
Trong các phần trước, chúng ta đã khám phá cách các mô hình nền tảng tận dụng khả năng điện toán thông qua định luật mở rộng quy mô và bài học cay đắng. Nhưng làm thế nào chúng ta có thể dự đoán hướng phát triển của năng lực AI? Phần này giới thiệu các phương pháp dự báo chính giúp chúng ta dự đoán tiến bộ của AI và chuẩn bị các biện pháp an toàn phù hợp.
Tại sao chúng ta nên quan tâm đến dự báo? Dự báo tiến bộ của AI là yếu tố quan trọng trong công tác an toàn AI. Thời gian để AI chuyển đổi định hình mọi thứ từ ưu tiên nghiên cứu đến khung khổ quản trị – nếu chúng ta dự đoán AI chuyển đổi trong 5 năm so với 50 năm, điều này sẽ thay đổi đáng kể các biện pháp an toàn khả thi. Ví dụ, nếu chúng ta dự đoán tiến bộ nhanh chóng, chúng ta có thể cần tập trung vào các biện pháp an toàn có thể triển khai nhanh chóng thay vì nghiên cứu lý thuyết dài hạn. Ngoài ra, việc hiểu rõ các hướng phát triển có thể xảy ra giúp chúng ta dự đoán các năng lực cụ thể và chuẩn bị các biện pháp an toàn mục tiêu trước khi chúng xuất hiện. Điều này đặc biệt quan trọng do tiềm năng của các bước nhảy vọt về năng lực, đặc biệt là trong các năng lực nguy hiểm như tạo mã độc hoặc lừa đảo.
Làm thế nào để chuyển đổi niềm tin thành xác suất và dự báo? Chúng ta cần một số cách để thực sự chuyển đổi niềm tin như "niềm tin của tôi là AGI có khả năng xuất hiện trong thập kỷ này" thành các ước tính xác suất chính xác. Một cách để làm điều này là phân tích - chia nhỏ các niềm tin phức tạp thành các thành phần nhỏ hơn, có thể đo lường được và phân tích dữ liệu liên quan. Thay vì ước tính trực tiếp năm mà AI biến đổi xuất hiện, chúng ta có thể bắt đầu bằng cách dự báo riêng lẻ các yếu tố như tăng trưởng khả năng điện toán, tiến bộ thuật toán và giới hạn phần cứng, sau đó tổ hợp các ước tính này (Zhang, 2024). Phương pháp phân tích này giúp chúng ta dựa vào các xu hướng quan sát được thay vì chỉ dựa vào直觉. Vậy, sử dụng phương pháp này, có hai kỹ thuật chính cần thảo luận - dự báo cấp độ 0 để thiết lập cơ sở, và dự báo cấp độ 1 để hiểu thay đổi quỹ đạo.
Lớp tham chiếu là gì và tại sao chúng lại quan trọng? Khi phân tích từng thành phần của dự báo phân tách, chúng ta cần các ví dụ lịch sử liên quan để hỗ trợ dự đoán. Đây là lúc lớp tham chiếu phát huy tác dụng - chúng là các danh mục tình huống lịch sử tương tự mà chúng ta có thể sử dụng để đưa ra dự đoán. Đối với phát triển AI, các lớp tham chiếu liên quan có thể bao gồm các cuộc cách mạng công nghệ trước đây (như cách mạng công nghiệp hoặc cách mạng máy tính), các hệ thống tối ưu hóa khác (như tiến hóa sinh học hoặc nền kinh tế), hoặc tầm ảnh hưởng của những tiến bộ khoa học nhanh chóng (như CRISPR hoặc vắc-xin mRNA). Điểm cơ bản là chúng nên có sự tương đồng có ý nghĩa với những gì bạn đang cố gắng dự đoán, nhưng không nhất thiết phải thuộc cùng một danh mục chính xác.
Dự báo cấp độ 0 là gì? Phương pháp dự báo đơn giản nhất bắt đầu bằng việc nhận ra rằng ngày mai thường khá giống với hôm nay. Dự báo cấp độ 0 sử dụng các lớp tham chiếu - xem xét 3-5 ví dụ lịch sử tương tự và sử dụng trung bình của chúng làm dự đoán cơ sở. Thay vì cố gắng xác định xu hướng hoặc đưa ra các dự đoán phức tạp, nó giả định rằng các mẫu gần đây sẽ tiếp tục (Steinhardt, 2024).
Dự báo cấp độ thứ nhất là gì? Trong khi dự báo cấp độ thứ không sử dụng các ví dụ lịch sử từ các lớp tham chiếu khác nhau làm dự báo trực tiếp, dự báo cấp độ thứ nhất cố gắng xác định và dự báo các mẫu trong dữ liệu lịch sử trực tiếp của sự phát triển AI. Trong AI, chúng ta thấy một số mô hình tăng trưởng theo cấp số nhân khá nhất quán. Khả năng điện toán được sử dụng trong các mô hình tiên tiến đã tăng 4,2 lần mỗi năm kể từ năm 2010, tập dữ liệu đào tạo đã mở rộng khoảng 2,9 lần mỗi năm, và hiệu suất phần cứng cải thiện khoảng 1,35 lần mỗi năm nhờ các tiến bộ kiến trúc (Epoch AI, 2023). Dự báo cấp độ 1 cố gắng xác định các mô hình này và dự báo chúng trong tương lai. Đây là phương pháp được hầu hết các công trình dự đoán AI hệ thống hiện nay áp dụng, bao gồm khung công nghệ tập trung vào khả năng điện toán của Epoch AI và các "điểm neo sinh học" của Ajeya Cotra. Tuy nhiên, cần lưu ý rằng mặc dù các xu hướng này đã rất điều đáng chú ý nhất quán, chúng không thể tiếp tục vô hạn. Các giới hạn vật lý, nhiệt động lực học hoặc kinh tế sẽ cuối cùng hạn chế sự tăng trưởng. Câu hỏi quan trọng là: khi nào các giới hạn này trở nên có ý nghĩa? Chúng ta sẽ khám phá điều này trong phần tiếp theo về khung công nghệ tập trung vào khả năng điện toán.
Làm thế nào để tổ hợp các dự báo khác nhau? Các phương pháp dự báo khác nhau thường đưa ra các dự đoán khác nhau – dự báo cấp độ 0 có thể đề xuất một kịch bản trong khi ngoại suy xu hướng lại chỉ ra một kịch bản khác. Giống như chúng ta có thể tính trung bình ý kiến của nhiều chuyên gia, chúng ta có thể tích hợp các dự đoán này để có được một bức tranh chính xác hơn. Một phương pháp là mô hình hóa mỗi dự báo như một phân phối xác suất và kết hợp chúng bằng các mô hình hỗn hợp (Steinhardt, 2024).
Còn trong các tình huống có dữ liệu hạn chế hoặc không có lớp tham chiếu rõ ràng thì sao? Mặc dù phân tích phân rã, lớp tham chiếu và phân tích xu hướng là nền tảng của dự đoán AI, chúng ta đôi khi phải đối mặt với các câu hỏi nơi dữ liệu trực tiếp hạn chế hoặc không có lớp tham chiếu rõ ràng. Ví dụ, dự đoán tầm ảnh hưởng xã hội của các hệ thống AI tiên tiến hoặc dự báo các năng lực mới chưa được chứng minh trước đây. Trong những trường hợp này, chúng ta thường dựa vào phán đoán của chuyên gia và các nhà dự báo siêu việt. Một ưu điểm của dự báo chuyên gia là khả năng tích hợp các thông tin định tính có thể bị bỏ qua bởi phân tích xu hướng thuần túy. Ví dụ, các chuyên gia có thể nhận ra các sự kiện cảnh cáo sớm về quy luật hiệu suất giảm dần hoặc xác định các phương pháp kỹ thuật mới có thể thúc đẩy tiến bộ. Việc sử dụng cân bằng giữa các phương pháp dựa trên dữ liệu và phán đoán chuyên gia đặc biệt quan trọng trong công tác an toàn AI. Mặc dù chúng ta nên dựa vào các xu hướng thực nghiệm khi có thể, chúng ta cũng cần các khung khổ để suy luận về các phát triển chưa từng có và các điểm gián đoạn tiềm ẩn trong tiến bộ.
Mức độ tổng quát hóa của các phát hiện thực nghiệm là bao xa? Hiện đang có một cuộc tranh luận về mức độ tin cậy của các xu hướng hiện tại trong việc dự đoán sự phát triển tương lai của AI. Một số nhà nghiên cứu cho rằng các phát hiện thực nghiệm trong AI có thể tổng quát hóa một cách đáng ngạc nhiên - rằng các mẫu chúng ta quan sát ngày nay sẽ tiếp tục áp dụng ngay cả khi các hệ thống trở nên có năng lực hơn (Steinhardt, 2022). Tuy nhiên, thành tích dự báo của chúng ta cho thấy chúng ta nên thận trọng. Khi các nhà dự báo hàng đầu dự đoán độ chính xác của bộ dữ liệu MATH sẽ cải thiện từ 44% lên 57% vào tháng 6 năm 2022, hiệu suất thực tế đạt 68% - một mức mà họ đánh giá là cực kỳ khó xảy ra. Ngay sau đó, GPT-4 đạt độ chính xác 86,4%. Có một số ví dụ khác về các mô hình ngôn ngữ lớn (LLMs) khiến hầu hết các nhà dự báo và chuyên gia ngạc nhiên trên một số bài kiểm tra (Cotra, 2023).
Mô hình đánh giá thấp tiến bộ này cho thấy rằng trong khi các xu hướng thực nghiệm cung cấp hướng dẫn có giá trị, chúng có thể không phản ánh đầy đủ tất cả các động lực của sự phát triển trí tuệ nhân tạo (AI). Trước khi GPT-3 ra đời, nhiều chuyên gia tin rằng các tác vụ phức tạp như suy luận phức tạp sẽ yêu cầu các kiến trúc chuyên biệt. Sự xuất hiện của các năng lực này chỉ thông qua việc mở rộng quy mô cho thấy các hệ thống có thể phát triển các năng lực bất ngờ chỉ thông qua các cải tiến định lượng. Điều này có ý nghĩa quan trọng đối với cả dự báo và quản trị - chúng ta cần các khung khổ có thể thích ứng với các năng lực xuất hiện nhanh hơn hoặc khác biệt so với những gì các xu hướng hiện tại gợi ý.
Làm thế nào điều này giúp chúng ta dự đoán AI mang tính cách mạng? Các nguyên tắc dự báo này giúp chúng ta đánh giá một cách phê phán các tuyên bố về thời gian biểu AI và các kịch bản cất cánh AI. Khi gặp các dự đoán về tiến bộ gián đoạn hoặc mở rộng quy mô mượt mà, chúng ta có thể hỏi: Những xu hướng nào hỗ trợ quan điểm này? Các lớp tham chiếu nào là liên quan? Các dự báo tương tự đã thể hiện hiệu suất như thế nào trong lịch sử? Cách tiếp cận có hệ thống này giúp chúng ta vượt qua trực giác để đưa ra các dự đoán nghiêm ngặt hơn về quỹ đạo phát triển của AI.
Thị trường dự đoán giống như hệ thống cá cược, nơi mọi người có thể mua và bán cổ phiếu dựa trên dự đoán của họ về các sự kiện tương lai. Ví dụ, nếu có một thị trường dự đoán cho cuộc bầu cử tổng thống, bạn có thể mua cổ phiếu cho ứng cử viên mà bạn cho là sẽ thắng. Nếu nhiều người tin rằng Ứng cử viên A sẽ thắng, giá cổ phiếu của Ứng cử viên A sẽ tăng, cho thấy khả năng thắng cao hơn.
Các thị trường này hữu ích vì chúng tập hợp kiến thức và ý kiến của nhiều người, thường dẫn đến các dự đoán chính xác. Ví dụ, một công ty có thể sử dụng thị trường dự đoán để dự báo liệu một sản phẩm mới có thành công hay không. Nhân viên có thể mua cổ phiếu nếu họ tin rằng sản phẩm sẽ thành công. Nếu đa số cho rằng sản phẩm sẽ thành công, giá cổ phiếu sẽ tăng, cung cấp cho công ty một dấu hiệu tốt về tiềm năng thành công của sản phẩm.
Bằng cách cho phép người tham gia kiếm lợi từ các dự đoán chính xác, các thị trường này khuyến khích việc chia sẻ thông tin có giá trị và cung cấp cập nhật thời gian thực về khả năng xảy ra của các kết quả khác nhau. Lập luận cho rằng hoặc các thị trường dự đoán chính xác hơn các chuyên gia, hoặc các chuyên gia có thể kiếm được nhiều tiền từ các thị trường này và, qua đó, điều chỉnh các thị trường. Vì vậy, động lực kiếm lợi dẫn đến các dự đoán chính xác nhất. Các ví dụ về thị trường dự đoán bao gồm Manifold hoặc Metaculus.
Khi sử dụng thị trường dự đoán để ước tính tính tái hiện của nghiên cứu khoa học, người ta phát hiện ra rằng chúng vượt trội hơn các cuộc khảo sát chuyên gia (Dreber et al., 2015). Vì vậy, nếu có nhiều chuyên gia tham gia, thị trường dự đoán có thể là một trong những công cụ dự báo xác suất tốt nhất của chúng ta, thậm chí tốt hơn cả các cuộc khảo sát hoặc chuyên gia.
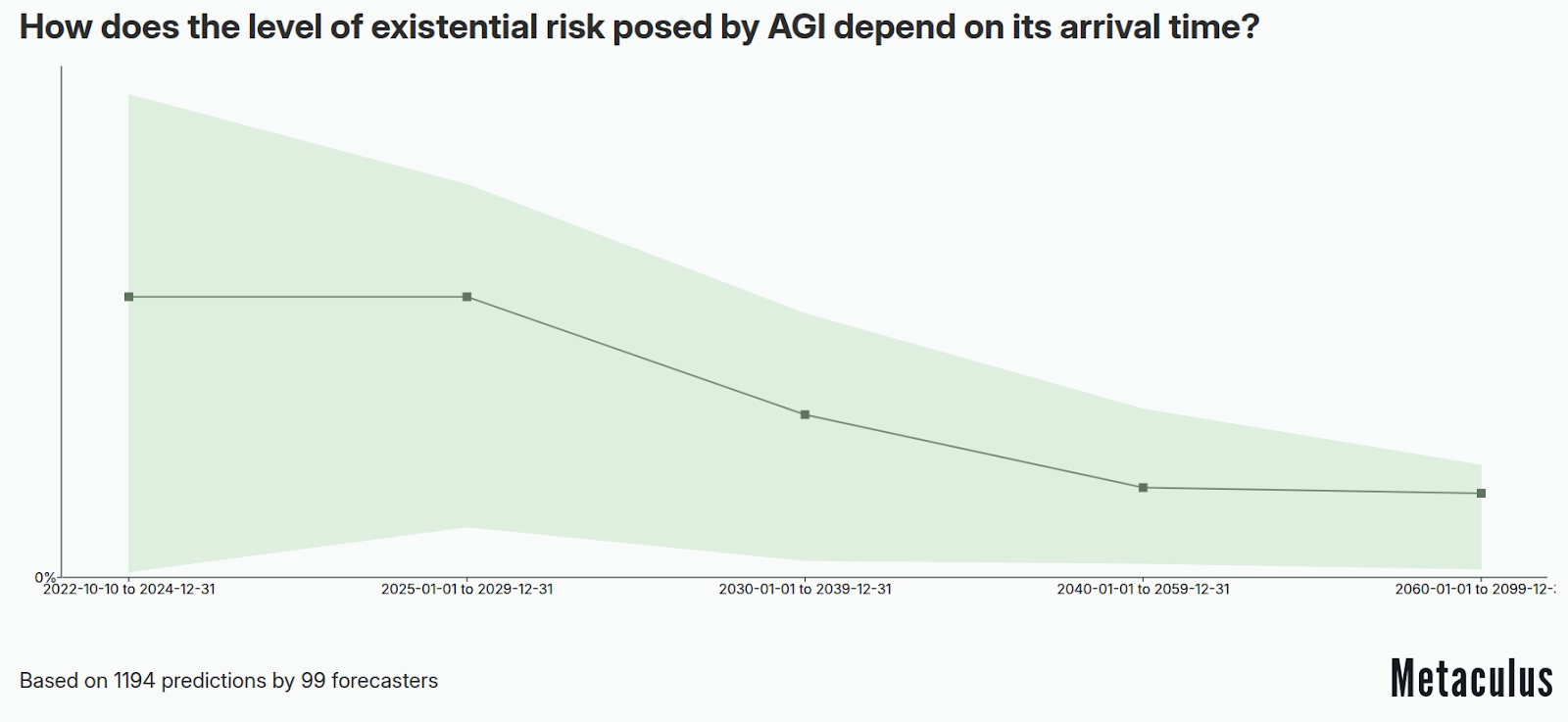
Thị trường dự đoán - Mức độ rủi ro hiện sinh do Trí tuệ Nhân tạo Tổng quát (AGI) gây ra phụ thuộc như thế nào vào thời điểm xuất hiện của nó? (Metaculus, 2022)

Thị trường dự đoán - Khi nào hệ thống AI tổng quát đầu tiên sẽ được phát triển, thử nghiệm và công bố công khai? (Metaculus, 2020)
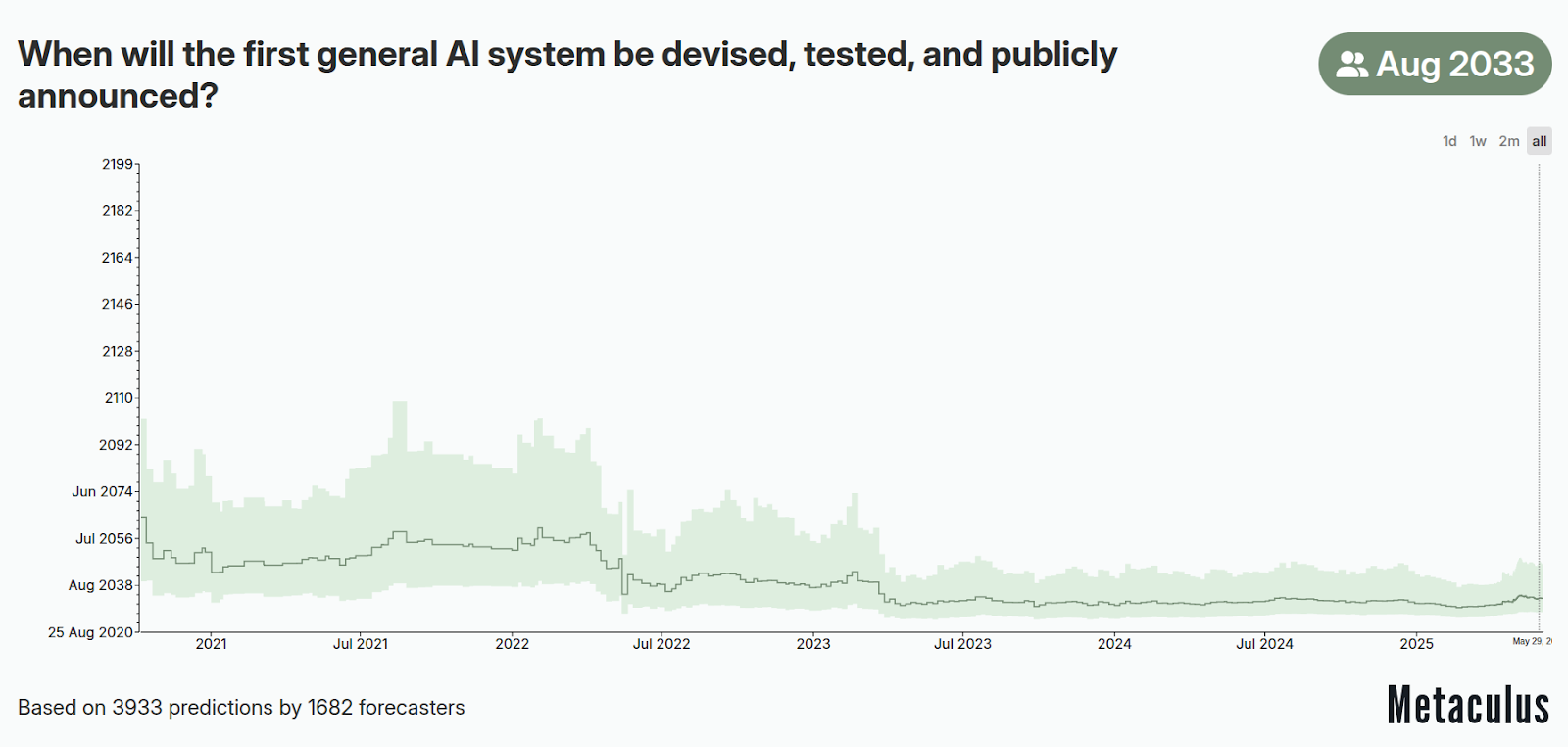
Thị trường dự đoán - Khi nào hệ thống AI tổng quát đầu tiên sẽ được phát triển, thử nghiệm và công bố công khai? (Metaculus, 2020)
<iframe-static-figure>
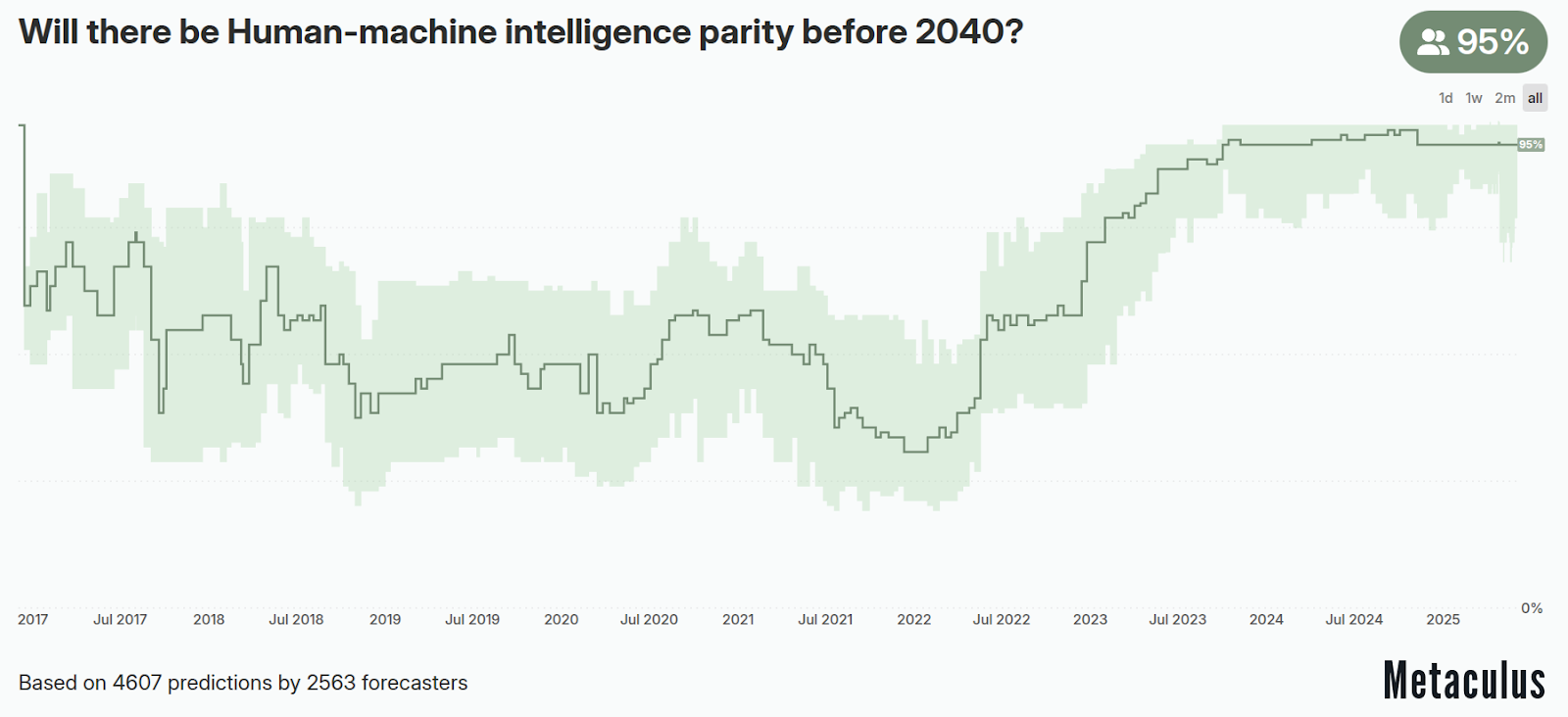
Thị trường dự đoán - Liệu trí tuệ nhân tạo và trí tuệ con người có đạt được sự ngang bằng trước năm 2040? (Metaculus, 2016)
Thông thường, ba thành phần chính được công nhận là các biến số chính thúc đẩy sự phát triển của học sâu là: khả năng điện toán sẵn có, cải tiến thuật toán và sự sẵn có của dữ liệu. Ba biến số này đôi khi cũng được gọi là các đầu vào của hàm sản xuất AI hoặc bộ ba AI (Buchanan, 2022).
Chúng ta có thể dự đoán rằng các mô hình sẽ tiếp tục mở rộng quy mô trong tương lai gần. Sự mở rộng quy mô kết hợp với tính chất ngày càng đa năng của các mô hình nền tảng có thể dẫn đến sự tăng trưởng bền vững trong năng lực AI đa năng.

Các xu hướng và con số chính trong Học máy (Epoch, 2025)
Điều đầu tiên cần xem xét là xu hướng về tổng lượng tài nguyên khả năng điện toán cần thiết khi đào tạo mô hình. Lượng tài nguyên khả năng điện toán cho đào tạo đã tăng 1,58 lần/năm cho đến cuộc cách mạng Học sâu vào khoảng năm 2010, sau đó tốc độ tăng trưởng tăng lên 4,2 lần/năm. Chúng ta cũng nhận thấy một xu hướng mới về các mô hình "quy mô lớn" xuất hiện vào năm 2016, được đào tạo với khả năng điện toán nhiều hơn 2-3 bậc so với các hệ thống khác trong cùng kỳ.
Sự phát triển của phần cứng đang song hành với các xu hướng trong lĩnh vực khả năng điện toán và dữ liệu. GPU đang chứng kiến sự gia tăng 1,35 lần mỗi năm về số phép tính điểm nổi trên giây (FLOP/s). Tuy nhiên, các hạn chế về bộ nhớ đang nổi lên như những điểm nghẽn tiềm ẩn, với dung lượng và băng thông DRAM cải thiện với tốc độ chậm hơn. Xu hướng đầu tư phản ánh những tiến bộ công nghệ này
Năm 2010, trước cuộc cách mạng học sâu, Shane Legg, đồng sáng lập DeepMind, đã dự đoán trí tuệ nhân tạo (AI) đạt trình độ con người vào năm 2028 dựa trên các ước tính về khả năng điện toán (Legg, 2010). Ilya Sutskever, đồng sáng lập OpenAI, người đã công bố bài báo AlexNet khơi mào cuộc cách mạng học sâu, cũng là một trong những người ủng hộ sớm ý tưởng rằng việc mở rộng quy mô học sâu sẽ mang tính cách mạng.

Lượng khả năng điện toán đào tạo của các mô hình AI tiên tiến tăng 4-5 lần mỗi năm (Sevilla & Roldán, 2024)
Trong phần này, chúng ta sẽ xem xét xu hướng về số lượng tham số của mô hình. Biểu đồ sau đây cho thấy mặc dù số lượng tham số luôn tăng, nhưng trong kỷ nguyên mới từ năm 2018 trở đi, chúng ta thực sự đã bước vào một giai đoạn tăng trưởng khác biệt. Tổng thể, từ những năm 1950 đến 2018, các mô hình đã tăng trưởng với tốc độ 0,1 bậc độ lớn mỗi năm (OOM/năm). Điều này có nghĩa là trong 68 năm từ 1950 đến 2018, các mô hình đã tăng tổng cộng 7 đơn vị. Tuy nhiên, sau năm 2018, chỉ trong 5 năm gần đây, số lượng tham số đã tăng thêm 4 đơn vị (không tính số tham số của GPT-4 vì chúng ta không biết).
Bảng và đồ thị sau đây minh họa sự thay đổi xu hướng trong sự tăng trưởng thông số của các mô hình học máy. Lưu ý sự tăng lên đến nửa nghìn tỷ thông số với dữ liệu đào tạo không đổi.

Kích thước mô hình học máy và khoảng cách tham số (Villalobos et al., 2022)
Chúng ta đang sử dụng lượng dữ liệu ngày càng tăng để đào tạo các mô hình của mình. Phương pháp đào tạo các mô hình nền tảng để tinh chỉnh sau này đang thúc đẩy xu hướng này. Nếu chúng ta muốn một mô hình nền tảng tổng quát, chúng ta cần cung cấp cho nó 'dữ liệu tổng quát', tức là: tất cả dữ liệu mà chúng ta có thể thu thập được. Bạn có thể đã nghe nói rằng các mô hình như ChatGPT và PaLM được đào tạo trên dữ liệu từ internet. Internet là kho dữ liệu lớn nhất mà con người có. Ngoài ra, như chúng ta đã quan sát từ các định luật mở rộng quy mô trong các bài báo về Chinchilla, có thể dữ liệu để đào tạo mô hình của chúng ta chính là nút thắt cổ chai thực sự, chứ không phải khả năng điện toán hay số lượng tham số. Vì vậy, câu hỏi tự nhiên là còn bao nhiêu dữ liệu trên internet để chúng ta tiếp tục đào tạo mô hình? Và con người chúng ta tạo ra bao nhiêu dữ liệu mới mỗi năm?
Chúng ta tạo ra bao nhiêu dữ liệu?
Tổng lượng dữ liệu được tạo ra mỗi ngày vào năm 2019 là khoảng ~463EB (Diễn đàn Kinh tế Thế giới, 2019). Tuy nhiên, trong bài viết này, chúng ta sẽ giả định rằng mô hình không được đào tạo trên "toàn bộ dữ liệu được tạo ra" (chưa), mà chỉ tiếp tục đào tạo trên dữ liệu văn bản và hình ảnh nguồn mở trên internet. Lượng dữ liệu văn bản và hình ảnh có sẵn đã tăng 0,14 OOM/năm từ năm 1990 đến 2018, nhưng sau đó đã chậm lại còn 0,03 OOM/năm.
Còn bao nhiêu dữ liệu còn lại?
Dự báo trung bình về thời điểm tập dữ liệu đào tạo của các mô hình ML nổi bật cạn kiệt nguồn dữ liệu văn bản được biên tập chuyên nghiệp trên internet là năm 2024. Dự báo trung bình về năm mà các mô hình ML sử dụng hết toàn bộ văn bản trên internet là năm 2040. Tổng thể, các dự báo của Epochai cho thấy chúng ta sẽ cạn kiệt dữ liệu ngôn ngữ chất lượng cao trước năm 2026, dữ liệu ngôn ngữ chất lượng thấp trong khoảng từ 2030 đến 2050, và dữ liệu hình ảnh trong khoảng từ 2030 đến 2060. Điều này có thể là dấu hiệu cho thấy tiến bộ của ML sẽ chậm lại sau vài thập kỷ tới. Các kết luận của Epochai, giống như tất cả các kết luận khác trong phần tính toán này, dựa trên các giả định không thực tế rằng xu hướng hiện tại trong việc sử dụng và sản xuất dữ liệu ML sẽ tiếp tục và sẽ không có những đổi mới lớn về hiệu quả dữ liệu, tức là chúng ta giả định rằng lượng năng lực được thu được từ mỗi điểm dữ liệu đào tạo sẽ không thay đổi so với tiêu chuẩn hiện tại.
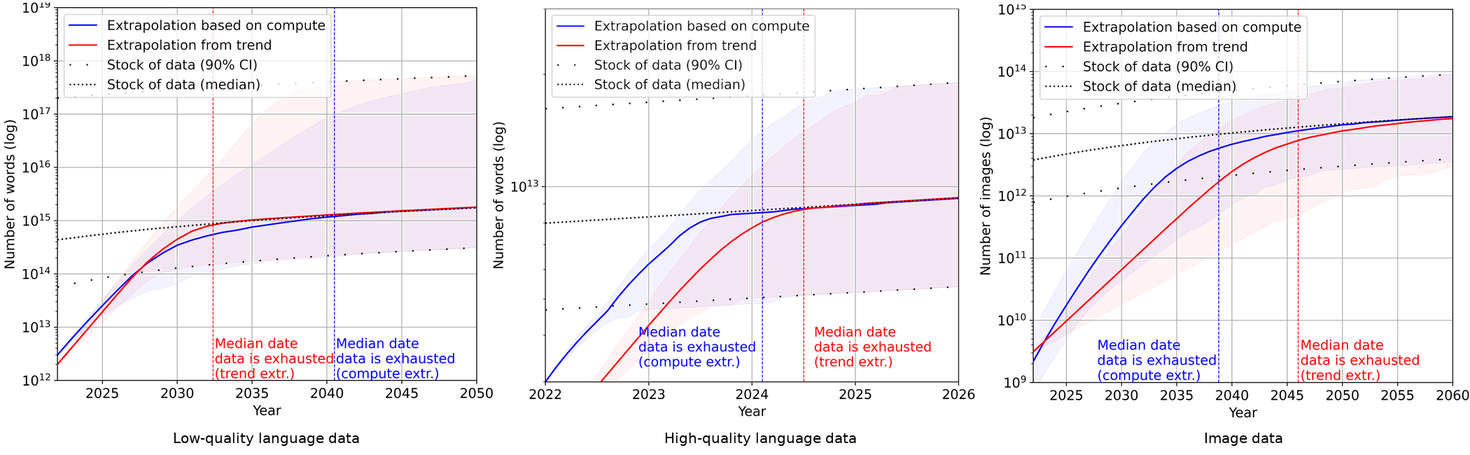
Xu hướng tiêu thụ và sản xuất dữ liệu ML cho văn bản chất lượng thấp, văn bản chất lượng cao và hình ảnh. (Epoch AI, 2023)
Ngay cả khi chúng ta cạn kiệt dữ liệu, nhiều giải pháp đã được đề xuất, chẳng hạn như sử dụng dữ liệu tổng hợp, lọc và tiền xử lý dữ liệu bằng GPT-3.5 để tạo ra bộ dữ liệu sạch hơn, một phương pháp được sử dụng trong bài báo "Textbooks are all bạn need" với các mô hình như Phi 1.5B, cho thấy hiệu suất xuất sắc so với kích thước của chúng nhờ sử dụng dữ liệu đã được lọc chất lượng cao, đến việc sử dụng các phương pháp đào tạo hiệu quả hơn hoặc tăng hiệu quả bằng cách đào tạo trên nhiều epoch hơn.
Các tiến bộ thuật toán cũng đóng vai trò quan trọng. Ví dụ, từ năm 2012 đến 2021, sức mạnh tính toán cần thiết để đạt được hiệu suất tương đương với AlexNet đã giảm đi 40 lần, tương ứng với việc giảm 3 lần mỗi năm về khả năng điện toán cần thiết để đạt được cùng hiệu suất trong các tác vụ phân loại hình ảnh như ImageNet. Việc cải tiến kiến trúc cũng được coi là tiến bộ thuật toán. Một kiến trúc đặc biệt có ảnh hưởng là kiến trúc Transformers, trung tâm của nhiều đổi mới gần đây, đặc biệt trong chatbot và học tự hồi quy. Khả năng đào tạo song song trên mọi token trong cửa sổ ngữ cảnh của chúng tận dụng tối đa sức mạnh của GPU hiện đại, và điều này được cho là một trong những lý do chính khiến chúng hoạt động tốt hơn so với tiền nhiệm, mặc dù điểm này vẫn còn tranh cãi.
Đây là một câu hỏi phức tạp, nhưng một số bằng chứng cho thấy rằng một khi kiến trúc đã đủ biểu đạt và có khả năng mở rộng, tầm quan trọng của kiến trúc có thể không lớn như bạn có thể nghĩ:
Trong một bài báo có tiêu đề ‘ConvNets Match Vision Transformers at Scaling’, các nhà nghiên cứu của Google phát hiện ra rằng Visual Transformers (ViT) có thể đạt được kết quả tương tự như CNNs (Mạng thần kinh tích chập) chỉ bằng cách sử dụng nhiều khả năng điện toán hơn. (Smith et al., 2023) Họ đã sử dụng một kiến trúc CNN đặc biệt và đào tạo nó trên một tập dữ liệu khổng lồ gồm bốn tỷ hình ảnh. Mô hình kết quả đạt được độ chính xác tương đương với các hệ thống ViT hiện có sử dụng tài nguyên đào tạo tương tự.
Variational AutoEncoders có thể bắt kịp nếu bạn làm chúng rất sâu (Child, 2021; Vahdat & Kautz, 2021).
Tiến bộ vào cuối năm 2023, như kiến trúc mamba (Gu & Dao, 2023), dường như là một cải tiến so với transformer. Nó có thể được xem là một bước tiến thuật toán giúp giảm lượng tài nguyên khả năng điện toán cần thiết để đạt được cùng mức hiệu suất.
Các kết nối và chuẩn hóa trong mô hình Transformer, vốn được cho là quan trọng, có thể được loại bỏ nếu các trọng số được thiết lập đúng cách. Điều này cũng có thể làm cho thiết kế Transformer đơn giản hơn (Tuy nhiên, cần lưu ý rằng kiến trúc này chậm hội tụ hơn so với các kiến trúc khác). (He et al., 2023)
Ở phía đối lập, một số kiến trúc chú ý (attention) có khả năng mở rộng đáng kể khi xử lý các cửa sổ ngữ cảnh dài, và không có lượng đào tạo nào có thể bù đắp cho điều này trong các mô hình transformer cơ bản. Các kiến trúc được thiết kế riêng để xử lý chuỗi dài, như Sparse Transformers (Child et al., 2019) hoặc Longformer (Beltagy et al., 2020), có thể vượt trội hơn transformer tiêu chuẩn một cách đáng kể cho mục đích này. Trong lĩnh vực thị giác máy tính, các kiến trúc như CNNs được cấu trúc sẵn để nhận diện các cấp bậc không gian trong hình ảnh, khiến chúng hiệu quả hơn cho các tác vụ này so với các kiến trúc không chuyên về xử lý dữ liệu không gian khi lượng dữ liệu hạn chế, và "prior" được mã hóa trong kiến trúc giúp mô hình học nhanh hơn.
Hiểu rõ chi phí thực tế của các đợt đào tạo machine learning (ML) là điều quan trọng vì nhiều lý do. Thứ nhất, điều này phản ánh chi phí kinh tế thực sự của việc phát triển hệ thống machine learning, điều này rất quan trọng để dự báo tương lai của sự phát triển trí tuệ nhân tạo (AI) và xác định những cá nhân nào có thể đủ khả năng theo đuổi các dự án AI quy mô lớn. Thứ hai, bằng cách tổ hợp ước tính chi phí với các chỉ số hiệu suất, chúng ta có thể theo dõi hiệu quả và năng lực của các hệ thống ML theo thời gian, cung cấp thông tin về cách các hệ thống này đang cải thiện và nơi có thể tồn tại các điểm yếu. Cuối cùng, những thông tin này giúp xác định tính bền vững của xu hướng chi tiêu hiện tại và hướng dẫn các khoản đầu tư tương lai vào nghiên cứu và phát triển AI, đảm bảo nguồn lực được phân bổ hiệu quả để thúc đẩy đổi mới đồng thời quản lý tầm ảnh hưởng kinh tế.
Luật Moore, dự đoán việc tăng gấp đôi mật độ transistor và do đó khả năng điện toán khoảng hai năm một lần, đã dẫn đến việc giảm chi phí khả năng điện toán trong lịch sử. Tuy nhiên, báo cáo cho thấy chi tiêu cho đào tạo ML đã tăng trưởng nhanh hơn nhiều so với mức giảm chi phí được dự đoán bởi Định luật Moore. Điều này có nghĩa là mặc dù phần cứng đã trở nên rẻ hơn, chi phí tổng thể cho việc đào tạo các hệ thống ML đã tăng vọt do nhu cầu ngày càng tăng về khả năng điện toán. Sự chênh lệch này nhấn mạnh tốc độ phát triển nhanh chóng của ML và các khoản đầu tư đáng kể cần thiết để theo kịp nhu cầu tính toán ngày càng tăng.
Để đo lường chi phí của các lần đào tạo ML, báo cáo sử dụng hai phương pháp chính. Phương pháp đầu tiên sử dụng xu hướng lịch sử về tỷ lệ giá-hiệu suất của GPU để ước tính chi phí. Phương pháp này tận dụng các xu hướng chung về sự phát triển phần cứng và giảm chi phí theo thời gian. Phương pháp thứ hai dựa trên phần cứng cụ thể được sử dụng để đào tạo hệ thống ML, chẳng hạn như GPU NVIDIA, cung cấp cái nhìn chi tiết và chính xác hơn về chi phí liên quan đến các công nghệ cụ thể. Cả hai phương pháp đều bao gồm việc tính toán chi phí phần cứng — phần chi phí phần cứng ban đầu được sử dụng cho đào tạo — và chi phí năng lượng, tính toán lượng điện năng cần thiết để vận hành phần cứng trong quá trình đào tạo. Các tính toán này cung cấp cái nhìn toàn diện về gánh nặng kinh tế của việc đào tạo mô hình ML.
Đo lường chi phí phát triển không chỉ giới hạn ở lần đào tạo cuối cùng của hệ thống ML mà còn bao gồm nhiều yếu tố khác. Điều này bao gồm chi phí nghiên cứu và phát triển, bao gồm các chi phí cho các thí nghiệm ban đầu và việc tinh chỉnh mô hình dẫn đến sản phẩm cuối cùng. Nó cũng bao gồm chi phí nhân sự, bao gồm lương và phúc lợi cho các nhà nghiên cứu, kỹ sư và nhân viên hỗ trợ. Chi phí cơ sở hạ tầng, chẳng hạn như đầu tư vào trung tâm dữ liệu, hệ thống làm mát và thiết bị mạng, cũng rất đáng kể. Ngoài ra, phần mềm và công cụ, bao gồm giấy phép và dịch vụ đám mây, cũng góp phần vào chi phí tổng thể. Chi phí năng lượng trong suốt vòng đời phát triển, không chỉ trong lần đào tạo cuối cùng, và chi phí cơ hội—doanh thu tiềm năng bị mất do không theo đuổi các dự án khác—cũng là các thành phần quan trọng. Hiểu rõ các chi phí này cung cấp cái nhìn toàn diện hơn về tầm ảnh hưởng kinh tế của việc phát triển các hệ thống ML tiên tiến, hỗ trợ ra quyết định chiến lược về phân bổ nguồn lực.
Các kết quả nghiên cứu cho thấy chi phí đào tạo ML sẽ tiếp tục tăng, nhưng tốc độ tăng trưởng có thể chậm lại trong tương lai. Báo cáo ước tính rằng chi phí đào tạo ML đã tăng khoảng 2,8 lần mỗi năm đối với tất cả các hệ thống. Đối với các hệ thống có việc mở rộng quy mô, tốc độ tăng trưởng chậm hơn, khoảng 1,6 lần mỗi năm. Sự gia tăng đáng kể hàng năm về chi phí đào tạo nhấn mạnh nhu cầu cải thiện hiệu quả đáng kể cả về phần cứng và phương pháp đào tạo để quản lý chi phí trong tương lai một cách hiệu quả.
Báo cáo dự báo rằng nếu xu hướng hiện tại tiếp tục, chi phí cho các phiên đào tạo đắt đỏ nhất có thể vượt qua các ngưỡng kinh tế quan trọng, như 1% GDP của Mỹ, trong vài thập kỷ tới. Điều này ngụ ý rằng nếu không có cải thiện hiệu quả, gánh nặng kinh tế của việc phát triển các hệ thống AI tối tân sẽ tăng đáng kể. Do đó, việc hiểu và quản lý các chi phí này là thiết yếu để đảm bảo sự phát triển bền vững của năng lực AI và duy trì một cách tiếp cận cân bằng đối với đầu tư và phát triển AI.
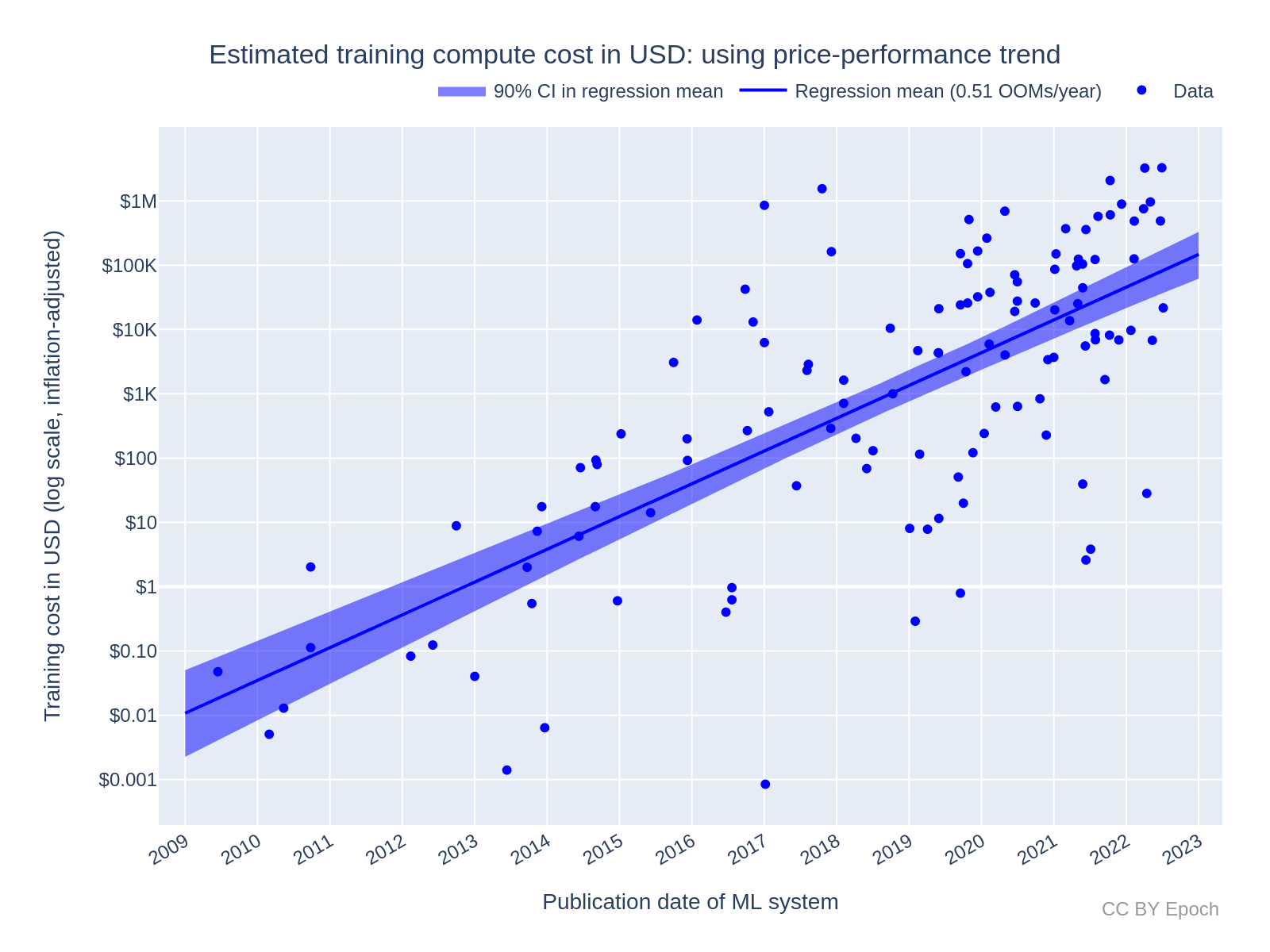
Chi phí khả năng điện toán ước tính bằng đô la Mỹ cho lần đào tạo cuối cùng của các hệ thống ML. (Epoch AI, 2023)