AI để nâng cao an ninh mạng. AI mạnh mẽ có thể tự động hóa phát hiện lỗ hổng bảo mật, giám sát hệ thống để phát hiện xâm nhập, quản lý quyền truy cập chi tiết hiệu quả hơn con người, hoặc thay thế nhân viên con người trong các tác vụ quan trọng về an ninh (Shlegeris, 2024). Mặc dù các mô hình hiện tại có thể chưa đủ tin cậy, tiềm năng của AI trong việc tăng cường đáng kể khả năng phòng thủ mạng chống lại cả các cuộc tấn công truyền thống và do AI điều khiển là rất lớn (Jade Hill, 2024; Schlegeris, 2024) đã nêu ra bốn chiến lược hứa hẹn để sử dụng AI nâng cao an ninh:
Các phương pháp này có thể giảm đáng kể các mối đe dọa từ bên trong và rủi ro rò rỉ dữ liệu, tiềm năng làm cho an ninh máy tính trở nên "dễ dàng hơn nhiều" khi AI mạnh mẽ trở nên khả dụng, ngay cả khi vẫn còn nhiều nghi ngờ về độ tin cậy của các kỹ thuật này.
D/acc đại diện cho ba nguyên tắc liên kết: phòng thủ, phi tập trung và phát triển công nghệ khác biệt. Chữ "d" trong d/acc có nghĩa là:

Các cơ chế mà sự phát triển công nghệ khác biệt có thể giảm thiểu tầm ảnh hưởng tiêu cực đối với xã hội (Buterin, 2023).
Hiệu quả của d/acc phụ thuộc vào việc duy trì sự cân bằng thuận lợi giữa tấn công và phòng thủ. Khả năng áp dụng d/acc như một chiến lược phụ thuộc vào việc liệu các công nghệ phòng thủ có thể vượt trội hơn các năng lực tấn công trên các lĩnh vực hay không. Các tiền lệ lịch sử là đa dạng - một số lĩnh vực như an ninh mạng truyền thống thường ủng hộ những người phòng thủ có thể vá các lỗ hổng, trong khi các lĩnh vực khác như an toàn sinh học truyền thống ủng hộ những kẻ tấn công cần ít tài nguyên hơn để tạo ra mối đe dọa so với những người phòng thủ cần để đối phó với chúng. Thách thức chính trong việc triển khai d/acc nằm ở việc xác định và hỗ trợ các công nghệ có thể thay đổi cân bằng này theo hướng phòng thủ (Bernardi, 2024; Buterin, 2023).
D/acc bổ sung chứ không thay thế các phương pháp an toàn khác. Khác với các khung khổ cạnh tranh có thể coi các hạn chế và biện pháp bảo vệ là rào cản cho sự tiến bộ, d/acc công nhận giá trị của chúng đồng thời giải quyết các hạn chế của chúng. Các biện pháp bảo vệ mô hình vẫn là hàng phòng thủ đầu tiên thiết yếu, nhưng d/acc xây dựng các lớp an toàn bổ sung khi các biện pháp bảo vệ đó thất bại hoặc bị vượt qua. Tương tự, các khung khổ quản trị cung cấp sự giám sát cần thiết, nhưng d/acc giảm sự phụ thuộc vào quy định hoàn hảo bằng cách xây dựng khả năng phục hồi kỹ thuật hoạt động ngay cả trong các khoảng trống quản trị.
Các tiếp cận quản trị và chính sách có thể thực hiện được đối với d/acc. Các can thiệp chính sách có thể giúp tạo ra các khung khổ có cấu trúc cho việc tăng tốc phòng thủ. Một số ví dụ về công việc trong quản trị hỗ trợ triết lý d/acc bao gồm:
Các tiếp cận công nghệ và nghiên cứu có thể thực hiện được để d/acc. Chúng ta có thể thúc đẩy tiến bộ công nghệ một cách có chọn lọc trong nhiều lĩnh vực khác nhau để ưu tiên phòng thủ trước các rủi ro thảm họa. Dưới đây là một vài ví dụ:

Mô hình mở rộng minh họa cách nhiều loại và lớp công nghệ phòng thủ khác nhau có thể tương tác (Buterin, 2025)
An toàn AI hiệu quả cũng phụ thuộc rất nhiều vào các thực hành và cấu trúc nội bộ trong các tổ chức phát triển AI. Tai nạn khó tránh khỏi, ngay cả khi cơ cấu khuyến khích và quản trị cố gắng đảm bảo không có vấn đề gì xảy ra. Ví dụ, ngay cả ngày nay, vẫn còn xảy ra tai nạn trong ngành hàng không vũ trụ.
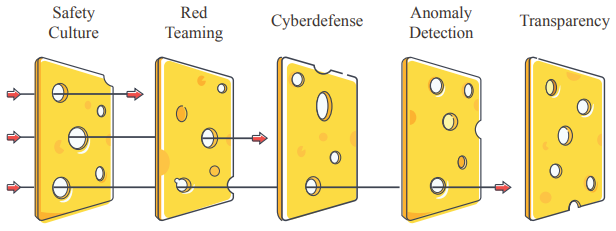
Mô hình phô mai Thụy Sĩ cho thấy cách các yếu tố kỹ thuật có thể cải thiện an toàn tổ chức. Nhiều lớp phòng thủ bù đắp cho những điểm yếu riêng lẻ của nhau, dẫn đến mức độ rủi ro tổng thể thấp (Hendrycks et al., 2023).
Để giải quyết những vấn đề này, mô hình phô mai Thụy Sĩ có thể hiệu quả — không có giải pháp đơn lẻ nào đủ, nhưng tiếp cận theo lớp có thể giảm đáng kể rủi ro. Mô hình phô mai Thụy Sĩ là khái niệm từ quản lý rủi ro, được sử dụng rộng rãi trong các ngành như y tế và hàng không. Mỗi lớp đại diện cho một biện pháp an toàn, và mặc dù từng lớp có thể có điểm yếu, nhưng khi kết hợp lại, chúng tạo thành một rào cản mạnh mẽ chống lại các mối đe dọa. Các tổ chức cũng nên tuân thủ các nguyên tắc thiết kế an toàn (Hendrycks & Mazeika, 2022), như phòng thủ đa lớp và dự phòng, để đảm bảo có biện pháp dự phòng cho mọi biện pháp an toàn, cùng các yếu tố khác.
Nhiều giải pháp có thể được đề xuất để giảm thiểu những rủi ro này, dù không có giải pháp nào là hoàn hảo. Bước đầu tiên có thể là thuê các đội mô phỏng tấn công có chủ đích (red teams) để xác định nguy cơ và cải thiện an toàn hệ thống. Đây là điều OpenAI đã làm với METR để đánh giá GPT-4. Tuy nhiên, các phòng thí nghiệm AGI cũng cần có đội ngũ kiểm toán nội bộ cho quản lý rủi ro. Giống như các ngân hàng có đội ngũ quản lý rủi ro, đội ngũ này cần tham gia vào quá trình ra quyết định, và các quyết định quan trọng nên có sự tham gia của giám đốc quản lý rủi ro để đảm bảo trách nhiệm của ban lãnh đạo. Một trong những nhiệm vụ của đội ngũ quản lý rủi ro có thể là thiết kế các kế hoạch sẵn có để quản lý an ninh và sự cố.
Hạn chế của các tiếp cận hệ thống. Phương pháp phòng thủ đa lớp có thể vẫn thất bại trước các mối đe dọa mới mẻ hoặc đối thủ quyết tâm, đặc biệt trong trường hợp của các hệ thống trí tuệ nhân tạo tiên tiến (ASIs). Tương tự, các kịch bản xói mòn năng lực của con người, nơi năng lực bị xói mòn dần qua các thay đổi kinh tế hoặc văn hóa do AI thúc đẩy, có thể không được các khung quản trị hiện tại tập trung vào các tác hại hoặc năng lực cụ thể giải quyết đầy đủ.
Cuộc đua phát triển trí tuệ nhân tạo (AI) ngày càng mạnh mẽ, tương tự như cuộc chạy đua vũ trang hạt nhân trong thời kỳ Chiến tranh Lạnh, đại diện cho sự đánh đổi giữa an toàn và lợi thế cạnh tranh mà các quốc gia và tập đoàn tìm kiếm để giành quyền lực và ảnh hưởng. Động lực cạnh tranh này làm gia tăng rủi ro toàn cầu. Để giảm thiểu vấn đề này, chúng ta có thể cố gắng tác động vào nguồn gốc của nó, tức là tái thiết kế các động lực kinh tế để ưu tiên an toàn lâu dài hơn lợi ích ngắn hạn. Điều này chủ yếu có thể thực hiện thông qua quản trị quốc tế.
Quản trị AI hiệu quả nhằm đạt được hai mục tiêu chính:
Thiết kế các cơ chế khuyến khích cấp cao hơn
Đồng bộ hóa các cơ chế khuyến khích kinh tế với mục tiêu an toàn là thách thức chính. Hiện nay, áp lực thương mại mạnh mẽ có thể khuyến khích phát triển năng lực nhanh chóng, có thể ảnh hưởng đến nghiên cứu an toàn hoặc triển khai thận trọng. Cần có các cơ chế thưởng cho an toàn hoặc phạt cho hành vi liều lĩnh để tránh các tác động tiêu cực:
^: Ví dụ, trong ngành dược phẩm, các công ty đôi khi ký kết các thỏa thuận hợp tác phát triển và chia sẻ lợi nhuận để chia sẻ rủi ro và lợi ích khi đưa một loại thuốc mới ra thị trường. Ví dụ, vào năm 2014, Pfizer và Merck đã ký kết một liên minh toàn cầu để hợp tác phát triển và thương mại hóa một kháng thể chống PD-L1 cho điều trị nhiều loại ung thư.
Các cơ chế quản trị AI quốc tế được đề xuất
Một số cơ chế đã được đề xuất để thiết lập ranh giới và quy tắc rõ ràng cho phát triển AI trên phạm vi quốc tế. Điều này bao gồm việc áp dụng các lệnh cấm tạm thời đối với các hệ thống AI có rủi ro cao, thực thi các quy định pháp lý như Luật AI của EU, và thiết lập các "Ranh giới Đỏ" được quốc tế đồng thuận để cấm các năng lực AI nguy hiểm cụ thể, như tự nhân bản hoặc hỗ trợ trong việc tạo ra vũ khí hủy diệt hàng loạt. Các cuộc đối thoại IDAIS nhằm xây dựng sự đồng thuận về các "đường đỏ" này, nhấn mạnh tính rõ ràng và phổ quát là các đặc điểm quan trọng để đảm bảo hiệu quả, với các vi phạm có thể kích hoạt các phản ứng quốc tế đã được thỏa thuận trước.
Các tiếp cận có điều kiện và việc thành lập các cơ quan quốc tế chuyên trách đại diện cho một chiến lược quan trọng khác. "Cam kết Nếu-Thì" liên quan đến việc các nhà phát triển hoặc quốc gia đồng ý thực hiện các biện pháp an toàn cụ thể nếu năng lực AI đạt đến các ngưỡng đã được xác định trước, cho phép chuẩn bị mà không cản trở sự phát triển quá sớm, như được minh họa bởi Hiệp ước An toàn AI Có Điều kiện được đề xuất. Hơn nữa, có các đề xuất về việc thành lập các cơ quan quốc tế mới, có thể mô hình theo Cơ quan Năng lượng Nguyên tử Quốc tế (IAEA), để giám sát sự phát triển của AI, xác minh tuân thủ các thỏa thuận, thúc đẩy nghiên cứu an toàn và có thể tập trung hoặc kiểm soát sự phát triển và phân phối AI có rủi ro cao nhất.
Các chế độ quản trị cụ thể và cơ cấu hỗ trợ cũng đang được xem xét để nâng cao sự phối hợp quốc tế. Do tính chất toàn cầu của AI, các cơ chế như quản trị sức mạnh điện toán quốc tế nhằm giám sát và kiểm soát chuỗi cung ứng cho chip AI và cơ sở hạ tầng đào tạo quy mô lớn, mặc dù tính khả thi kỹ thuật và hợp tác quốc tế vẫn là thách thức. Các đề xuất khác bao gồm thành lập một cơ quan nghiên cứu an toàn AI quốc tế quy mô lớn tương tự như CERN, có thể tập trung nghiên cứu rủi ro cao hoặc thiết lập tiêu chuẩn toàn cầu, và tăng cường bảo vệ người tố giác thông qua các thỏa thuận quốc tế để khuyến khích báo cáo các vấn đề an toàn trong ngành AI.
Để biết thêm thông tin về các chủ đề này, vui lòng đọc chương tiếp theo về quản trị AI.
Trong lịch sử, lĩnh vực an toàn AI chủ yếu tập trung vào nghiên cứu kỹ thuật, một phần chịu ảnh hưởng bởi quan điểm của Eliezer Yudkowsky rằng "Chính trị là kẻ giết chết trí tuệ." (Yudkowsky, 2007) Trong nhiều năm, lĩnh vực này cho rằng việc tham gia vào chính sách và chính trị là vô hiệu hoặc thậm chí phản tác dụng so với việc trực tiếp giải quyết vấn đề tương thích kỹ thuật, dẫn đến nhiều nhà nghiên cứu sớm quan tâm đến AGI ưu tiên các giải pháp kỹ thuật hơn nỗ lực quản trị. Điều đáng ngạc nhiên là ban đầu, việc thảo luận công khai về những rủi ro này thậm chí còn bị khuyến cáo tránh để không kích động cuộc đua và không thu hút những người có "kiến thức hạn chế" vào cộng đồng.
Tuy nhiên, đến năm 2023, ChatGPT được công bố, trở nên viral, và quản trị AI đã thu hút sự chú ý đáng kể như một chiến lược tiềm năng để giảm thiểu rủi ro AGI. Sự thay đổi này xảy ra khi việc tham gia với các nhà hoạch định chính sách dường như mang lại một số kết quả, khiến quản trị trở nên khả năng giải quyết hơn so với trước đây (Akash, 2023). Sau đó, các lá thư mở có ảnh hưởng được công bố (FLI, CAIS) và thay đổi "cửa sổ Overton". Hệ quả là các tổ chức có ảnh hưởng như 80,000 Hours đã điều chỉnh các khuyến nghị nghề nghiệp của mình, nhấn mạnh các vai trò chính sách và chiến lược AI, nay được ưu tiên hơn nghiên cứu sự đồng nhất kỹ thuật, như những ưu tiên hàng đầu cho tầm ảnh hưởng (80,000 Hours, 2023).
Tuy nhiên, "cửa sổ Overton" cho các biện pháp an toàn AI quốc tế nghiêm ngặt dường như đang thu hẹp. Mặc dù các tuyên bố và nỗ lực ban đầu của các tổ chức như Viện Tương lai Cuộc sống và Trung tâm An toàn AI đã thành công trong việc mở rộng cuộc thảo luận công khai và chính trị về rủi ro từ AI, nhưng các diễn biến sau đó, bao gồm các hội nghị quốc tế được coi là yếu về an toàn và sự thay đổi trong lãnh đạo chính trị (như việc Donald Trump đắc cử), đã đặt ra nghi ngờ về khả năng đạt được sự phối hợp quốc tế mạnh mẽ (Zvi, 2025). Điều này đã khiến một số người trong lĩnh vực quản trị AI tin rằng một "thảm hoạ cảnh cáo" – một minh chứng rõ ràng về nguy cơ của AI – có thể cần thiết để thúc đẩy hành động quyết liệt, mặc dù có sự hoài nghi về việc liệu một sự kiện thuyết phục như vậy có thể xảy ra trước khi quá muộn hay không (Segerie, 2024).
Các quy định hiện có và đề xuất đều gặp phải những hạn chế đáng kể và tiềm ẩn hệ quả tiêu cực. Chẳng hạn, các nỗ lực lập pháp nổi bật như Đạo luật AI của EU, mặc dù mang tính đột phá ở một số khía cạnh, vẫn còn những lỗ hổng đáng kể (Miles, 2025); Quy tắc Thực hành của nó có những hạn chế và chính Đạo luật này có thể không đủ để bao quát các mô hình được triển khai ngoài châu Âu, các triển khai nội bộ thuần túy cho nghiên cứu hoặc các ứng dụng quân sự. Một vấn đề quan trọng là tiềm năng các phòng thí nghiệm AI tiên tiến tham gia vào các cuộc đua phát triển bí mật, vượt qua sự giám sát – một kịch bản có thể được tạo điều kiện bởi các thay đổi chính sách như việc hủy bỏ các lệnh hành pháp yêu cầu chính phủ báo cáo về đánh giá các mô hình tiên tiến (Kokotajlo, 2025).
Ngoài ra, còn có những lo ngại cơ bản rằng các cấu trúc quản trị có năng lực kiểm soát AGI có thể chính nó tạo ra rủi ro, tiềm ẩn nguy cơ cho phép kiểm soát toàn trị.
Một quan điểm hoài nghi sâu sắc cho rằng phần lớn câu chuyện về tiến bộ AI hiện nay và các hoạt động quy định có thể mang tính biểu diễn hoặc "giả tạo". Mô hình "hoàn toàn hoài nghi" này cho rằng các phòng thí nghiệm AI lớn có thể đang phóng đại tiến bộ của họ trong việc phát triển AGI để duy trì niềm tin của nhà đầu tư và tạo ra sự hào hứng, có thể che giấu tiến bộ thực tế chậm chạp hoặc sự trì trệ trong các năng lực cốt lõi (johnswentworth, 2025). Song song đó, quan điểm này cho rằng các nhà hoạt động và nhà vận động chính sách về AI có thể ưu tiên việc xây dựng mạng lưới và địa vị trong các vòng tròn chính sách hơn là tạo ra các quy định thực sự hiệu quả, dẫn đến các biện pháp tập trung vào các chỉ số dễ dàng nhắm mục tiêu nhưng có thể bề ngoài (như ngưỡng khả năng điện toán) thay vì giải quyết các rủi ro cơ bản (johnswentworth, 2025). Quan điểm này ngụ ý một động lực mà cả các phòng thí nghiệm và nhà hoạt động vô tình củng cố một câu chuyện về những đột phá AI sắp xảy ra và có thể kiểm soát được, có thể tách biệt với thực tế cơ bản (johnswentworth, 2025).
Tuy nhiên, quan điểm "giả tạo" này bị tranh cãi. Những người chỉ trích quan điểm bi quan cho rằng các đề xuất quy định cụ thể, như SB 1047, vẫn chứa đựng các yếu tố tiềm năng có giá trị (ví dụ: yêu cầu năng lực tắt hệ thống, các biện pháp bảo vệ và theo dõi các đợt đào tạo quy mô lớn), ngay cả khi tầm ảnh hưởng tổng thể của chúng bị tranh cãi hoặc cuối cùng bị hạn chế (Charbel-Raphaël, 2025; johnswentworth, 2025). Người ta thừa nhận rằng các cơ quan quản lý hoạt động dưới những hạn chế thực tế, bao gồm ảnh hưởng đáng kể của hoạt động vận động hành lang của Big Tech, điều này có thể ngăn cản việc cấm các công nghệ mà không có bằng chứng rõ ràng về rủi ro không thể chấp nhận được. Hơn nữa, hiện tượng "tuân thủ hiệu suất" hoặc "tuân thủ kịch bản" được công nhận, nhưng người ta lập luận rằng việc tham gia vào các quy trình không hoàn hảo này vẫn là cần thiết, và một số bước lập pháp, như Luật AI của EU đề cập rõ ràng đến "sự phù hợp với ý định của con người", đại diện cho tiến bộ có ý nghĩa tiềm năng (Katalina Hernandez, 2025).
Quy định về AI có thể vô tình tăng rủi ro hiện sinh thông qua nhiều con đường (1a3orn, 2023). Các quy định có thể hướng nỗ lực an toàn vào các vấn đề tuân thủ lỗi thời hoặc ít liên quan, làm phân tán sự chú ý khỏi các rủi ro mới nổi quan trọng hơn (Quy định sai hướng); các quy trình quan liêu thường ủng hộ các doanh nghiệp lớn, đã estable, có thể cản trở các nỗ lực nghiên cứu an toàn sáng tạo của các doanh nghiệp nhỏ hơn; các quy định quốc gia quá nghiêm ngặt có thể đẩy phát triển AI sang các cá nhân quốc tế ít quan tâm đến an toàn hơn, làm suy yếu ảnh hưởng của cơ quan quản lý ban đầu (Làm suy yếu các quốc gia quản lý); và các quy định, đặc biệt là những quy định hạn chế mô hình nguồn mở hoặc đặt ra chi phí tuân thủ cao, có thể tập trung quyền lực vào tay các công ty lớn nhất có khả năng đẩy mạnh công nghệ, có thể kìm hãm các tiếp cận an toàn thay thế và đẩy nhanh rủi ro (Tăng cường quyền lực cho các doanh nghiệp thống trị). Tuy nhiên, sự tồn tại của những lập luận này không đủ để kết luận rằng quy định về AI là tiêu cực, đây chủ yếu là lời nhắc nhở rằng chúng ta cần thận trọng trong việc quy định. Chi tiết mới là vấn đề.
Quản lý rủi ro trong an toàn AI dựa trên các thực tiễn đã được thiết lập từ các ngành khác. Quản lý rủi ro không phải là đặc thù của an toàn AI—nó có nguồn gốc từ nhiều lĩnh vực bao gồm hàng không vũ trụ, năng lượng hạt nhân và dịch vụ tài chính. Mỗi lĩnh vực này đã phát triển các phương pháp phức tạp để xác định, phân tích và giảm thiểu các tác hại tiềm ẩn. Ngành năng lượng hạt nhân, ví dụ, áp dụng các chiến lược phòng thủ đa lớp với nhiều hệ thống an toàn dự phòng, trong khi hàng không sử dụng các quy trình chứng nhận nghiêm ngặt và giám sát liên tục. Quản lý rủi ro tài chính tập trung vào thử nghiệm stress và dự trữ vốn để ngăn chặn sự sụp đổ hệ thống. Các khung khổ đã được thiết lập này cung cấp tiền lệ quý giá cho an toàn AI, tuy nhiên, các đặc điểm độc đáo của hệ thống AI—như khả năng ra quyết định tự chủ, mở rộng quy mô nhanh chóng và hành vi phát sinh—yêu cầu điều chỉnh các phương pháp quản lý rủi ro truyền thống.
Nội dung của hộp này được sao chép từ bài viết của Simeon Campos (Campos et al, 2024).
Mục tiêu chính của quy trình làm việc khung quản lý rủi ro này là đảm bảo rằng rủi ro luôn duy trì ở mức không thể chấp nhận được thông qua quy trình sau:
Các ngưỡng này tuân theo mối quan hệ ba chiều: đối với bất kỳ mức độ chịu đựng rủi ro và ngưỡng KRI nào, luôn tồn tại một ngưỡng KCI tối thiểu phải đạt được để duy trì rủi ro dưới mức chịu đựng.
Mức độ chấp nhận rủi ro khác biệt với ngưỡng năng lực và có thể được định nghĩa theo hai cách:
Khung làm việc tận dụng chu kỳ sống của hệ thống AI để giảm bớt gánh nặng cho nhà phát triển AI sau khi hoàn thành đào tạo mô hình:
Về quản trị rủi ro, khung khổ mô tả một cấu trúc tổ chức được thiết kế để đảm bảo việc tính toán rủi ro một cách tương xứng trong quá trình ra quyết định. Nó bao gồm:

Hình từ Quản lý rủi ro tiên tiến của SaferAI: “Khung quản lý rủi ro được giới thiệu trong bài viết này cho phép người dùng triển khai bốn chức năng quản lý rủi ro chính: xác định rủi ro (xác định rủi ro), xác định mức độ rủi ro chấp nhận được và phân tích các rủi ro đã xác định (phân tích và đánh giá rủi ro), giảm thiểu rủi ro để duy trì mức độ chấp nhận được (xử lý rủi ro), và đảm bảo rằng tổ chức có cấu trúc tổ chức phù hợp để thực hiện quy trình này một cách nhất quán và nghiêm ngặt (quản trị rủi ro).” - (Campos et al, 2024)

https://ratings.safer-ai.org/, ảnh chụp màn hình từ SaferAI.
Việc quản lý các rủi ro có thể xảy ra trước khi triển khai cũng rất quan trọng. Thỉnh thoảng, điều này cũng có thể là dấu hiệu của lỗi hoặc sự cố (Ziegler et al., 2020). Để tránh sự cố trong quá trình đào tạo, việc đào tạo cũng cần được thực hiện một cách có trách nhiệm. Đánh giá mô hình cho các rủi ro cực đoan, do các nhà nghiên cứu từ OpenAI, Anthropic và DeepMind biên soạn, đưa ra một chiến lược cơ bản tốt về những việc cần làm trước khi đào tạo, trong quá trình đào tạo, trước khi triển khai và sau khi triển khai. (Shevlane et al., 2023)

Quy trình đào tạo và triển khai mô hình một cách có trách nhiệm. (Shevlane et al., 2023)
Việc triển khai các quy trình quản lý rủi ro có cấu trúc là điều cần thiết. Điều này bao gồm việc xác định, đánh giá, giảm thiểu và theo dõi rủi ro trong suốt vòng đời của AI. Các khung khổ như NIST AI RMF cung cấp hướng dẫn. Mô hình "Ba tuyến phòng thủ", được lấy cảm hứng từ các ngành khác (quản lý vận hành, chức năng rủi ro/tuân thủ, kiểm toán nội bộ), cung cấp một cấu trúc để phân công trách nhiệm quản lý rủi ro trong tổ chức (Jonas Schuett, 2022). Cách tiếp cận "An toàn tích cực" đề xuất yêu cầu các nhà phát triển chủ động xây dựng một trường hợp dựa trên bằng chứng chứng minh tính an toàn so với các ngưỡng rủi ro đã được xác định trước, bao gồm cả bằng chứng kỹ thuật và vận hành (Akash R. Wasil et al., 2024).
Tại sao việc xây dựng an toàn AI lại được hưởng lợi từ một văn hóa an toàn chung?
An toàn AI là một vấn đề xã hội-kỹ thuật đòi hỏi giải pháp xã hội-kỹ thuật. Do đó, việc giải quyết những thách thức này không thể chỉ dựa vào giải pháp kỹ thuật. Văn hóa an toàn là yếu tố quan trọng vì nhiều lý do. Ở mức cơ bản nhất, nó đảm bảo rằng các biện pháp an toàn được xem xét nghiêm túc. Điều này quan trọng vì sự coi thường an toàn có thể dẫn đến việc vi phạm quy định hoặc làm cho quy định trở nên vô nghĩa, như thường thấy khi các công ty không quan tâm đến an toàn phải đối mặt với kiểm toán (Manheim, 2023).
Thách thức trong việc áp dụng rộng rãi các giải pháp kỹ thuật trong ngành. Đề xuất một giải pháp kỹ thuật chỉ là bước đầu tiên trong việc giải quyết vấn đề an toàn. Một giải pháp kỹ thuật hoặc bộ quy trình cần được tất cả thành viên trong tổ chức tiếp thu. Khi an toàn được xem là mục tiêu chính thay vì rào cản, các tổ chức thường thể hiện cam kết lãnh đạo về an toàn, trách nhiệm cá nhân đối với an toàn và giao tiếp mở về các rủi ro và vấn đề tiềm ẩn (Hendrycks et al., 2023).
Đạt được tiêu chuẩn của ngành hàng không vũ trụ. Trong ngành hàng không vũ trụ, các quy định nghiêm ngặt điều chỉnh việc phát triển và triển khai công nghệ. Ví dụ, một cá nhân không thể đơn giản xây dựng một chiếc máy bay trong gara và chở hành khách mà không trải qua các cuộc kiểm toán nghiêm ngặt và nhận được các giấy phép cần thiết. Ngược lại, ngành AI hoạt động với ít ràng buộc hơn đáng kể, áp dụng một cách tiếp cận cực kỳ linh hoạt trong phát triển và triển khai, cho phép các nhà phát triển tạo ra và triển khai gần như bất kỳ mô hình nào. Các mô hình này sau đó có thể được tích hợp vào các thư viện phổ biến như Hugging Face, và các mô hình đó có thể lan rộng với ít kiểm toán. Sự chênh lệch này nhấn mạnh nhu cầu về một khung khổ có cấu trúc và chú trọng an toàn hơn trong AI. Bằng cách áp dụng khung khổ này, cộng đồng AI có thể hướng tới việc đảm bảo rằng công nghệ AI được phát triển và triển khai một cách có trách nhiệm, với trọng tâm là an toàn và phù hợp với giá trị xã hội.
Văn hóa an toàn có thể biến đổi các ngành công nghiệp. Các tiêu chuẩn trong việc theo đuổi an toàn có thể là một cách mạnh mẽ để phát hiện và ngăn chặn các cá nhân sai trái. Trong trường hợp thiếu một văn hóa an toàn mạnh mẽ, các công ty và cá nhân có thể bị cám dỗ để cắt giảm chi phí, có thể dẫn đến hậu quả thảm khốc (Manheim, 2023). Việc áp dụng văn hóa an toàn trong ngành hàng không vũ trụ đã biến đổi ngành này, làm cho nó trở nên hấp dẫn hơn, tạo ra nhiều doanh thu hơn và xây dựng niềm tin lâu dài. Tương tự, một văn hóa an toàn AI tham vọng sẽ yêu cầu việc thiết lập một ngành công nghiệp an toàn và bảo mật AI quy mô lớn.
Nếu đạt được, văn hóa an toàn sẽ là yếu tố hệ thống ngăn chặn rủi ro từ AI. Thay vì tập trung duy nhất vào việc triển khai kỹ thuật của một hệ thống AI cụ thể, cần chú ý đến áp lực xã hội, quy định và văn hóa an toàn. Đó là lý do tại sao việc thu hút cộng đồng ML rộng lớn chưa quen thuộc với an toàn AI là điều quan trọng (Hendrycks, 2022).
Làm thế nào để tăng cường nhận thức công chúng và văn hóa an toàn một cách cụ thể?