Chương này cố gắng trình bày tổng quan về chiến lược an toàn AI nhằm giảm thiểu các rủi ro được đề cập trong chương trước.
Khi năng lực của AI tiếp tục phát triển nhanh chóng, các chiến lược đảm bảo an toàn cũng phải được điều chỉnh. Đó là lý do tại sao phiên bản đầu tiên của tài liệu này được viết vào tháng 7 năm 2024 và được cập nhật vào cuối tháng 5 năm 2025. Chúng tôi thảo luận về các phương pháp kỹ thuật và cố gắng liên kết chương này với các chương khác trong cẩm nang. Mục tiêu là cung cấp cái nhìn tổng quan có cấu trúc về suy nghĩ hiện tại và công việc đang diễn ra trong chiến lược an toàn AI, đồng thời thừa nhận cả các phương pháp đã được thiết lập và các hướng nghiên cứu mới nổi. Đối với mỗi loại vấn đề vĩ mô như lợi dụng sai mục đích, căn chỉnh AI, chúng tôi liệt kê các chiến lược vĩ mô khác nhau có thể giúp giảm thiểu những rủi ro đó. Những chiến lược này thường có thể tổ hợp với nhau và nên được tổ hợp! Chúng tôi thảo luận về thứ tự thực hiện các chiến lược khác nhau ở phần cuối của chương.
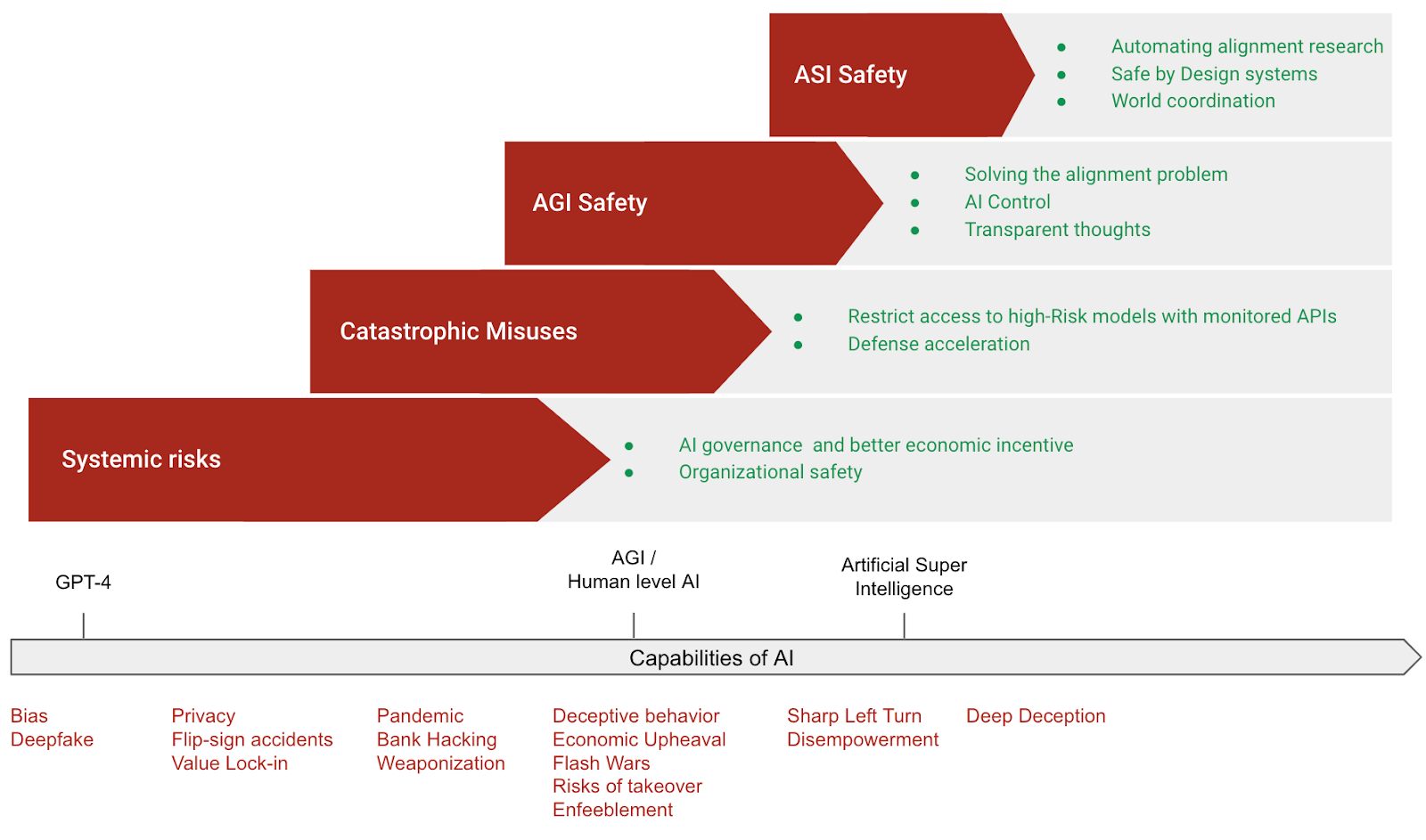
Sơ đồ tạm thời tóm tắt các phương pháp cấp cao chính để đảm bảo an toàn trong phát triển AI.
Ngoài phạm vi của chương này
Mặc dù chương này tập trung vào các chiến lược trực tiếp liên quan đến việc ngăn chặn các kết quả tiêu cực mở rộng quy mô do lợi dụng sai mục đích, mất căn chỉnh hoặc phát triển không kiểm soát, một số chủ đề liên quan khác buộc phải nằm ngoài phạm vi chính của nó:
Thông tin sai lệch do AI tạo ra: Sự lan rộng của thông tin sai lệch do AI tạo ra, bao gồm deepfakes và nội dung có định kiến. Các chiến lược chống lại điều này, như hệ thống phát hiện mạnh mẽ, đánh dấu nước và nguyên tắc AI có trách nhiệm, chủ yếu nằm ngoài phạm vi của chương này. Những vấn đề này thường thuộc phạm vi của quản lý nội dung, nhận thức về truyền thông và quản trị nền tảng, khác biệt với các chiến lược điều chỉnh kỹ thuật và kiểm soát AI cốt lõi được thảo luận trong chương này.
Quyền riêng tư: Hệ thống AI thường xử lý lượng dữ liệu khổng lồ, làm gia tăng các lo ngại hiện có về quyền riêng tư dữ liệu.
An ninh: Các thực hành an ninh tiêu chuẩn như mã hóa, kiểm soát truy cập, phân loại dữ liệu, giám sát mối đe dọa và ẩn danh hóa là điều kiện tiên quyết cho việc triển khai AI an toàn. Mặc dù an ninh mạnh mẽ là thiết yếu cho các biện pháp như bảo vệ trọng số mô hình, các thực hành tiêu chuẩn này khác biệt với các chiến lược an toàn mới cần thiết để giải quyết các rủi ro như mất căn chỉnh mô hình hoặc lợi dụng sai mục đích năng lực.
Phân biệt đối xử và độc hại: Mặc dù các đầu ra thiên vị hoặc độc hại là mối quan ngại về an toàn, chương này tập trung vào các chiến lược nhằm ngăn chặn các sự cố thảm khốc.
Sức khỏe tinh thần và quyền lợi trí tuệ số: Chúng ta chưa biết liệu AI có nên được coi là đối tượng luân lý hay không. Đây là một lĩnh vực đạo đức riêng biệt liên quan đến nghĩa vụ của chúng ta đối với AI, chứ không phải đảm bảo an toàn từ AI.
Lỗi do thiếu khả năng: Mặc dù sự cố của hệ thống AI do thiếu khả năng hoặc độ tin cậy là nguồn gốc của rủi ro (AISI, 2025), các chiến lược được thảo luận trong chương này nhằm giảm thiểu rủi ro phát sinh từ cả độ tin cậy không đủ và năng lực cao (nhưng mất căn chỉnh hoặc bị lợi dụng sai mục đích). Và các giải pháp cho loại rủi ro này cũng tương tự như trong các ngành công nghiệp khác: kiểm thử, lặp lại và nâng cao năng lực của hệ thống.
Phạm vi được lựa chọn ở đây phản ánh sự tập trung chung trong một số phần của cộng đồng an toàn AI vào các rủi ro tồn vong hoặc thảm họa quy mô lớn phát sinh từ các hệ thống AI mạnh mẽ, có thể có tính tác nhân.