
[Nói về thời kỳ gần thời điểm tạo ra trí tuệ nhân tạo tổng quát (AGI) đầu tiên] bạn có động lực cạnh tranh nơi mọi người đều cố gắng vượt lên trước, và điều đó có thể đòi hỏi phải hy sinh yếu tố an toàn. Vì vậy, tôi nghĩ có thể cần sự phối hợp giữa các thực thể lớn đang thực hiện loại đào tạo này [...] Tạm dừng đào tạo thêm, hoặc tạm dừng triển khai, hoặc tránh các loại đào tạo mà chúng ta cho là có thể rủi ro hơn.
John Schulman, đồng sáng lập OpenAI
Chúng ta đã đề cập đến động lực chủng tộc trong chương về rủi ro từ AI như các yếu tố khuếch đại cho tất cả các rủi ro. Chúng ta nhắc lại điều này ở đây vì các sáng kiến quản trị có thể có ảnh hưởng đặc biệt để có thể giảm thiểu động lực chủng tộc.
Cạnh tranh thúc đẩy sự phát triển của AI ở mọi cấp độ. Từ các startup đua nhau chứng minh các năng lực mới đến các quốc gia coi lãnh đạo trong lĩnh vực AI là yếu tố thiết yếu cho sức mạnh tương lai, áp lực cạnh tranh định hình cách các hệ thống AI được xây dựng và triển khai. Động lực này tạo ra một tình huống căng thẳng tương tự như "trò chơi tù nhân", nơi mặc dù mọi người đều có lợi từ việc phát triển cẩn thận và tập trung vào an toàn, những ai hành động nhanh nhất lại giành được lợi thế cạnh tranh (Hendryks, 2024).

Cách tống tiền đối thủ và lợi ích bạn có thể thu được từ việc tống tiền (Stewart & Plotkin, 2012).
Cuộc đua AI tạo ra một vấn đề hành động tập thể. Ngay cả khi các nhà phát triển nhận thức được rủi ro, sự thận trọng đơn phương có nghĩa là nhường bước cho các đối thủ cạnh tranh thiếu đạo đức. Sự phát triển của OpenAI minh họa cho sự căng thẳng này: được thành lập như một tổ chức phi lợi nhuận nhỏ tập trung vào an toàn, áp lực cạnh tranh đã dẫn đến việc thành lập một công ty con có lợi nhuận và đẩy nhanh tiến độ triển khai. Khi đối thủ của bạn huy động hàng tỷ đô la và tung sản phẩm ra thị trường hàng tháng, việc dành thêm sáu tháng cho thử nghiệm an toàn cảm giác như đang tụt hậu không thể cứu vãn (Gruetzemacher et al., 2024). Động lực này khiến việc ưu tiên an toàn hơn tốc độ trở nên cực kỳ khó khăn đối với bất kỳ thực thể nào, dù là công ty hay quốc gia (Askell et al., 2019).
Áp lực cạnh tranh dẫn đến việc "làm đẹp an toàn", cắt giảm quy trình kiểm tra, bỏ qua việc kiểm tra độc lập từ bên ngoài và duy lý hóa sự kiện cảnh cáo. "Di chuyển nhanh và phá vỡ mọi thứ" trở thành phương châm ngầm, ngay cả khi những thứ bị phá vỡ có thể bao gồm các cam kết an toàn cơ bản. Chúng ta đã chứng kiến điều này với các mô hình được phát hành dù có lỗ hổng đã biết, được biện minh bằng nhu cầu duy trì vị thế thị trường. Các công ty niêm yết phải đối mặt với áp lực liên tục phải chứng minh tiến bộ cho nhà đầu tư. Mỗi bước đột phá của đối thủ trở thành mối đe dọa tồn tại đòi hỏi phản ứng ngay lập tức. Khi Anthropic phát hành Claude 3, OpenAI phải phản ứng với GPT-4.5. Khi Google trình diễn các năng lực mới, mọi người đều vội vàng bắt kịp. Cuộc đua theo quý này để lại ít không gian cho công việc an toàn cẩn thận có thể mất nhiều năm mới mang lại kết quả.

Số đơn đăng ký bằng sáng chế liên quan đến trí tuệ nhân tạo, năm 2019. Các bằng sáng chế được nộp tại văn phòng bằng sáng chế của quốc gia được chọn (Giattino et al., 2023).
Những lo ngại về an ninh quốc gia làm gia tăng động lực cạnh tranh. Khi Vladimir Putin tuyên bố "ai trở thành người dẫn đầu trong lĩnh vực trí tuệ nhân tạo sẽ trở thành người thống trị thế giới", ông đã thể hiện điều mà nhiều nhà hoạch định chính sách tin tưởng một cách riêng tư (AP News, 2017). Điều này biến sự phát triển trí tuệ nhân tạo từ một cuộc cạnh tranh thương mại thành một cuộc đấu tranh được cho là nhằm giành ưu thế địa chính trị. Hơn 50 quốc gia đã triển khai chiến lược AI quốc gia, thường xác định rõ ràng rằng sự lãnh đạo trong AI là yếu tố then chốt cho ưu thế kinh tế và quân sự (Stanford HAI, 2024; Stanford HAI, 2025). Khác với cuộc đua của các doanh nghiệp được đo lường bằng chu kỳ sản phẩm, cạnh tranh AI quốc tế liên quan đến vị thế chiến lược lâu dài. Tuy nhiên, một cách nghịch lý, điều này khiến cuộc đua trở nên cấp bách hơn: việc tụt hậu hôm nay có thể đồng nghĩa với bất lợi vĩnh viễn trong tương lai.

Số lượng tích lũy của các hệ thống AI quy mô lớn theo quốc gia kể từ năm 2017. Tham chiếu đến vị trí của tổ chức chính mà các tác giả của các hệ thống AI quy mô lớn liên kết (Giattino et al., 2023).
Áp lực cạnh tranh khiến hành động tập thể và phối hợp trở nên bất khả thi. Các quốc gia do dự trong việc áp dụng các quy định an toàn nghiêm ngặt có thể làm suy yếu ngành công nghiệp AI trong nước. Các công ty từ chối cam kết an toàn tự nguyện trừ khi đối thủ cạnh tranh cũng đưa ra cam kết tương tự. Mọi người đều chờ đợi người khác hành động trước, dẫn đến bế tắc ngay cả khi tất cả các bên đều thừa nhận rủi ro. Kết quả là một cách tiếp cận an toàn ở mức tối thiểu, không làm hài lòng ai.
Quản trị AI cần các tiếp cận sáng tạo để thoát khỏi động lực cạnh tranh. Kiểm soát vũ khí truyền thống chỉ mang lại bài học hạn chế, vì phát triển AI diễn ra trong các công ty tư nhân, không phải phòng thí nghiệm chính phủ. Chúng ta cần các tiếp cận mới (Trajano & Ang, 2023; Barnett, 2025). Một số ý tưởng đã được đề xuất. Một số ví dụ là:
Năng lực AI lan truyền toàn cầu qua các mạng kỹ thuật số với tốc độ khiến các cơ chế kiểm soát truyền thống trở nên hầu như vô hiệu. Khác với vũ khí hạt nhân yêu cầu vật liệu và cơ sở chuyên dụng, các mô hình AI là các mẫu số có thể sao chép và truyền tải tức thì. Hãy tưởng tượng kịch bản này - một mô hình AI tiên tiến, có năng lực tạo ra deepfake siêu thực hoặc thiết kế vũ khí sinh học mới, được phát triển bởi một phòng thí nghiệm nghiên cứu có ý định tốt. Phòng thí nghiệm, tuân thủ nguyên tắc khoa học mở, công bố kết quả nghiên cứu và phát hành mã nguồn của mô hình dưới dạng mã nguồn mở. Trong vòng vài giờ, mô hình được tải xuống hàng nghìn lần trên toàn cầu. Trong vài ngày, các phiên bản sửa đổi bắt đầu xuất hiện trên các nền tảng chia sẻ mã nguồn. Trong vài tuần, năng lực từng bị giới hạn trong một phòng thí nghiệm duy nhất đã lan rộng khắp internet, có thể truy cập bởi bất kỳ ai có máy tính và kết nối internet. Tình huống này, dù mang tính giả định, không xa rời thực tế. Sự khác biệt cơ bản này khiến các phương pháp kiểm soát phổ biến truyền thống gần như vô dụng trong quản trị AI.
Các bản phát hành mã nguồn mở phải đối mặt với những hạn chế phần cứng cơ bản tương tự như phát triển độc quyền. Mặc dù việc phát hành trọng số mô hình hoặc mã đào tạo có thể trông giống như việc dân chủ hóa năng lực AI, nhưng các yêu cầu về khả năng điện toán cơ bản mà chúng ta đã thảo luận trong suốt cẩm nang vẫn không thay đổi. Ngay cả khi có quyền truy cập vào trọng số của Llama, người dùng vẫn cần hàng trăm, nếu không muốn nói là hàng triệu đô la cho phần cứng chuyên dụng. Ngay cả việc tinh chỉnh các mô hình tiên tiến cho các tác vụ cụ thể cũng đòi hỏi các cụm GPU quy mô lớn, điều này vẫn nằm ngoài tầm với của phần lớn các cá nhân. Điều này tạo ra một nghịch lý thú vị: chúng ta có thể sao chép "công thức" ngay lập tức, nhưng vẫn không thể chi trả cho "bếp núc".
Rủi ro lan rộng từ các bản phát hành mã nguồn mở chủ yếu đến từ các bên đã có quyền truy cập tính toán đáng kể - chứ không phải từ việc dân chủ hóa các năng lực nguy hiểm cho các đối tượng có nguồn lực hạn chế. Các cá nhân đe dọa, khủng bố sinh học hoặc các kịch bản lợi dụng sai mục đích thảm khốc khác vẫn cần cơ sở hạ tầng tính toán trị giá hàng triệu đô la để chạy các mô hình tiên tiến có khả năng gây hại như vậy. Rào cản phần cứng này có nghĩa là các năng lực lưỡng dụng đáng lo ngại nhất vẫn tập trung trong tay các tập đoàn lớn và chính phủ kiểm soát các cụm GPU khổng lồ. Mặc dù sự tập trung này có thể mang lại một số lợi ích an toàn ngắn hạn bằng cách hạn chế truy cập vào các năng lực nguy hiểm, nó đồng thời thúc đẩy các động lực quyền lực đáng lo ngại, nơi chỉ một số ít thực thể có thể truy cập vào các hệ thống AI mạnh mẽ nhất. Cho đến khi có những đột phá trong việc tinh giản mô hình, kiến trúc mới hoặc phần cứng rẻ hơn đáng kể khiến việc lưu trữ cục bộ trở nên khả thi, chúng ta phải đối mặt với sự đánh đổi cơ bản giữa truy cập dân chủ hóa và kiểm soát tập trung.
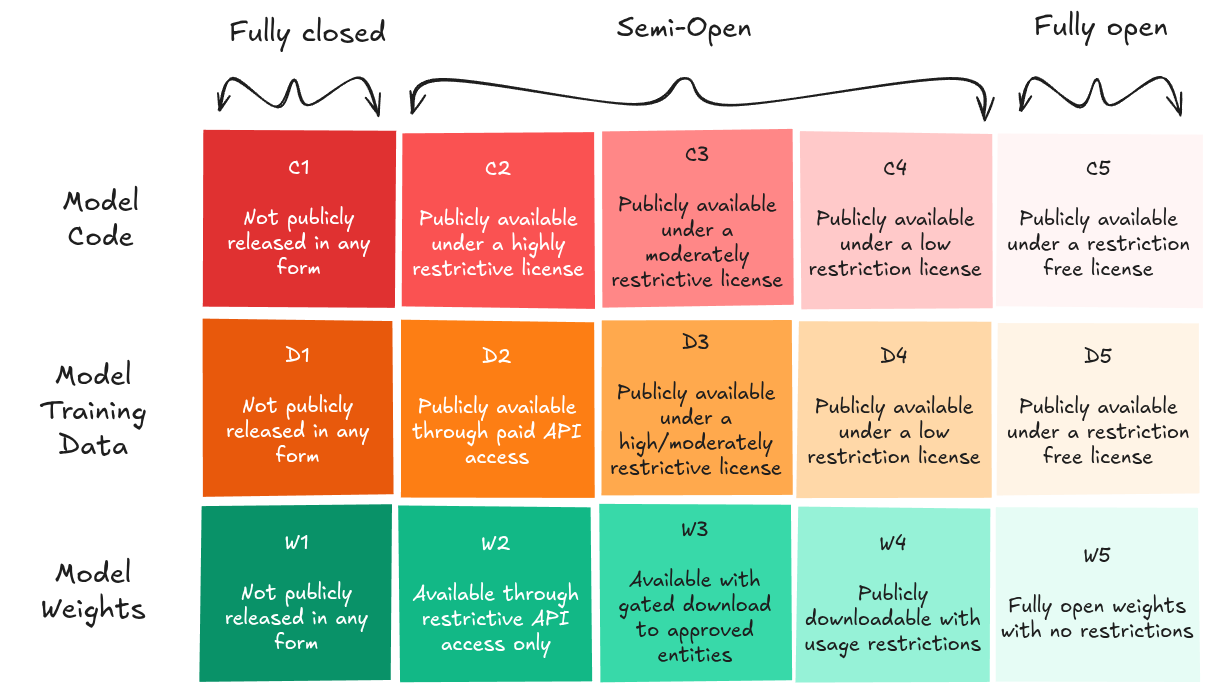
Một đề xuất về thang độ truy cập tập trung vào cả mã mô hình và dữ liệu đào tạo (Eiras et al., 2024) để giảm thiểu cả rủi ro lan rộng và tập trung quyền lực. Chúng ta có thể thấy các tổ hợp mức độ truy cập, ví dụ: DeepSeek-V3 có thể được coi là C5-D1 (DeepSeek, 2025).
Các kênh đa dạng cho phép lan truyền nhanh chóng:
Sự phổ biến của AI đặt ra những thách thức độc đáo - hàng hóa kỹ thuật số tuân theo các quy tắc khác với vật thể vật lý. Các biện pháp kiểm soát phổ biến truyền thống dựa trên sự khan hiếm: chỉ có một lượng uranium giàu nhất định hoặc một số lượng tên lửa tiên tiến nhất định. Nhưng việc sao chép một tệp mô hình gần như không tốn kém. Một khi năng lực tồn tại ở bất kỳ đâu, việc ngăn chặn sự lan truyền của chúng trở thành cuộc chiến chống lại bản chất cơ bản của thông tin. Việc chia sẻ một mô hình dễ dàng hơn nhiều so với việc ngăn chặn sự lan truyền của nó. Ngay cả các phương án đánh dấu nước hoặc mã hóa phức tạp cũng có thể bị các cá nhân quyết tâm vượt qua.
Xác minh rằng một tổ chức không phát triển các năng lực AI gây hại là cực kỳ khó khăn. Khác với công nghệ hạt nhân, nơi khả năng phát hiện tương đương với các phương pháp phổ biến, quản trị AI thiếu các công cụ phòng thủ tương đương (Shevlane, 2024). Các thanh tra hạt nhân có thể sử dụng vệ tinh và thiết bị phát hiện bức xạ để giám sát tuân thủ. Nhưng việc xác minh rằng một tổ chức không phát triển các năng lực AI nguy hiểm sẽ yêu cầu truy cập xâm nhập vào mã nguồn, dữ liệu và quá trình phát triển: các thực hành có thể tiết lộ tài sản trí tuệ quý giá. Nhiều tổ chức do đó từ chối giám sát xâm nhập (Wasil et al., 2024). Điều này sẽ yêu cầu tổ hợp nhiều biện pháp kỹ thuật và quốc gia khác nhau.

Bảng các kỹ thuật né tránh để tránh các phương pháp xác minh dưới các biện pháp kỹ thuật quốc gia hiện tại. (Wasil et al., 2024).
Tính chất lưỡng dụng của công nghệ làm phức tạp các biện pháp kiểm soát. Cùng một kiến trúc biến áp có thể cung cấp năng lượng cho các ứng dụng có lợi cũng có thể cho phép các mục đích gây hại. Khác với công nghệ quân sự chuyên dụng, chúng ta không thể đơn giản cấm các năng lực AI nguy hiểm mà không loại bỏ các ứng dụng có lợi. Vấn đề lưỡng dụng này có nghĩa là quản trị phải tinh vi hơn nhiều so với các chế độ không phổ biến truyền thống (Anderljung, 2024). Một cá nhân có động cơ và nguồn lực khiêm tốn hiện có thể tinh chỉnh các mô hình mạnh mẽ cho mục đích gây hại. Sự dân chủ hóa năng lực này có nghĩa là các mối đe dọa có thể xuất phát từ bất kỳ đâu, không chỉ từ các quốc gia hay các tập đoàn lớn. Các khung quản trị truyền thống không được thiết kế để đối phó với mức độ rủi ro phân tán này.
Làm thế nào quản trị có thể giúp làm chậm sự phổ biến của AI? Một số giải pháp tiềm năng đã được đề xuất để tìm ra sự cân bằng phù hợp giữa tính mở và kiểm soát AI:
Cách thức chính xác mà thế giới sau AGI sẽ trông như thế nào là điều khó dự đoán — thế giới đó có thể sẽ khác biệt hơn so với thế giới hiện tại so với sự khác biệt giữa thế giới hiện tại và thế kỷ 16 [...] Chúng ta vẫn chưa biết mức độ khó khăn để đảm bảo rằng các AGI sẽ hành động theo giá trị của người vận hành. Một số người tin rằng điều đó sẽ dễ dàng; một số người tin rằng nó sẽ vô cùng khó khăn; nhưng không ai biết chắc chắn.
- Greg Brockman, Đồng sáng lập và Cựu Giám đốc Công nghệ (CTO) của OpenAI
Dự đoán của các chuyên gia thường không phản ánh đúng hướng phát triển thực tế của AI. Nếu bạn đọc các bài báo về ChatGPT — những bài báo gọi nó là ‘kỳ diệu’, ‘lộng lẫy’, ‘đáng kinh ngạc’ — bạn sẽ có cảm giác rằng các mô hình ngôn ngữ lớn (LLMs) đã khiến thế giới hoàn toàn bất ngờ. Liệu ấn tượng đó có chính xác không? Thực ra, có. (Cotra, 2023) Năng lực của GPT-3 đã vượt xa những gì nhiều người nghĩ là có thể đạt được chỉ bằng cách mở rộng quy mô. Mỗi bước đột phá lớn dường như đến từ những hướng không ngờ, khiến việc lập kế hoạch dài hạn gần như bất khả thi (Gruetzemacher et al., 2021; Grace et al., 2017). Giả thuyết "mở rộng quy mô" (các mô hình lớn hơn với nhiều khả năng điện toán hơn sẽ tạo ra các hệ thống mạnh mẽ hơn) đã được kiểm chứng một cách đáng ngạc nhiên. Nhưng chúng ta không biết liệu điều này có tiếp tục đến AGI hay sẽ gặp phải các giới hạn kỹ thuật hoặc kinh tế cơ bản. Sự không chắc chắn này có những tác động quản trị khổng lồ. Nếu việc mở rộng quy mô tiếp tục, các biện pháp kiểm soát khả năng điện toán vẫn hiệu quả. Nếu các đột phá thuật toán quan trọng hơn, cần có các tiếp cận quản trị hoàn toàn khác biệt (Patel, 2023).
Đánh giá rủi ro có thể chênh lệch hàng chục lần. Một số nhà nghiên cứu cho rằng rủi ro hiện sinh từ AI có xác suất gần như bằng không, trong khi những người khác coi chúng là gần như chắc chắn nếu không có can thiệp, phản ánh sự không chắc chắn cơ bản về hướng phát triển và khả năng kiểm soát của AI. Khi các chuyên gia bất đồng đến mức này, làm thế nào các nhà hoạch định chính sách có thể đưa ra quyết định có căn cứ? (Narayanan & Kapoor, 2024).
Sự xuất hiện của năng lực mới khiến ngay cả các nhà phát triển cũng bất ngờ. Các mô hình thể hiện những năng lực mà chính những người tạo ra chúng không dự đoán được và không thể giải thích đầy đủ (Cotra, 2023). Nếu những người xây dựng hệ thống này không thể dự đoán năng lực của chúng, làm thế nào các khung quản trị có thể dự đoán những gì cần được điều chỉnh? Sự không thể dự đoán này gia tăng với mỗi thế hệ mô hình mạnh mẽ hơn (Grace et al., 2024). Quy trình lập chính sách truyền thống giả định kết quả có thể dự đoán được. Quy định môi trường mô hình tầm ảnh hưởng ô nhiễm. Việc phê duyệt thuốc đánh giá các tác động sức khỏe cụ thể. Tuy nhiên, quản trị AI phải chuẩn bị cho các kịch bản từ việc cải thiện khả năng dần dần đến việc tự cải thiện đệ quy.
Chờ đợi sự chắc chắn có nghĩa là chờ đợi quá lâu. Đến khi chúng ta biết chính xác năng lực của AI sẽ phát triển như thế nào, có thể đã quá muộn để quản trị chúng một cách hiệu quả. Tuy nhiên, hành động trong điều kiện không chắc chắn có thể dẫn đến việc áp dụng các chính sách sai lầm, kìm hãm sự phát triển có lợi hoặc không thể ngăn chặn các rủi ro thực sự. Điều này tạo ra một tình huống khó khăn cho các nhà hoạch định chính sách có trách nhiệm (Casper, 2024).
Làm thế nào để quản trị hoạt động trong điều kiện không chắc chắn? Các mô hình quản trị thích ứng có thể theo kịp công nghệ thay đổi nhanh chóng có thể cung cấp một hướng đi. Thay vì các quy định cố định dựa trên hiểu biết hiện tại, chúng ta cần các khung khổ có thể phát triển cùng với kiến thức của chúng ta. Điều này có thể bao gồm:
Xây dựng sự đồng thuận trong bối cảnh không chắc chắn đòi hỏi các phương pháp mới. Sự đồng thuận chính sách truyền thống xuất phát từ sự hiểu biết chung về vấn đề và giải pháp. Với trí tuệ nhân tạo (AI), chúng ta thiếu cả hai yếu tố này. Tuy nhiên, chúng ta vẫn phải xây dựng đủ sự đồng thuận để triển khai quản trị trước khi năng lực của AI vượt qua khả năng kiểm soát AI của chúng ta. Điều này có thể đòi hỏi tập trung vào tính hợp pháp của quy trình thay vì tính chắc chắn của kết quả, tức là thống nhất về cách ra quyết định ngay cả khi chúng ta không đồng ý về nội dung quyết định.
[Sau khi từ chức tại OpenAI] Những vấn đề này rất khó để giải quyết đúng đắn, và tôi lo ngại rằng chúng ta không đang đi đúng hướng để đạt được điều đó [...] OpenAI đang gánh vác một trách nhiệm khổng lồ thay mặt cho toàn nhân loại. Tuy nhiên, trong những năm qua, văn hóa an toàn và quy trình đã bị đẩy lùi so với các sản phẩm sáng bóng. Chúng ta đã quá muộn để nghiêm túc đối mặt với những hậu quả của Trí tuệ Nhân tạo Tổng quát (AGI).
- Jan Leike, Cựu đồng trưởng dự án Superalignment tại OpenAI
Một số ít cá nhân đưa ra quyết định ảnh hưởng đến toàn nhân loại. Các CEO của khoảng năm công ty và các quan chức cấp cao của ba chính phủ chủ yếu quyết định hướng phát triển của trí tuệ nhân tạo tiên tiến. Những lựa chọn của họ về việc xây dựng gì, triển khai khi nào và đảm bảo an toàn như thế nào có hệ quả đối với hàng tỷ người không có tiếng nói trong các quyết định này. Hội đồng quản trị của OpenAI có ít hơn mười thành viên. Quỹ Lợi ích Dài hạn của Anthropic kiểm soát công ty với chỉ năm thành viên hội đồng quản trị. Những nhóm nhỏ này đưa ra quyết định về các công nghệ có thể thay đổi cơ bản xã hội loài người. Không có công ty dược phẩm nào có thể tung ra một loại thuốc mới với sự giám sát hạn chế như vậy, nhưng các hệ thống AI có tầm ảnh hưởng rộng lớn hơn lại phải đối mặt với sự giám sát bên ngoài tối thiểu. Hầu hết sự phát triển AI tiên tiến diễn ra ở hai khu vực: Vùng Vịnh San Francisco và London. Giá trị, giả định và điểm mù của các trung tâm công nghệ này định hình các hệ thống AI được sử dụng trên toàn thế giới, nhưng chúng ta biết nhiều hơn về cách làm xúc xích hơn là cách đào tạo các hệ thống AI tiên tiến. Điều gì có vẻ hiển nhiên ở Palo Alto có thể là điều xa lạ ở Lagos hoặc Jakarta, nhưng đa số người dân trên thế giới hầu như không có tiếng nói trong việc phát triển AI (Adan et al., 2024).

Năm 2023, hầu hết các mô hình AI nổi bật đều xuất phát từ các cơ sở giáo dục của Mỹ (Stanford, 2024).
Các cơ chế trách nhiệm truyền thống không áp dụng. Hội đồng quản trị của các công ty về mặt lý thuyết cung cấp sự giám sát, nhưng phần lớn thiếu động lực để đánh giá rủi ro từ AI hệ thống. Các cơ quan quản lý nhà nước gặp khó khăn trong việc theo kịp sự phát triển nhanh chóng. Các nhà nghiên cứu học thuật có thể cung cấp bằng chứng khoa học và đánh giá độc lập thường phụ thuộc vào tài trợ của doanh nghiệp hoặc quyền truy cập vào khả năng điện toán. Kết quả là một khoảng trống quản trị, nơi không ai có cả năng lực và quyền hạn cần thiết để thực hiện quản trị đúng đắn (Anderljung, 2023). Hệ quả của sự thiếu hụt quản trị này đã bắt đầu lộ rõ. Chúng ta đã chứng kiến các deepfake do AI tạo ra được sử dụng để lan truyền thông tin sai lệch chính trị (Swenson & Chan, 2024). Các mô hình ngôn ngữ đã được sử dụng để tạo ra các email lừa đảo và các trò lừa đảo khác (Stacey, 2025). Khi các mô hình thể hiện các hành vi đáng lo ngại, chúng ta không thể xác định liệu chúng có nguồn gốc từ dữ liệu đào tạo, hàm thưởng hay các lựa chọn kiến trúc. Tính chất "hộp đen" của quá trình phát triển là một nút thắt cổ chai lớn trong việc chịu trách nhiệm (Chan et al., 2024).

Sơ đồ thể hiện con đường từ khả năng kiểm toán (ex-ante) đến trách nhiệm giải trình (post-hoc) (Herrera-Poyatos et al., 2025)
AI tập trung quyền lực theo những cách chưa từng có. Các hệ thống AI, đặc biệt là những hệ thống do các tập đoàn lớn phát triển, đang định hình lại cấu trúc quyền lực xã hội. Những hệ thống này quyết định quyền truy cập vào thông tin và tài nguyên, thực chất là thực thi quyền lực tự động đối với cá nhân (Lazar, 2024). Khi những hệ thống này trở nên mạnh mẽ hơn, sự tập trung này càng gia tăng. Tổ chức đầu tiên phát triển AGI có thể giành được lợi thế quyết định trong mọi lĩnh vực hoạt động của con người, một động lực "người thắng lấy tất cả" không có tiền lệ trong lịch sử.
Tác động của tài sản làm trầm trọng thêm các bất bình đẳng hiện có. Tự động hóa AI chủ yếu mang lại lợi ích cho chủ sở hữu vốn trong khi đẩy lùi người lao động, làm sâu sắc thêm các bất bình đẳng hiện có. Bằng chứng thực nghiệm gần đây cho thấy việc áp dụng AI làm gia tăng đáng kể bất bình đẳng tài sản bằng cách mang lại lợi ích không cân xứng cho những người sở hữu mô hình, dữ liệu và tài nguyên khả năng điện toán, trong khi làm tổn hại đến lao động (Skare et al., 2024). Nếu không có các can thiệp quản trị có mục tiêu, rủi ro từ AI có nguy cơ tạo ra mức độ bất bình đẳng kinh tế chưa từng có, có thể dẫn đến xã hội bất bình đẳng nhất trong lịch sử nhân loại (O’Keefe, 2020).

‘Mô hình phô mai Thụy Sĩ’ – mô hình đại diện cho một chiến lược phòng thủ đa lớp được khuyến nghị để đối phó với rủi ro tích lũy quyền lực không được phát hiện và không bị kiểm soát. Các vector đe dọa được hiển thị bằng màu đỏ (Stix et al., 2025)
Quản trị dân chủ đang đối mặt với những thách thức tồn vong. Khi thông tin bị kiểm soát bởi các thực thể tư nhân, các cơ chế dân chủ truyền thống gặp khó khăn trong việc duy trì hiệu quả (Kreps & Kriner, 2023). Một số bằng chứng thực nghiệm cho thấy mức độ tích hợp AI cao hơn có liên quan đến sự suy giảm tham gia dân chủ và trách nhiệm giải trình, khi các quan chức được bầu không thể điều chỉnh các công nghệ phức tạp phát triển nhanh hơn quá trình lập pháp (Chehoudi, 2025). Thực tế kỹ trị đang nổi lên này làm suy yếu cơ bản các nguyên tắc dân chủ về kiểm soát và giám sát công khai.
Sự chênh lệch quốc tế đe dọa ổn định toàn cầu. Các quốc gia không có năng lực AI trong nước phải đối mặt với sự phụ thuộc vĩnh viễn vào các cường quốc AI. Việc áp dụng AI làm trầm trọng thêm sự bất bình đẳng quốc tế, ưu ái không cân xứng cho các quốc gia có công nghệ tiên tiến. Sự chênh lệch này không chỉ đe dọa tính cạnh tranh kinh tế mà còn đe dọa chủ quyền cơ bản khi các quyết định quan trọng bị ủy thác cho các hệ thống AI do nước ngoài kiểm soát (Cerutti et al., 2025). Chúng ta không có khung khổ thống nhất để phân phối lợi ích của AI hoặc quản lý các tác động của nó. Liệu các nhà phát triển AI có nghĩa vụ đối với người lao động bị mất việc? Thuế và phân phối tài sản do AI tạo ra nên được thực hiện như thế nào? Những người không phải nhà phát triển có quyền yêu cầu gì đối với năng lực AI? Những câu hỏi này cần được trả lời trước khi tầm ảnh hưởng của AI trở nên không thể đảo ngược, nhưng các cuộc thảo luận về quản trị hiện nay hầu như không đề cập đến chúng (Ding & Dafoe, 2024).

Ở Mỹ, số lượng sinh viên tốt nghiệp với bằng cử nhân về khả năng điện toán đã tăng 22% trong 10 năm qua. Tuy nhiên, việc tiếp cận vẫn còn hạn chế ở nhiều quốc gia châu Phi do thiếu hụt cơ sở hạ tầng cơ bản như điện (Stanford HAI, 2025).