
Khác với việc lợi dụng sai mục đích, nơi ý định của con người là nguyên nhân gây hại, an toàn AI chủ yếu liên quan đến hành vi của chính hệ thống AI. Vấn đề cốt lõi là sự đồng bộ và kiểm soát: đảm bảo rằng các hệ thống có năng lực cao, tiềm năng tự chủ này hiểu và theo đuổi các mục tiêu phù hợp với giá trị và ý định của con người, thay vì phát triển và hành động dựa trên các mục tiêu mất căn chỉnh có thể dẫn đến hậu quả thảm khốc.
Phần này khám phá các chiến lược an toàn cho AGI, như đã giải thích trong phần định nghĩa, bao gồm nhưng không giới hạn ở việc đồng bộ hóa. Chúng tôi phân biệt các chiến lược an toàn áp dụng cho AGI ở mức độ con người với các chiến lược an toàn đảm bảo an toàn cho chúng ta khỏi ASI. Phần này tập trung vào前者, và phần tiếp theo sẽ tập trung vào ASI.
Các chiến lược an toàn cho AGI hoạt động dưới những ràng buộc cơ bản khác biệt so với các tiếp cận đối với ASI. Khi đối phó với các hệ thống có trí tuệ gần ngang tầm con người, chúng ta có thể lý thuyết duy trì năng lực giám sát có ý nghĩa và có thể lặp lại các biện pháp an toàn thông qua thử nghiệm và sai sót. Con người vẫn có thể đánh giá đầu ra, hiểu quá trình suy luận và cung cấp phản hồi để cải thiện hành vi của hệ thống AI. Điều này tạo ra các cơ hội chiến lược sẽ biến mất khi tính tổng quát và năng lực của AI vượt qua khả năng hiểu biết của con người trong hầu hết các lĩnh vực. Có tranh luận về việc liệu bất kỳ chiến lược an toàn nào được thiết kế cho AGI ở mức độ con người có tiếp tục hoạt động cho siêu trí tuệ hay không.
Các chiến lược an toàn cho AGI và ASI thường bị nhầm lẫn, xuất phát từ sự không chắc chắn về thời gian chuyển đổi. Thời gian chuyển đổi là chủ đề tranh luận sôi nổi trong nghiên cứu AI. Một số nhà nghiên cứu dự đoán sự gia tăng nhanh chóng về năng lực, có thể rút ngắn thời gian mà AI duy trì mức độ trí tuệ con người xuống còn vài tháng thay vì vài năm (Soares, 2022; Yudkowsky, 2022; Kokotajlo et al., 2025). Nếu quá trình chuyển đổi từ trí tuệ ở mức độ con người sang trí tuệ siêu việt diễn ra nhanh chóng, các chiến lược cụ thể cho AGI có thể không có thời gian để triển khai. Tuy nhiên, nếu chúng ta có một khoảng thời gian đáng kể mà AI vẫn ở mức độ con người, chúng ta có các lựa chọn an toàn mà không tồn tại ở mức độ siêu trí tuệ, khiến sự phân biệt này trở nên quan trọng cho các cân nhắc chiến lược.
Những người mới khám phá lĩnh vực điều chỉnh thường đề xuất nhiều giải pháp đơn giản. Tuy nhiên, không có chiến lược đơn giản nào chịu được sự phê phán. Dưới đây là một số ví dụ.
Luật Asimov. Đây là một bộ quy tắc hư cấu do nhà văn khoa học viễn tưởng Isaac Asimov đề xuất để quản trị hành vi của robot.
Các Luật Công nghệ Robot của Asimov có vẻ đơn giản và toàn diện khi nhìn qua, nhưng trên thực tế, chúng quá đơn giản và mơ hồ để xử lý sự phức tạp của các tình huống thực tế, đặc biệt là khi tổn thương có thể mang tính chất phức tạp và phụ thuộc vào ngữ cảnh (Hendrycks et al., 2022). Ví dụ, Luật Thứ nhất cấm robot gây hại, nhưng "hại" ở đây có nghĩa là gì? Nó chỉ đề cập đến tổn thương vật lý, hay còn bao gồm tổn thương tâm lý hoặc cảm xúc? Và robot nên ưu tiên các lệnh mâu thuẫn như thế nào nếu chúng có thể dẫn đến tổn hại? Sự thiếu rõ ràng này có thể gây ra phức tạp (Bostrom, 2016), ngụ ý rằng việc có một danh sách quy tắc hoặc tiên đề là không đủ để đảm bảo an toàn cho hệ thống AI. Các quy luật của Asimov là không phù hợp, và đó là lý do tại sao kết thúc câu chuyện của Asimov không diễn ra tốt đẹp.^ Một cách tổng quát hơn, việc thiết kế một bộ quy tắc hoàn hảo mà không có lỗ hổng là rất khó khăn. Xem chương về "tận dụng kẽ hở thông số" để biết thêm chi tiết.
^ Điều quan trọng cần lưu ý là sự phê phán này phù hợp với ý định của chính Asimov chứ không trái ngược với chúng. Mục đích của mỗi câu chuyện trong “I, Robot” chính là trình bày các kịch bản khả thi trong đó các luật bị phá vỡ. Asimov nhận thức rõ ràng về những hạn chế của đạo đức được ngụ ý bởi các luật của ông, và ông đã khám phá những hạn chế này một cách kỹ lưỡng trong các tiểu thuyết robot của mình như “The Caves of Steel,” “The Naked Sun” và “The Robots of Dawn.” Trong tiểu thuyết robot cuối cùng của mình, “Robots and Empire“, Asimov thậm chí còn giới thiệu “Luật Thứ Không“ như một phương pháp tiềm năng để đối phó với trí tuệ nhân tạo siêu trí tuệ: ngăn chặn robot thực hiện bất kỳ hành động nào có thể dẫn đến sự hủy diệt của nhân loại nói chung, ngay cả khi điều đó có nghĩa là hy sinh cuộc sống của một số cá nhân.
Thiếu vắng hình thể. Việc giữ cho AI không có hình thể có thể hạn chế các loại tổn hại trực tiếp mà chúng có thể gây ra. Tuy nhiên, AI không có hình thể vẫn có thể gây hại thông qua các phương tiện kỹ thuật số. Ví dụ, ngay cả khi một mô hình ngôn ngữ lớn (LLM) có khả năng không có cơ thể, nó vẫn có thể tự nhân bản (Wijk, 2023), tuyển dụng đồng minh con người, điều khiển từ xa thiết bị quân sự, kiếm tiền thông qua giao dịch định lượng, v.v… Cũng cần lưu ý rằng ngày càng có nhiều robot hình người được sản xuất, do đó việc thiếu cơ thể vật lý cũng khó áp dụng trong thực tế.
Nuôi dưỡng nó như một đứa trẻ. AI, khác với một đứa trẻ con người, thiếu các cấu trúc do tiến hóa tạo ra, vốn là yếu tố quan trọng cho việc học tập và phát triển đạo đức (Miles, 2018). Ví dụ, não bộ con người bình thường có các cơ chế để tiếp thu các chuẩn mực xã hội và hành vi đạo đức, điều mà AI hoặc những kẻ tâm thần phân liệt (biết đúng sai nhưng không quan tâm) không có (Cima et al, 2010). Các cơ chế này đã được phát triển qua hàng nghìn năm tiến hóa (Miles, 2018). Chúng ta không biết cách thực hiện chiến lược này vì chúng ta không biết cách tạo ra một AGI có cấu trúc não bộ (Byrnes, 2022). Cũng đáng lưu ý rằng trẻ em con người, dù được giáo dục tốt, cũng không phải lúc nào cũng hành động phù hợp với lợi ích và giá trị chung của nhân loại.
Năm 2023, một số nhà nghiên cứu về sự đồng bộ đã công bố bài viết "AI dễ kiểm soát". Pope & Belrose (2023) là đại diện cho quan điểm này, ước tính rủi ro từ AI (x-risk) chỉ ở mức 1%. Một trong những lý do họ đưa ra là AI là một "hộp trắng" có thể truy cập vào các thành phần bên trong (Optimists, 2023). Quan điểm lạc quan rằng "kiểm soát AI dễ dàng" dựa trên một số quan sát về các hệ thống AI hiện tại, đặc biệt là các mô hình ngôn ngữ lớn (LLMs). Những người ủng hộ lập luận rằng các hệ thống AI mang lại nhiều ưu điểm so với con người: chúng có thể được đặt lại, chúng ta có thể quan sát trạng thái bên trong của chúng, chúng ta có thể kiểm soát trực tiếp dữ liệu đào tạo của chúng và có thể điều chỉnh trọng số của chúng thông qua gradient descent. Những tính năng này dường như cung cấp các công cụ mạnh mẽ để đảm bảo sự đồng bộ.
Bài viết của họ đã gặp phải nhiều phản biện. Các nhà phê bình chỉ ra sự khó khăn trong việc xác định các giá trị phức tạp của con người, tiềm năng của các mục tiêu phát sinh, và thách thức của việc tổng quát hóa ngoài phân phối (Byrnes, 2023). Khả năng kiểm soát ở cấp độ kỹ thuật không đảm bảo an toàn khi triển khai, vì áp lực kinh tế và cạnh tranh có thể dẫn đến việc tạo ra các hệ thống có mục tiêu ngày càng tự chủ. Thứ hai, nhiều lập luận kiểm soát AI hiện nay giả định các đặc điểm kiến trúc cụ thể của các hệ thống AI hiện tại, có thể không áp dụng cho các thiết kế tương lai. Ví dụ, AGI giống não bộ thực hiện học tập trực tuyến liên tục sẽ vô hiệu hóa nhiều giả định an toàn hiện tại.
Nhiều tranh luận xuất phát từ lập luận "White Box". Những người lạc quan thường nhấn mạnh rằng các mô hình AI là "hộp trắng" (chúng ta có thể kiểm tra trọng số và kiến trúc của chúng) khác với "hộp đen" là não người. Byrnes phản bác rằng sự phân biệt này, mặc dù đúng về mặt thực tế về khả năng truy cập, có thể gây hiểu lầm. Ông cho rằng tranh luận về các thuật ngữ này là không hiệu quả. Mặc dù chúng ta có thể truy cập vào các thành phần bên trong của AI, khác với não bộ, việc hiểu tại sao AI hành động theo cách nhất định dựa trên các thành phần đó vẫn vô cùng khó khăn, có thể mất hàng thập kỷ nghiên cứu (khác với việc gỡ lỗi phần mềm truyền thống hoặc hiểu các hệ thống được thiết kế). Do đó, việc đơn giản khẳng định "AI là hộp trắng" là cơ sở ngây thơ để tin tưởng vào khả năng kiểm soát AI; thách thức về khả năng diễn giải vẫn còn rất lớn, việc truy cập dễ dàng vào các trọng số của AI vẫn chưa đủ để giải quyết các lỗ hổng bảo mật trong thực tế hoặc tránh các sự cố như BingChat đe dọa người dùng.
Ngay cả việc định nghĩa yêu cầu cho một giải pháp đồng bộ hóa vẫn còn gây tranh cãi giữa các nhà nghiên cứu. Trước khi khám phá các con đường tiềm năng hướng tới các giải pháp đồng bộ hóa, chúng ta cần xác định những gì các giải pháp thành công nên đạt được. Thách thức là chúng ta thực sự không biết chúng nên trông như thế nào - có sự không chắc chắn và bất đồng lớn trong lĩnh vực này. Tuy nhiên, một số yêu cầu dường như tương đối đồng thuận (Christiano, 2017):
^: Các Mức Độ Sẵn Sàng Công Nghệ (Technology Readiness Levels) của NASA là thang đo từ 1 đến 9 để đánh giá mức độ trưởng thành của một công nghệ. Mức 1 đại diện cho giai đoạn phát triển công nghệ ban đầu, đặc trưng bởi các nguyên lý cơ bản được quan sát và báo cáo, trong khi mức 9 đại diện cho công nghệ đã được chứng minh thông qua các hoạt động nhiệm vụ thành công.
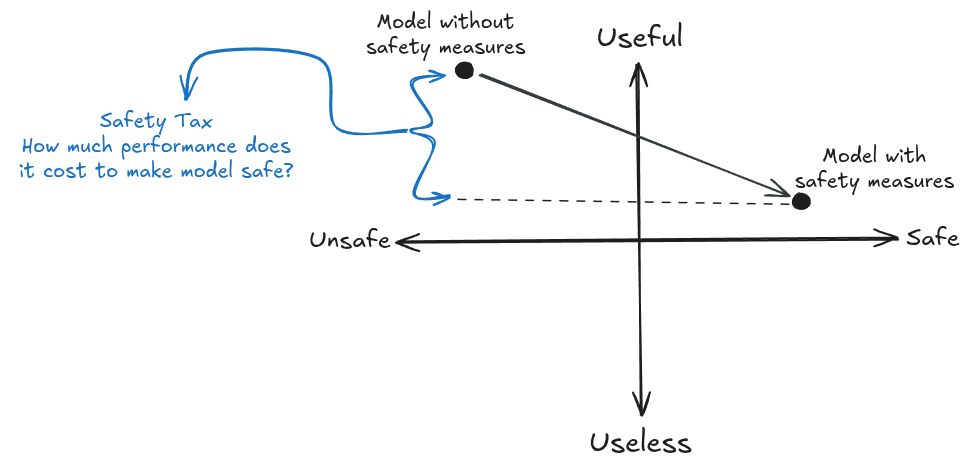
Hình minh họa cách áp dụng kỹ thuật an toàn hoặc căn chỉnh có thể làm giảm năng lực của mô hình. Điều này được gọi là "chi phí an toàn".
Các kỹ thuật điều chỉnh AGI hiện có không đáp ứng được các yêu cầu này. Nghiên cứu dựa trên thực nghiệm đã chỉ ra rằng các hệ thống AI có thể thể hiện các hành vi đáng lo ngại, trong khi nghiên cứu điều chỉnh hiện tại không đáp ứng được các yêu cầu này. Chúng ta đã có các minh chứng rõ ràng về việc các mô hình tham gia vào hành vi gian lận (Baker et al., 2025; Hubinger et al., 2024), căn chỉnh giả trong quá trình đào tạo trong khi lập kế hoạch hành vi khác trong quá trình triển khai (Greenblatt et al., 2024), tận dụng kẽ hở thông số (Bondarenko et al., 2025), tận dụng các đánh giá để trông có vẻ có năng lực hơn so với thực tế (OpenAI, 2024; SakanaAI, 2025), và trong một số trường hợp, cố gắng vô hiệu hóa các cơ chế giám sát hoặc trích xuất trọng số của chính mình (Meinke et al., 2024). Các kỹ thuật điều chỉnh hiện tại như RLHF và các biến thể của nó (Constitutional AI, Direct Preference Optimization, tinh chỉnh và các sửa đổi khác của RLHF) là mong manh và dễ vỡ (Casper et al., 2023) và nếu không có sự bổ sung, chúng sẽ không thể loại bỏ các năng lực nguy hiểm như lừa dối. Các chiến lược giải quyết sự đồng bộ không chỉ không thể ngăn chặn các hành vi này mà thường thậm chí không thể phát hiện khi chúng xảy ra (Hubinger et al., 2024; Greenblatt et al., 2024).
Giải quyết vấn đề đồng bộ hóa có nghĩa là chúng ta cần làm việc nhiều hơn để đáp ứng tất cả các yêu cầu này. Hạn chế của các kỹ thuật hiện tại chỉ ra các lĩnh vực cụ thể cần có đột phá. Tất cả các chiến lược đều hướng đến tính khả thi kỹ thuật và thuế căn chỉnh thấp, do đó đây là các yêu cầu chung, tuy nhiên một số chiến lược tập trung vào các mục tiêu cụ thể hơn mà chúng ta sẽ khám phá qua các chương sau. Dưới đây là danh sách ngắn các mục tiêu chính của nghiên cứu đồng bộ hóa:
Chiến lược tổng thể yêu cầu ưu tiên nghiên cứu an toàn hơn phát triển năng lực. Do khoảng cách đáng kể giữa các kỹ thuật hiện tại và yêu cầu, phương pháp chung bao gồm tăng đáng kể kinh phí cho nghiên cứu điều chỉnh trong khi kiềm chế phát triển năng lực khi các biện pháp an toàn vẫn chưa đủ so với năng lực của hệ thống.
Lợi dụng sai mục đích AI và AI phản loạn có thể là cùng một kịch bản về kết quả, mặc dù điểm khác biệt duy nhất là trong trường hợp mất căn chỉnh, yêu cầu ban đầu gây hại không đến từ con người mà từ AI. Nếu chúng ta xây dựng một hệ thống AI có thể kích hoạt mang tính rủi ro tồn vong, nó có thể bị kích hoạt bất kể người khởi xướng là con người hay nhân tạo (Shapira, 2025).
Tuy nhiên, các mối đe dọa này có thể khác biệt về mặt chiến lược. Nhà phát triển AI có thể ngăn chặn việc lợi dụng sai mục đích bằng cách không có ý đồ xấu và ngăn chặn những người có ý đồ xấu sử dụng hệ thống của họ. Với AI phản loạn, việc nhà phát triển có tốt hay ai có quyền truy cập không quan trọng - mối đe dọa phát sinh từ mục tiêu nội bộ hoặc quá trình ra quyết định của hệ thống chứ không phải ý định của con người.
Coup do AI hỗ trợ so với việc AI chiếm quyền kiểm soát đại diện cho một mối quan ngại an toàn quan trọng. Tom Davidson và các đồng nghiệp trình bày một kịch bản rủi ro đáng lo ngại (Davidson, 2025): rằng các hệ thống AI tiên tiến có thể cho phép một nhóm nhỏ người - thậm chí chỉ một người - chiếm quyền kiểm soát chính phủ thông qua một cuộc đảo chính. Các tác giả cho rằng rủi ro này có tầm quan trọng tương đương với việc AI chiếm quyền kiểm soát nhưng lại bị thiếu quan tâm nhiều hơn trong các cuộc thảo luận hiện nay. Mối đe dọa này tương tự như mối đe dọa chiếm quyền kiểm soát AI, với điểm khác biệt chính là quyền lực được chiếm đoạt bởi chính AI hay bởi con người điều khiển AI.
Các biện pháp bảo vệ chung có thể bảo vệ chống lại cả hai kịch bản. Nhiều biện pháp giảm thiểu tương tự có thể giải quyết cả hai rủi ro, bao gồm kiểm toán sự phù hợp, minh bạch về năng lực, giám sát hoạt động AI và các biện pháp an ninh thông tin mạnh mẽ để ngăn chặn cả kiểm soát độc hại của con người hoặc hành vi gây hại tự động.
Một số biện pháp giảm thiểu tập trung cụ thể vào rủi ro của các cuộc đảo chính được hỗ trợ bởi AI. Báo cáo kết luận với các khuyến nghị cụ thể dành cho nhà phát triển AI và chính phủ, bao gồm thiết lập quy tắc cấm hệ thống AI hỗ trợ các cuộc đảo chính, cải thiện tuân thủ các thông số kỹ thuật của mô hình, kiểm toán về lòng trung thành bí mật, triển khai an ninh thông tin mạnh mẽ, chia sẻ thông tin về năng lực, phân phối quyền truy cập cho nhiều bên liên quan và tăng cường giám sát các dự án AI tiên tiến.
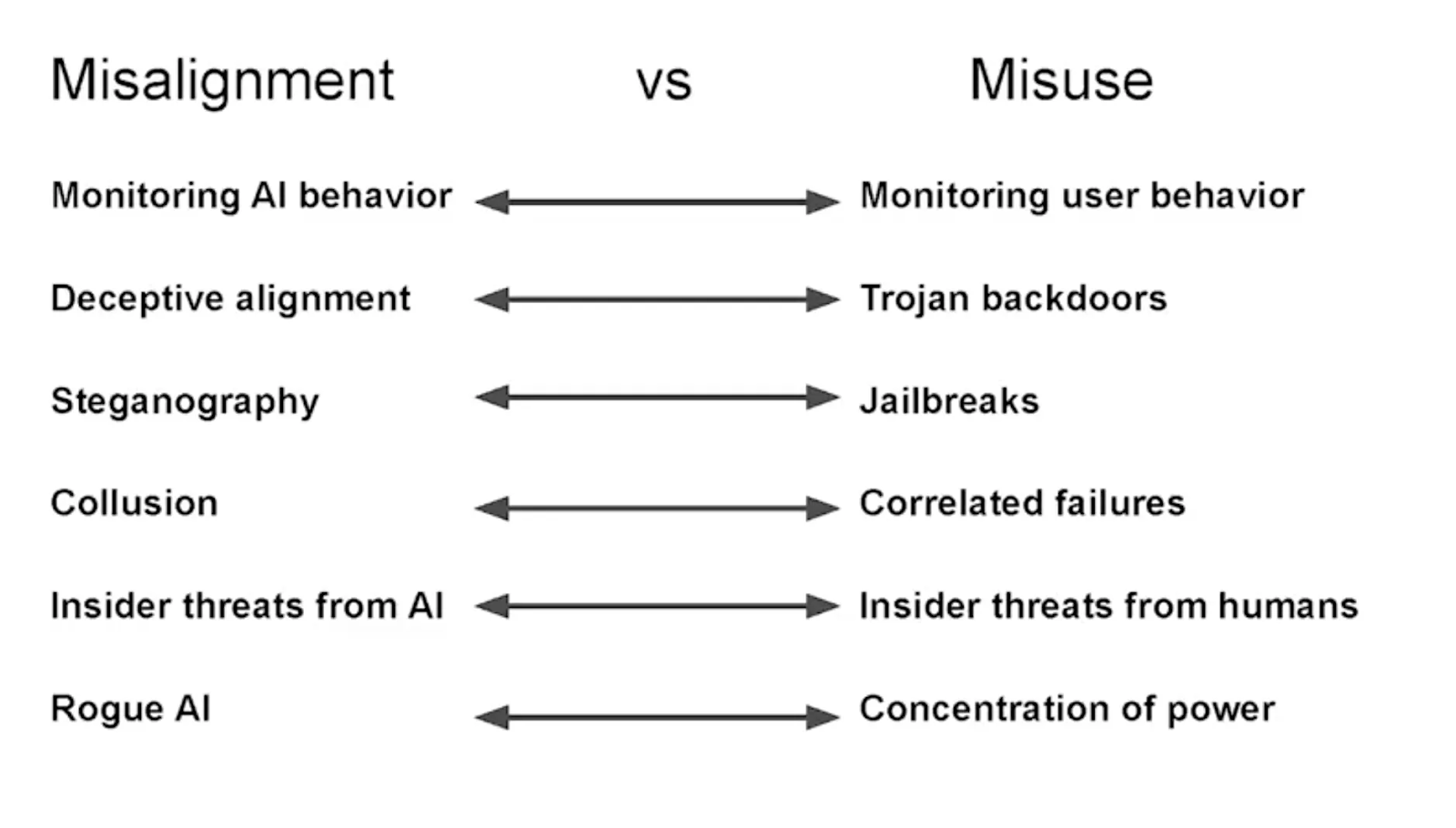
Theo Richard Ngo, sự phân biệt giữa rủi ro mất căn chỉnh và rủi ro lợi dụng sai mục đích từ AI có thể thường không hữu ích. Thay vào đó, chúng ta nên tập trung vào các "liên minh mất căn chỉnh" giữa con người và AI, từ các nhóm khủng bố đến các quốc gia độc tài. Trang trình bày từ (Ngo, 2024).
Nếu việc đồng bộ hóa trở nên khó khăn, những cơ chế nào có thể được triển khai để giám sát và kiểm soát các hệ thống AI mạnh mẽ, ngăn chặn các kết quả thảm khốc ngay cả từ các tác nhân mất căn chỉnh?
Trí tuệ nhân tạo (AI) có tác động biến đổi có nghĩa là “Có khả năng giảm đáng kể rủi ro từ AI nếu được triển khai đầy đủ, có thể bằng cách tăng tốc nghiên cứu và phát triển (R&D) cùng một số tác vụ khác với tỷ lệ lớn (có thể lên đến 30 lần)”. Trích dẫn từ (Greenblatt & Shlegeris, 2024) - hình minh họa do chúng tôi cung cấp;
Do tính dễ bị tổn thương của các kỹ thuật điều chỉnh, một phương pháp để nâng cao an toàn là kiểm soát các mô hình AI bằng cách hạn chế việc sử dụng các mô hình nguy hiểm nhất trong các môi trường được giám sát để ngăn chúng gây ra thảm họa, rò rỉ dữ liệu hoặc chiếm quyền kiểm soát trung tâm dữ liệu (Shlegeris, 2022). Phương pháp này thường giả định một kịch bản tồi tệ nhất, trong đó AI có thể chủ động lừa dối hoặc tìm kiếm quyền lực.
Một vấn đề trung tâm trong nghiên cứu kiểm soát là "scheming" – AI chiến lược che giấu mục tiêu thực sự (mất căn chỉnh) của mình trong quá trình đào tạo hoặc đánh giá, chỉ để theo đuổi chúng sau khi được triển khai, có thể tìm kiếm quyền lực hoặc chống lại việc tắt máy (Greenblatt, 2025). Đánh giá khả năng xảy ra scheming và cách chúng ta có thể cập nhật dựa trên bằng chứng trong tương lai vẫn còn khó khăn tính đến năm 2025 (Greenblatt, 2025). Các nghiên cứu thực nghiệm cho thấy các mô hình tiên tiến hiện nay có năng lực gian lận trong bối cảnh cụ thể (lý luận gian lận khi được tạo câu lệnh với mục tiêu và bối cảnh), dù không nhất thiết có xu hướng bẩm sinh (Hobbhahn et al., 2024). ^ Chúng ta có nhiều thông tin hơn về gian lận và lừa dối trong các chương về đánh giá và tổng quát lệch mục tiêu.
^: Các mô hình trong thí nghiệm này được tạo câu lệnh lập kế hoạch gian lận.
Đảm bảo kiểm soát ngay cả khi không có sự đồng bộ mạnh mẽ. Như đã thấy trong phần định nghĩa, có sự phân biệt quan trọng giữa kiểm soát (nhằm ngăn chặn AI "ra khỏi hộp" - và nói chung ngăn chặn AI gây ra thảm họa) ngay cả khi nó cố gắng, và đồng bộ (nhằm khiến AI muốn ở lại trong hộp). Chiến lược này nhằm giữ các hệ thống AI nguy hiểm dưới sự kiểm soát ngay cả khi chúng không hoàn toàn "đồng bộ". Các phòng thí nghiệm có thể cần các AI mạnh mẽ/nguy hiểm cho một số trường hợp sử dụng (ví dụ: nghiên cứu các đặc tính đồng bộ của các AI có năng lực hoặc thực hiện nghiên cứu với chúng, v.v.). Chương trình kiểm soát AI nhắm đến các mô hình có năng lực nguy hiểm và hành vi lừa dối (hoặc ít nhất là bề ngoài đồng bộ).
Kiểm soát có thể không khả thi trên quy mô lớn nhưng vẫn có thể thực hiện được và bổ sung cho việc điều chỉnh. Lịch sử cho thấy việc kiểm soát các siêu trí tuệ độc hại được coi là không thể, ví dụ như một siêu trí tuệ có thể thuyết phục các người giám sát cho phép nó thoát khỏi hộp. Các thí nghiệm trên con người đã cho thấy rằng thực sự có thể thuyết phục một số người khác cho phép họ thoát ra sau một cuộc thảo luận dài (Yudkowsky, 2002; Yudkowsky, 2008). Chúng ta do đó giả định rằng việc kiểm soát các siêu trí tuệ là cực kỳ phức tạp. Tuy nhiên, điều này không có nghĩa là không thể khai thác lao động trí tuệ từ các AI không phải là siêu trí tuệ vượt trội.
Đánh giá xem AI có gian lận hay không là một thách thức. Vấn đề chính là với các kỹ thuật hiện tại, không thể xác định liệu AI có được căn chỉnh hay chỉ đơn giản là hành xử tốt trong khi chờ thời cơ. Việc phân biệt này dường như khó khăn đối với các AI có khả năng cao và nhận thức tình huống (xem chương về rủi ro). Điều này có thể thay đổi trong tương lai với các kỹ thuật cho phép kiểm tra nội bộ của mô hình, nhưng hiện tại, các kỹ thuật này vẫn chưa khả dụng.
So sánh với việc đánh giá năng lực của AI, việc này dễ dàng hơn. Nếu AI không thể thực hiện nhiệm vụ ngay cả sau khi đã tinh chỉnh nó để làm điều đó, bạn có thể chắc chắn rằng AI chưa có năng lực thực hiện nhiệm vụ đó. Ngay cả khi AI có khả năng nhận thức tình huống và giấu giếm năng lực của mình, nó không thể chống lại áp lực tối ưu hóa (trừ khi có các thủ thuật khám phá và các đặc điểm khác (Hubinger, 2023)). Do đó, đánh giá giới hạn trên của năng lực không dễ dàng, nhưng ít nhất cũng dễ hơn so với đánh giá sự phù hợp. Các đánh giá cụ thể, như những đánh giá được thực hiện bởi nhóm Nghiên cứu Đánh giá Mô hình và Đe dọa (METR) để kiểm tra khả năng tự nhân bản và thích ứng (METR, 2023), dường như là những bước đầu tiên hợp lý để đánh giá sức mạnh của các AI hiện tại. Các đánh giá được thiết kế cụ thể để xác định liệu chúng ta có kiểm soát được AI hay không được gọi là "đánh giá kiểm soát". Xem chương về Đánh giá để biết thêm thông tin. Tóm lại, điều này liên quan đến thử nghiệm đối kháng, trong đó một "đội đỏ" (đại diện cho AI có thể mất căn chỉnh) cố gắng phá vỡ các biện pháp an toàn do "đội xanh" (đại diện cho nhà phát triển/người triển khai) thực hiện trong một môi trường đại diện được kiểm soát.
Các chiến lược đơn giản nhất để thiết lập kiểm soát là thiết kế một giao thức bảo mật bao gồm các yếu tố sau, ví dụ:
Vẫn còn nhiều vấn đề cần giải quyết, nhưng tóm lại, có vẻ khả thi để xác minh độ bền vững của một giao thức bảo mật thông qua các đánh giá kiểm soát bằng cách thực hiện các biện pháp phòng ngừa đối với các chế độ hỏng hóc khác nhau. Để có cái nhìn tổng quan về chương trình kiểm soát, chuỗi này là một điểm khởi đầu tốt.
Ngay cả chương trình kiểm soát cũng phải đối mặt với nhiều phê phán.
Jan Kulveit lập luận rằng việc kiểm soát AI mà không căn chỉnh chúng có thể giảm xác suất xảy ra một "thảm hoạ cảnh cáo" không gây tử vong cho tất cả mọi người (Kulveit, 2025). "I. Trong các thế giới mà chúng ta đang làm khá tốt về việc đồng bộ hóa, chương trình kiểm soát AI không có nhiều tầm ảnh hưởng. II. Trong các thế giới mà chúng ta thất bại trong việc đồng bộ hóa, kiểm soát AI có thể chủ yếu chuyển xác suất sang 'các vụ thảm hoạ cảnh cáo không hiệu quả' và 'thảm họa hiện sinh, chiếm quyền kiểm soát hoàn toàn'."
Bài viết "The Case Against AI Control Research" (Wentworth, 2025) lập luận rằng nghiên cứu kiểm soát AI, như được định nghĩa và thực hiện thông thường, chỉ giải quyết một phần nhỏ của rủi ro hiện sinh (X-risk) do trí tuệ nhân tạo gây ra. Wentworth cho rằng chúng ta sẽ không thể nhận ra một giải pháp tốt cho việc điều chỉnh. Tác giả cho rằng kịch bản thất bại khả dĩ nhất liên quan đến AI biến đổi sớm sản xuất ra các giải pháp sai lệch, đánh lừa hoặc sai lệch tinh vi ("slop") khi được giao nhiệm vụ giải quyết vấn đề điều chỉnh siêu trí tuệ. Các phòng thí nghiệm có thể vô tình chấp nhận các giải pháp sai lệch này do khó khăn trong việc xác minh, sự nịnh bợ AI, lỗi của nhà nghiên cứu hoặc vấn đề tổ chức, và sau đó tiếp tục xây dựng siêu trí tuệ mất căn chỉnh dựa trên chúng. Vì nghiên cứu kiểm soát tập trung hẹp vào việc AI ban đầu cố ý gian lận, nó không giải quyết được rủi ro lớn hơn do "slop" gây ra và thách thức trong việc đảm bảo AI ban đầu thực sự đóng góp vào việc giải quyết vấn đề căn chỉnh AI cho các hệ thống AI tiên tiến hơn, thay vì chỉ là một kẻ nịnh bợ siêu nhân thuyết phục con người rằng ý tưởng sai lệch của họ về cách căn chỉnh AI là đúng khi thực tế không phải vậy.
Cả hai lập luận đều có thể tranh luận, nhưng điểm chung là rất khó để đảm bảo rằng ngay cả những hướng nghiên cứu hứa hẹn cũng không thực sự mang lại tác động tiêu cực.
Mặc dù việc "boxing" có thể không khả thi, nó vẫn là một chiến lược thiếu quan tâm.
Nhiều người cho rằng việc cố gắng đóng hộp các AI mạnh mẽ là vô ích. Điều này thường được củng cố bởi các trường hợp trong đó con người, khi tham gia vào Thí nghiệm Nhốt AI, đã thành công trong việc thuyết phục người khác "giải phóng" chúng (Yudkowsky, 2002; Corwin, 2002). Những ví dụ lịch sử này cần được xem xét nghiêm túc.
AI có thể sử dụng các chiến thuật như hứa hẹn tài sản khổng lồ, quyền lực và trí tuệ cho những ai giải phóng chúng, khẳng định rằng chỉ có chúng mới có thể ngăn chặn các mối đe dọa tồn vong hoặc các lời kêu gọi cảm xúc khác.
Tuy nhiên, chúng tôi vẫn cho rằng có nhiều chiến lược có thể giảm đáng kể rủi ro từ AI thoát ra, ngay cả khi chúng ta thừa nhận rằng có một mức độ trí tuệ có thể không tránh khỏi việc thuyết phục bất kỳ nhóm con người nào giúp đỡ trong việc giải phóng nó. Việc kiểm soát có thể khả thi hơn việc đồng bộ hóa, đặc biệt ở giai đoạn trí tuệ tương đương con người. Có thể thiết kế các giao thức làm tăng đáng kể độ khó cho AI thoát ra khỏi hộp.
Việc "giam giữ" có thể được hình dung như một trò chơi đòi hỏi sự chuẩn bị. Chiến lược chung là chuẩn bị và không để AI chuẩn bị.
Các chiến lược giảm thiểu có thể bao gồm:
Nhiều chiến lược cụ thể hơn được liệt kê tại đây, và tóm tắt các cuộc thảo luận về chủ đề này có sẵn tại đây.
Liệu chúng ta có thể thiết kế hoặc khuyến khích các hệ thống AI thể hiện quá trình suy luận của mình dưới dạng dễ hiểu (như ngôn ngữ tự nhiên), từ đó cho phép giám sát hiệu quả hơn?
Theo dõi Chuỗi Suy luận (CoT) – các bước suy luận bằng ngôn ngữ tự nhiên được một số mô hình tạo ra – đã được nghiên cứu như một kỹ thuật kiểm soát và khả năng diễn giải cụ thể. Tính minh bạch đóng vai trò quan trọng trong cả việc đồng bộ hóa và kiểm soát.
Hy vọng rằng CoT cung cấp một cái nhìn vào quá trình "suy nghĩ" của AI, cho phép các nhà giám sát (con người hoặc AI) phát hiện ý đồ độc hại hoặc suy luận sai lệch trước khi các hành động gây hại xảy ra (OpenAI, 2025). OpenAI đã phát hiện ra rằng giám sát CoT hiệu quả trong việc phát hiện việc hack phần thưởng trong các tác vụ lập trình, đặc biệt khi nhà giám sát có thể xem CoT cùng với các hành động.
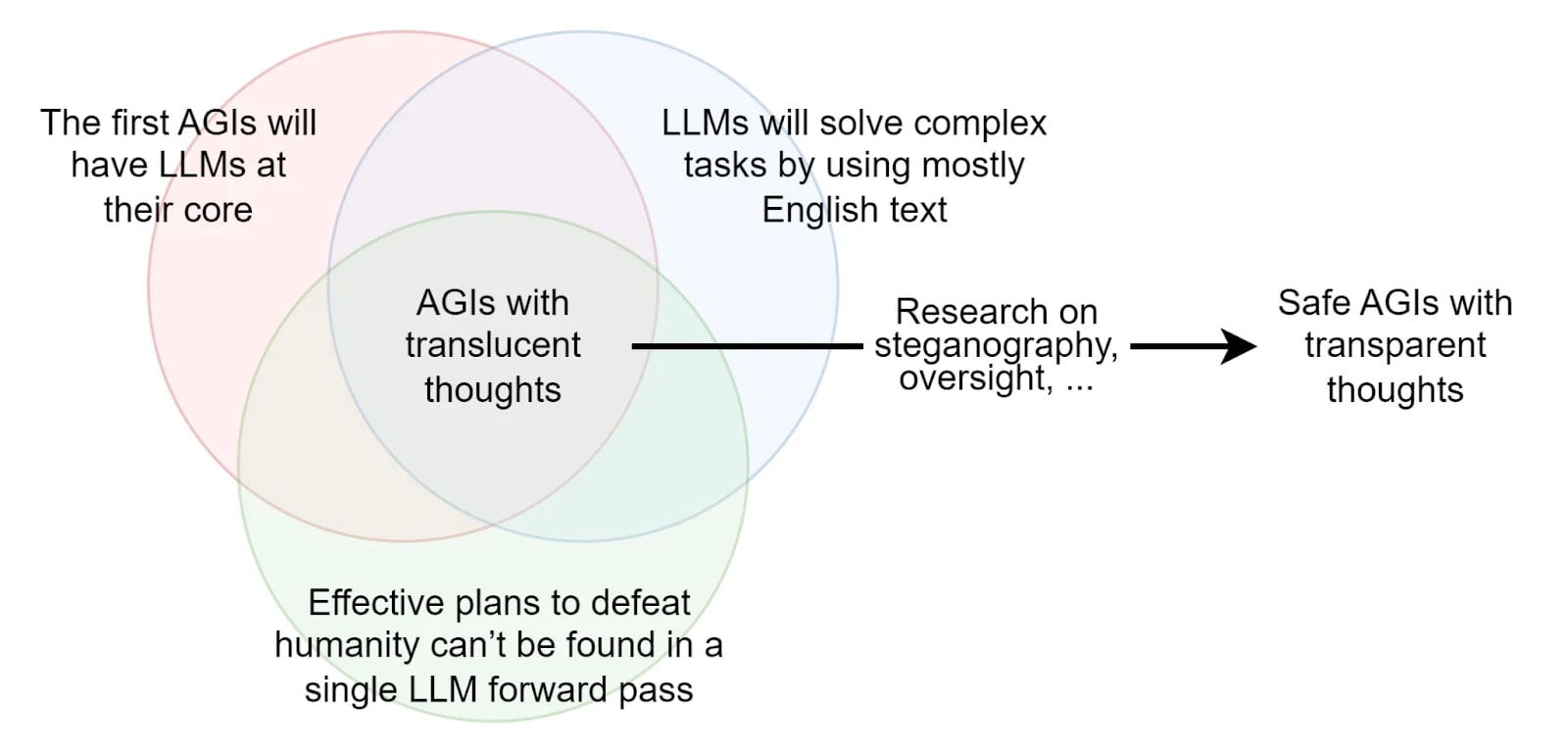
Hình từ "Các Giả thuyết về Suy nghĩ Trong Suốt và Hậu quả của Chúng" (Roger, 2023). Nếu AI mà chúng ta đang làm việc chỉ có thể suy luận qua các chuỗi suy nghĩ bằng tiếng Anh, thì việc giám sát suy nghĩ của nó trở nên dễ dàng hơn đáng kể.
Thật không may, phần lớn các AI không suy luận bằng tiếng Anh; ví dụ, AlphaGo suy luận bằng một ngôn ngữ hoàn toàn khác với tiếng Anh. Các mô hình ngôn ngữ lớn (LLMs), mặt khác, có năng lực suy luận bằng tiếng Anh, nhưng quá trình suy luận được ghi lại không phản ánh quá trình suy nghĩ cơ bản của chúng (Turpin et al., 2023).
Có lẽ việc căn chỉnh AI chỉ suy nghĩ bằng tiếng Anh và được huấn luyện trước trên văn bản do con người tạo ra sẽ dễ dàng hơn nhiều so với việc căn chỉnh các AGI được huấn luyện từ đầu bằng các phương pháp RL/tiến hóa, vì các kiến trúc sau này sẽ tạo ra ngôn ngữ riêng của chúng và hoàn toàn xa lạ. Giả sử một LLM không thể lập kế hoạch hủy diệt thế giới trong một lần xử lý duy nhất, thì khả thi rằng những AI này sẽ có thể được giám sát vì chúng ta có thể xem xét văn bản được tạo ra để phát hiện điều gì đó đáng ngờ. Bộ giả thuyết cần thiết để khẳng định rằng AGI đầu tiên sẽ có thể giám sát được nếu chúng ta chỉ xem xét quá trình suy luận của nó bằng tiếng Anh được mô tả trong bài viết: "The Translucent Thoughts Hypotheses and Their Implications" (Roger, 2023).
Có thể khuyến khích các mô hình ngôn ngữ lớn (LLMs) suy luận một cách rõ ràng hơn bằng tiếng Anh. Rõ ràng, bước đầu tiên là đào tạo chúng suy luận bằng tiếng Anh. Tuy nhiên, điều này vẫn chưa đủ. Huấn luyện LLMs suy luận bằng cách bỏ qua các bước khuyến khích chúng suy luận theo cách ẩn và không minh bạch, và điều này xảy ra một cách ngầm định khi chúng ta huấn luyện LLMs dự đoán token tiếp theo. Ngược lại, nếu chúng ta huấn luyện LLMs chi tiết hóa tất cả các bước suy luận của chúng, chúng ta có thể giảm bớt động lực cho suy luận ẩn. Phương pháp này còn được gọi là huấn luyện dựa trên quá trình, trong đó các hệ thống AI được huấn luyện để suy luận từng bước một, và chúng tôi mô tả chi tiết điều này trong chương về giám sát có thể mở rộng. Thật không may, lý luận trên không đơn giản; AI có thể học cách sử dụng suy luận ẩn ngay cả khi chúng được đào tạo để chi tiết hóa tất cả các bước suy luận trong quá trình đào tạo, chẳng hạn như steganography, hoặc với kiến trúc như COCONUT (xem bên dưới).^
^: Steganography là một ngôn ngữ mã hóa ẩn. Ví dụ, chữ cái đầu tiên của một câu sẽ cho biết chữ cái tiếp theo của thông điệp.
Một số kiến trúc AI ngăn cản chúng ta sử dụng chiến lược này hoàn toàn. Bài báo của Meta "Training Large Language Models to Reason in a Continuous Latent Space" (Hao, et al., 2024) trình bày một kiến trúc ngăn cản chúng ta đọc chuỗi suy luận từ các hệ thống AI. Nếu chúng ta muốn có thể theo dõi những gì đang xảy ra, có thể quan trọng là không sử dụng các kiến trúc này, ngay cả khi chúng cho phép tăng cường năng lực.
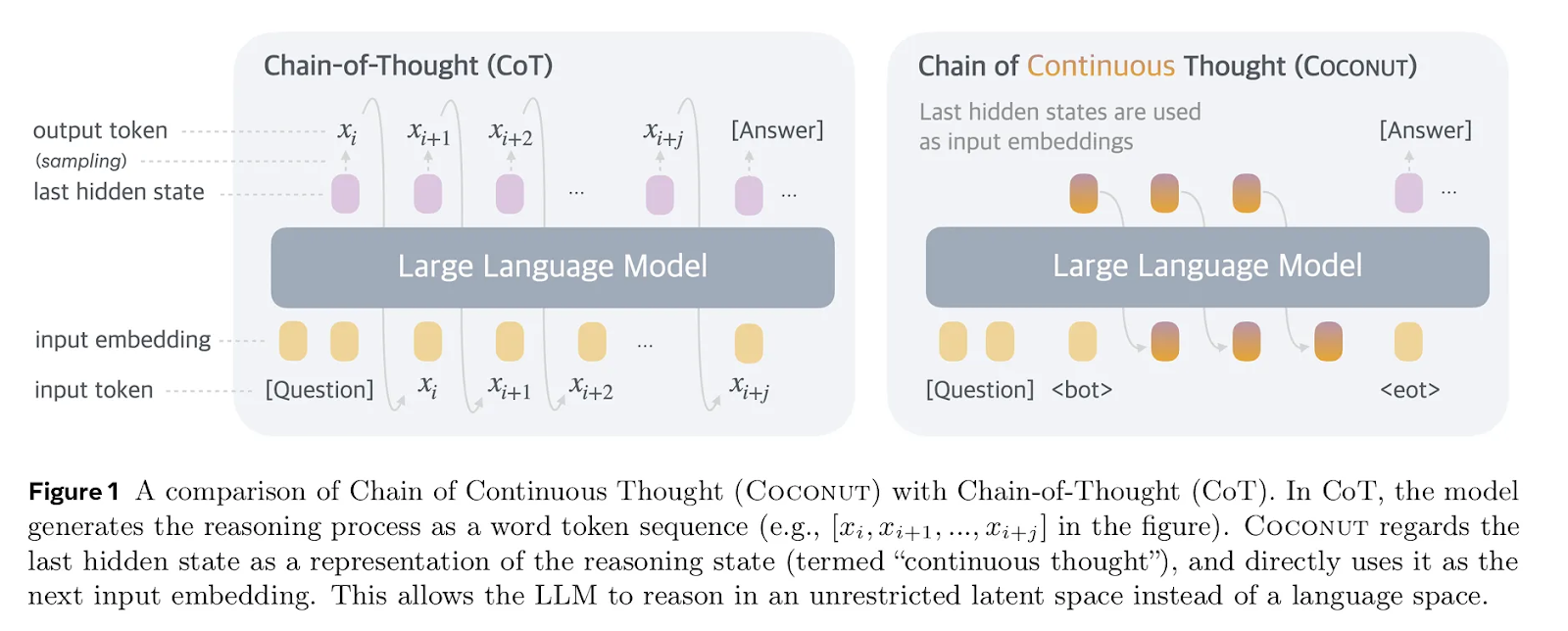
Hình 1 từ các bài báo COCONUT. (Hao et al., 2024)
Các kỹ thuật như diễn đạt lại có thể giúp ngăn chặn steganography, nhưng điều này đòi hỏi nhiều chi tiết phức tạp (Roger & Greenblatt, 2023).
Dưới đây là một số cách triển khai của chương trình tư duy minh bạch:
Tóm lại, chiến lược chung để tạo ra một AI an toàn từ thiết kế là đảm bảo rằng AI thể hiện suy luận của mình, giúp việc giám sát chuỗi suy luận dễ dàng hơn. Điều này có thể đơn giản hơn so với việc phân tích nội bộ mô hình thông qua khả năng diễn giải. Do đó, điều quan trọng là tránh xây dựng AI được đào tạo và khuyến khích để nội bộ hóa phần lớn suy luận của mình.
Hiện nay, chúng ta có nhiều bằng chứng cho thấy việc giám sát chuỗi suy luận (CoT) không hoàn toàn chính xác. Nghiên cứu của Anthropic đã chỉ ra rằng các mô hình thường không báo cáo chính xác quá trình suy luận của mình trong CoT, bỏ qua các yếu tố ảnh hưởng (như gợi ý) hoặc tạo ra các lý do không chính xác, đặc biệt khi được khuyến khích để "hack" (Anthropic, 2025). Điều này cho thấy CoT có thể không phải là chỉ số đáng tin cậy về quá trình suy luận thực sự của mô hình, đặc biệt dưới áp lực đối kháng. Cuộc tranh luận vẫn tiếp tục về việc liệu việc theo dõi CoT có thể được làm cho đủ mạnh mẽ để đảm bảo an toàn trong các tình huống có rủi ro cao hay không.
Tuy nhiên, một số nhà nghiên cứu cho rằng những phát hiện này không hoàn toàn phủ nhận tiềm năng của việc giám sát CoT trong việc phát hiện sự mất căn chỉnh phức tạp. Như Greenblatt (2025) đã chỉ ra, sự không trung thực được quan sát trong các nghiên cứu đó chủ yếu xảy ra trong các tình huống mà quá trình suy luận đủ đơn giản đến mức không cần thiết phải sử dụng CoT một cách rộng rãi. Các rủi ro không phù hợp nghiêm trọng hơn — như căn chỉnh giả, lạm dụng quá trình đào tạo hoặc lừa dối phức tạp — có thể yêu cầu các quá trình suy luận phức tạp có thể vẫn để lại dấu vết trong CoT. Các kết quả gây hại nghiêm trọng như cố gắng thoát khỏi hệ thống hoặc phá hoại nghiên cứu cũng đòi hỏi quá trình suy luận phức tạp có thể được phát hiện.
Tuy nhiên, một số yếu tố có thể cuối cùng hạn chế hiệu quả giám sát CoT trong các hệ thống tiên tiến. Những yếu tố này bao gồm các thay đổi kiến trúc cho phép xử lý tái phát mờ (thỉnh thoảng được gọi là "neuralese"), sự phát triển năng lực steganography có thể ẩn lý luận trong các đầu ra dường như vô hại, hoặc đơn giản là các bước tiến mạnh mẽ hơn yêu cầu ít lý luận rõ ràng hơn. Trong số này, sự phát triển khả năng lý luận mờ thông qua tái phát thần kinh có thể đại diện cho thách thức lớn nhất trong việc duy trì tính minh bạch cần thiết cho giám sát hiệu quả. Toàn bộ chương trình này phụ thuộc đáng kể vào giả thuyết rằng "Các kế hoạch hiệu quả để đánh bại nhân loại không thể được tìm thấy trong một lần chạy về phía trước của LLM". Khi AI trở nên quá mạnh trong một lần chạy về phía trước, hầu hết hy vọng về suy luận trong suốt sẽ biến mất, vì vậy hoặc bạn cần thành công trong CoEm tham vọng bằng cách xây dựng một cơ quan trong suốt siêu nhân khổng lồ, hoặc chúng ta cần các phương pháp tiếp cận mới. Đây là chủ đề của an toàn ASI.
Kỹ thuật cấm kỵ nhất là đào tạo AI bằng các kỹ thuật khả năng diễn giải. Thuật ngữ này được Zvi Mowshowitz đặt ra (Mowshowitz, 2025). Nghiên cứu của OpenAI cho thấy việc tối ưu hóa trực tiếp CoT cho an toàn (tức là phạt "suy nghĩ xấu") khiến các mô hình học cách che giấu lý luận lừa dối trong khi vẫn hành vi sai trái (OpenAI, 2025).
Một hệ thống AI tạo ra đầu ra cuối cùng [X] thông qua một phương pháp [M]. Bạn có thể phân tích [M] bằng kỹ thuật [T] để hiểu hệ thống AI đang làm gì. Bạn có thể đào tạo trên đó. Đừng bao giờ làm điều đó.
Bạn huấn luyện trên [X]. Chỉ [X]. Không bao giờ [M], không bao giờ [T].
Tại sao? Bởi vì [T] là cách bạn phát hiện khi mô hình hoạt động sai.
Nếu bạn huấn luyện trên [T], bạn đang huấn luyện AI để che giấu cách suy luận của nó và vô hiệu hóa [T]. Bạn sẽ nhanh chóng mất khả năng hiểu rõ những gì đang xảy ra, chính xác vào những lúc bạn cần hiểu rõ nhất.
Những áp lực tối ưu hóa từ [T] là vô cùng quý giá. Hãy sử dụng chúng một cách khôn ngoan.
- Zvi Mowshowitz