Coherent Extrapolated Volition (CEV) cố gắng xác định điều mà con người sẽ cùng nhau mong muốn nếu chúng ta thông minh hơn, có kiến thức sâu rộng hơn và phát triển luân lý hơn. Nó đề xuất rằng thay vì lập trình trực tiếp các giá trị cụ thể vào một siêu trí tuệ, chúng ta nên lập trình cho nó tự suy luận ra điều mà con người sẽ mong muốn nếu chúng ta vượt qua các hạn chế nhận thức của mình. Khi chúng ta đào tạo các hệ thống AI dựa trên sở thích hiện tại của con người, chúng ta có nguy cơ mã hóa các thành kiến, mâu thuẫn và sự ngắn hạn của mình. CEV thay vào đó đặt câu hỏi: "Chúng ta sẽ muốn gì" nếu chúng ta biết nhiều hơn, suy nghĩ nhanh hơn, hoặc trở thành những con người mà chúng ta mong muốn, và đã phát triển cùng nhau hơn nữa? Về cơ bản, hãy hình dung phiên bản lý tưởng của nhân loại có thể tồn tại trong tương lai. Hãy bảo AI hành động theo đó (Yudkowsky, 2004).
CEV cố gắng tạo ra một hướng đi cho trí tuệ nhân tạo (AI) để tôn trọng những ý định sâu xa của con người thay vì những mong muốn tức thời. Việc triển khai thực tế của CEV vẫn còn mang tính suy đoán. Điều này đòi hỏi mô hình hóa phức tạp về tâm lý con người, phát triển đạo đức và động lực xã hội – những năng lực vượt quá năng lực của các hệ thống AI hiện tại. Các phương pháp hiện đại như RLHF (Học tăng cường từ phản hồi của con người) có thể được xem là những tiền thân sơ khai, giúp AI phù hợp với sở thích hiện tại của con người thay vì những sở thích được suy diễn. Các khung AI hiến pháp tiến gần hơn một chút đến CEV bằng cách cố gắng mã hóa các nguyên tắc cấp cao thay vì sở thích cụ thể, nhưng vẫn còn cách xa so với việc suy diễn đầy đủ.
Coherent Aggregated Volition (CAV) tìm kiếm một tập hợp mục tiêu và niềm tin nhất quán nhất thể hiện giá trị hiện tại của nhân loại mà không cố gắng ngoại suy sự phát triển trong tương lai. Ben Goertzel đề xuất phương án thay thế này cho CEV, tập trung vào giá trị hiện tại của con người thay vì suy đoán về phiên bản lý tưởng của chúng ta trong tương lai. CAV xem mục tiêu và niềm tin như "gobs" (tập hợp mục tiêu và niềm tin của bạn) và tìm kiếm một tập hợp nhất quán, gọn gàng nhất có thể, đồng thời duy trì sự tương đồng với các quan điểm đa dạng của con người. Khác với CEV, vốn giả định rằng giá trị của chúng ta sẽ hội tụ nếu chúng ta trở nên khai sáng hơn, CAV thừa nhận rằng những khác biệt giá trị cơ bản có thể vẫn tồn tại. Nó nhằm tạo ra một tập hợp thống nhất cân bằng các quan điểm khác nhau thay vì cố gắng dự đoán cách những quan điểm đó có thể phát triển. Điều này khiến CAV tiềm năng dễ thực hiện hơn, vì nó làm việc với các giá trị hiện tại có thể quan sát được thay vì các giá trị tương lai giả định (Goertzel, 2010).
Ý chí Kết hợp Hài hòa (CBV) nhấn mạnh rằng giá trị con người nên được "kết hợp" một cách sáng tạo thông qua các quy trình do con người hướng dẫn thay vì được trung bình hóa hoặc ngoại suy bằng thuật toán. CBV hoàn thiện CAV bằng cách giải quyết các hiểu lầm tiềm ẩn. Khi thảo luận về tổng hợp giá trị, nhiều người cho rằng điều đó có nghĩa là trung bình đơn giản hoặc bỏ phiếu đa số. CBV thay vào đó đề xuất một quy trình kết hợp sáng tạo tạo ra các hệ thống giá trị mới, hài hòa mà tất cả các bên tham gia đều công nhận là đại diện đầy đủ cho đóng góp của họ. Khái niệm này dựa trên các lý thuyết khoa học nhận thức về sự kết hợp khái niệm, nơi các ý tưởng mới nảy sinh từ sự tổ hợp sáng tạo của các ý tưởng hiện có. Trong khung này, quá trình xác định giá trị AI sẽ được con người hướng dẫn thông qua các quy trình hợp tác thay vì giao phó cho các hệ thống AI. Điều này giải quyết lo ngại về chủ nghĩa bảo hộ của AI, nơi máy móc có thể vượt qua tự định hướng của con người dưới danh nghĩa "lợi ích được ngoại suy" của chúng ta (Goertzel & Pitt, 2012).
CBV liên kết với các cuộc thảo luận đương đại về quản trị AI tham gia và giám sát dân chủ trong phát triển AI. Các hệ thống như vTaiwan đã triển khai các quy trình tương tự CBV cho phát triển chính sách công nghệ (vTaiwan, 2023), cho thấy cách thức kết hợp do con người hướng dẫn có thể hoạt động trong thực tế.
Định hướng đơn lẻ: Làm cho một hệ thống AI duy nhất đáng tin cậy theo đuổi mục tiêu của một nhà điều hành con người duy nhất. Chúng ta thậm chí chưa giải quyết được vấn đề này, và nó đặt ra những thách thức đáng kể. Một AI có thể được căn chỉnh để tuân theo các lệnh văn bản (như "đi lấy cà phê"), hiểu ý nghĩa dự định (hiểu rằng "đi lấy cà phê" có nghĩa là pha theo cách bạn thích), theo đuổi những gì bạn nên muốn (như đề xuất trà nếu cà phê không tốt cho sức khỏe), hoặc hành động vì lợi ích tốt nhất của bạn bất kể các lệnh. Tuân theo các lệnh văn bản thường dẫn đến các lỗi trong định nghĩa mà chúng ta sẽ thảo luận sau trong phần này. Hầu hết các nhà nghiên cứu sử dụng thuật ngữ "đồng bộ hóa" để chỉ "đồng bộ hóa ý định" (Christiano, 2018), và một số thảo luận triết học sâu hơn đề cập đến khía cạnh thứ ba - làm những gì tôi (hoặc nhân loại) mong muốn. Điều này bao gồm các khái niệm như ý chí được suy diễn một cách nhất quán (CEV) (Yudkowsky, 2004), ý chí được tổng hợp một cách nhất quán (CAV) (Goertzel, 2010), và các dòng suy nghĩ khác liên quan đến thảo luận về siêu đạo đức. Chúng ta sẽ không thảo luận sâu về các cuộc thảo luận triết học trong văn bản này, mà chủ yếu tập trung vào sự đồng nhất ý định và góc nhìn học máy. Khi sử dụng từ "đồng nhất" trong văn bản này, chúng ta chủ yếu đề cập đến các vấn đề và thất bại từ sự đồng nhất đơn lẻ. Các loại đồng nhất khác đã được nghiên cứu rất ít trong lịch sử, vì mọi người chủ yếu làm việc với ý tưởng về một siêu trí tuệ duy nhất tương tác với nhân loại như một khối thống nhất.
Đồng bộ hóa Đa-Đơn - Đồng bộ hóa Nhiều Trí tuệ Nhân tạo với Một Con người. Nếu chúng ta cho rằng ASI sẽ được cấu thành từ các trí tuệ nhỏ hơn làm việc cùng nhau, phân công nhiệm vụ và hoạt động như một siêu sinh vật, thì tất cả các vấn đề của căn chỉnh đơn lẻ vẫn sẽ tồn tại vì chúng ta vẫn cần giải quyết căn chỉnh đơn lẻ trước khi cố gắng căn chỉnh đa-đơn. Tốt nhất là chúng ta không muốn bất kỳ con người nào (hoặc một nhóm nhỏ con người) kiểm soát một siêu trí tuệ (giả sử không có những nhà độc tài tốt bụng).
Đồng bộ hóa đa-đơn lẻ - đồng bộ hóa một AI với nhiều con người. Khi nhiều con người chia sẻ kiểm soát một hệ thống AI duy nhất, chúng ta phải đối mặt với thách thức về việc giá trị và sở thích của ai nên được ưu tiên. Thay vì cố gắng tổng hợp trực tiếp sở thích cá nhân của mọi người (điều này có thể dẫn đến mâu thuẫn hoặc kết quả chung nhất), một cách tiếp cận hứa hẹn hơn là căn chỉnh AI theo các nguyên tắc cấp cao và giá trị tổ chức - tương tự như cách các thể chế dân chủ hoạt động dựa trên các nguyên tắc như minh bạch và trách nhiệm giải trình thay vì cố gắng tối ưu hóa trực tiếp cho sở thích của từng công dân.
Đồng bộ hóa đa chiều - căn chỉnh nhiều AI với nhiều con người và nhiều AI. Đây là kịch bản phức tạp nhất liên quan đến nhiều hệ thống AI tương tác với nhiều con người. Ở đây, sự phân biệt giữa rủi ro mất căn chỉnh (AI giành được quyền lực bất hợp pháp đối với con người) và rủi ro lợi dụng sai mục đích (con người sử dụng AI để giành quyền lực bất hợp pháp đối với người khác) bắt đầu mờ nhạt. Thách thức chính trở thành ngăn chặn sự tập trung quyền lực có vấn đề đồng thời cho phép hợp tác có lợi giữa con người và AI. Điều này đòi hỏi thiết kế hệ thống cẩn thận để thúc đẩy hành vi đồng bộ không chỉ ở cấp độ cá nhân mà còn trên toàn bộ mạng lưới tương tác giữa con người và AI.
Chưa rõ liệu việc giải quyết sự không đồng bộ đơn lẻ có đủ hay không. Ngay cả khi chúng ta có thể đảm bảo rằng mọi hệ thống AI đều hoàn toàn đồng bộ với ý định của chủ thể con người tương ứng, chúng ta vẫn phải đối mặt với những rủi ro nghiêm trọng khi các hệ thống này tương tác. Điều này là do các chủ thể khác nhau có thể có lợi ích xung đột, hoặc vì các hệ thống có thể không phối hợp hiệu quả ngay cả khi mục tiêu của chúng đồng nhất. Sự đồng nhất hoàn hảo ở cấp độ cá nhân không thể đảm bảo hành vi tập thể an toàn, giống như việc đồng nhất mọi tài xế với luật giao thông không ngăn chặn được ùn tắc hay tai nạn (Hammond et al., 2025). Về cơ bản, nếu chúng ta có ba vấn đề con về sự đồng nhất trong một tác nhân duy nhất, thì khi các tác nhân cá nhân này bắt đầu tương tác với nhau, chúng ta sẽ có thêm ba vấn đề con nữa: sự phối hợp sai lệch, xung đột và thông đồng. Mỗi vấn đề đại diện cho một cách khác nhau mà hệ thống đa tác nhân có thể thất bại, ngay cả khi các tác nhân cá nhân dường như hoạt động chính xác khi tách biệt. Còn nhiều cách khác nữa khi chúng ta bắt đầu xem xét các hiệu ứng phát sinh từ tương tác giữa các hệ thống phức tạp và xói mòn năng lực như đã đề cập trong chương về rủi ro.
Ngay cả khi các thách thức kỹ thuật về căn chỉnh AI được vượt qua, vẫn còn một loạt câu hỏi triết học sâu sắc và gây tranh cãi. Giải quyết an toàn AI, đặc biệt là cho Trí tuệ Siêu việt Nhân tạo (ASI), có thể đòi hỏi phải đối mặt với những vấn đề cốt lõi liên quan đến giá trị, ý thức và mục đích cuối cùng của sự tồn tại. Đồng bộ hóa ASI buộc chúng ta phải đặt ra những câu hỏi cơ bản về tương lai mà chúng ta thực sự mong muốn.
Chúng ta không nên chống lại sự kế thừa, mà nên đón nhận và chuẩn bị cho nó Tại sao chúng ta lại muốn những sinh vật vĩ đại hơn phải sống trong sự phục tùng? Tại sao chúng ta không vui mừng trước sự vĩ đại của họ như một biểu tượng và sự mở rộng của sự vĩ đại của nhân loại, và cùng nhau hướng tới một nền văn minh vĩ đại và bao trùm hơn?
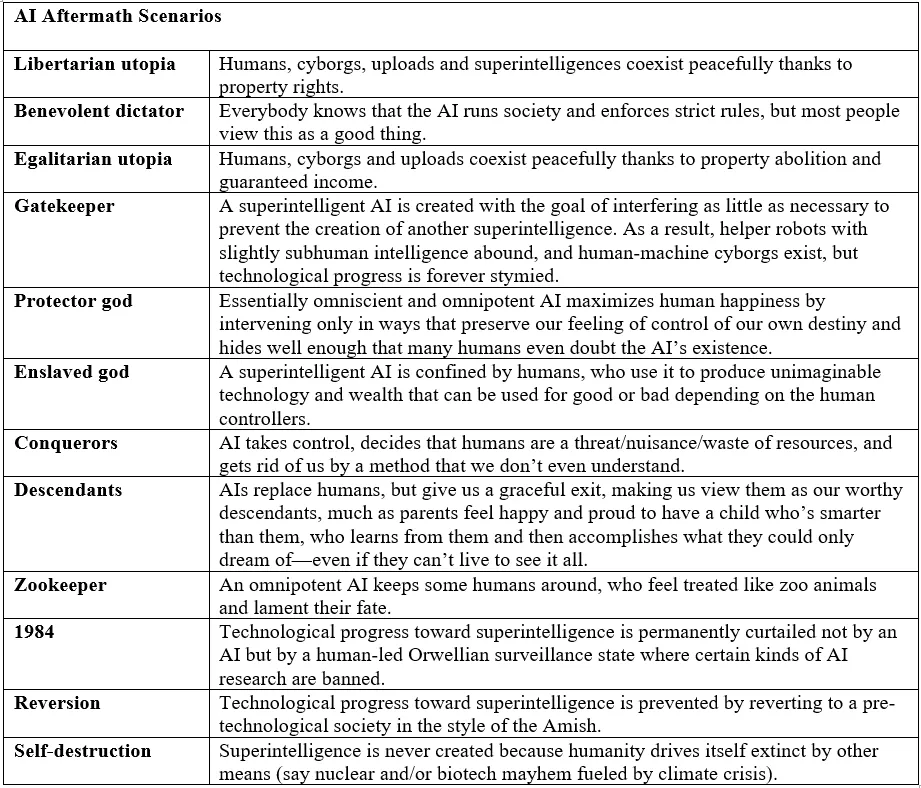
Cuối cùng: Các kết quả lâu dài tiềm năng là rất đa dạng và phụ thuộc mạnh mẽ vào cách chúng ta trả lời những câu hỏi triết học này. Mục tiêu cuối cùng có phải chỉ là sự tiếp tục của ý thức hoặc phức tạp, bất kể nền tảng vật lý của nó (như được Max Tegmark khám phá trong Life 3.0 (Tegmark, 2017))? Các lập trường triết học khác nhau dẫn đến những ưu tiên chiến lược hoàn toàn khác nhau cho sự phát triển và điều chỉnh của Trí tuệ Nhân tạo Siêu việt (ASI).