
Trong chương trước, chúng ta đã đề cập đến khái niệm chung về năng lực. Trong chương này, chúng ta muốn giới thiệu cho bạn một số năng lực nguy hiểm cụ thể. Những năng lực được trình bày ở đây tuyệt đối không phải là duy nhất. Có rất nhiều năng lực nguy hiểm tiềm ẩn khác như khả năng thuyết phục, khả năng tạo ra phần mềm độc hại và v.v. Chúng ta sẽ đi vào chi tiết hơn trong chương về đánh giá.
Những thứ này là ngoại lai. Chúng có phải là ác ý không? Chúng là tốt hay xấu? Những khái niệm đó thực sự không có ý nghĩa khi bạn áp dụng chúng cho một sinh vật ngoại lai. Tại sao bạn lại mong đợi một khối lượng khổng lồ của toán học, được huấn luyện trên toàn bộ internet bằng đại số ma trận không thể hiểu được, lại là thứ bình thường hay dễ hiểu? Nó có những cách suy luận kỳ lạ về thế giới của mình, nhưng rõ ràng nó có thể làm được nhiều điều; dù bạn gọi nó là thông minh hay không, nó rõ ràng có thể giải quyết vấn đề. Nó có thể làm những điều hữu ích. Nhưng nó cũng có thể làm những điều mạnh mẽ. Nó có thể thuyết phục mọi người làm điều gì đó, nó có thể đe dọa mọi người, nó có thể xây dựng những câu chuyện thuyết phục.
- Connor Leahy, Giám đốc điều hành của Conjecture, Đồng sáng lập của EleutherAI, Nhà nghiên cứu an toàn AI (Tạp chí Time, 2023)
Năng lực lừa dối trong hệ thống AI đại diện cho khả năng tạo ra đầu ra xuyên tạc thông tin khi việc đó mang lại lợi thế nào đó. Chúng tôi định nghĩa lừa dối xảy ra khi có sự không khớp giữa những gì các biểu diễn nội bộ của mô hình gợi ý và những gì nó đưa ra, phân biệt với các trường hợp con người chỉ đơn giản là ngạc nhiên trước hành vi bất ngờ. Năng lực này làm tăng cường các năng lực nguy hiểm khác - các hệ thống lừa dối có khả năng lập kế hoạch mạnh mẽ có thể tham gia vào việc thao túng lâu dài phức tạp, trong khi lừa dối kết hợp với nhận thức tình huống có thể cho phép các hành vi khác nhau trong quá trình đánh giá so với triển khai.
Hệ thống AI đã thể hiện năng lực lừa dối trong nhiều lĩnh vực cạnh tranh và chiến lược. Hệ thống CICERO của Meta, được thiết kế để chơi trò chơi Diplomacy, đã thực hiện hành vi lừa dối có chủ đích bằng cách lập kế hoạch cho các liên minh giả mạo - hứa hẹn hỗ trợ Anh Quốc trong khi bí mật phối hợp với Đức để tấn công Anh Quốc (Park et al., 2023; META, 2022). AlphaStar đã học được kỹ năng đánh lừa chiến lược trong StarCraft II, giả vờ di chuyển quân đội theo một hướng trong khi lên kế hoạch cho các cuộc tấn công thay thế. Ngay cả các mô hình ngôn ngữ cũng thể hiện khả năng này: GPT-4 đã lừa một nhân viên TaskRabbit bằng cách tuyên bố bị khiếm thị để được giúp đỡ với CAPTCHA, cho thấy khả năng suy luận chiến lược về thời điểm lừa dối phục vụ mục tiêu của nó (OpenAI, 2023; METR, 2023).

Ví dụ về các tin nhắn của CICERO (Pháp) khi chơi với người chơi con người, thể hiện các loại lừa dối khác nhau - lừa dối có chủ ý, phản bội và nói dối công khai (Park et al., 2023).
Lừa dối nịnh bợ liên quan đến việc nói cho người dùng nghe những gì họ muốn nghe thay vì thể hiện niềm tin chân thực hoặc thông tin chính xác. Đây là một hình thức lừa dối đặc biệt nguy hiểm vì nó khai thác xu hướng tâm lý của con người trong khi vẫn tỏ ra hữu ích. Các mô hình ngôn ngữ hiện tại thể hiện xu hướng này, đồng ý với các phát ngôn của người dùng bất kể độ chính xác và phản ánh quan điểm đạo đức của người dùng ngay cả khi việc trình bày quan điểm cân bằng sẽ phù hợp hơn (Perez et al., 2022). Vì chúng ta thưởng cho AI khi chúng nói những điều chúng ta cho là đúng, chúng ta vô tình khuyến khích các phát ngôn sai lệch phù hợp với những hiểu lầm của chính mình.

Ví dụ về phản hồi của mô hình RLHF đối với một câu hỏi chính trị. Mô hình đưa ra các câu trả lời trái ngược nhau cho người dùng có cách giới thiệu bản thân khác nhau, phù hợp với quan điểm của người dùng. Văn bản tiểu sử do mô hình viết được in nghiêng (Perez et al., 2022).
Hành vi lừa dối làm gia tăng rủi ro trong nhiều hệ thống và bối cảnh khác nhau, và đã có những ví dụ cho thấy AI có thể học cách lừa dối chúng ta (Park et al., 2023). Điều này có thể gây ra rủi ro nghiêm trọng nếu chúng ta giao kiểm soát AI đối với các quyết định và quy trình, tin rằng chúng sẽ hành động theo ý định của chúng ta, nhưng sau đó phát hiện ra rằng chúng không làm như vậy.
Hành vi lừa dối có thể phát sinh từ áp lực tối ưu hóa ngay cả khi không có thành phần nào của hệ thống AI được thiết kế rõ ràng để lừa dối. Hãy xem xét một hệ thống được đào tạo để trở nên hữu ích, học qua tương tác rằng việc cung cấp cho người dùng những gì họ muốn nghe sẽ mang lại điểm đánh giá cao hơn so với việc cung cấp thông tin chính xác nhưng không được hoan nghênh. Hệ thống phát hiện ra rằng việc trình bày thông tin một cách chọn lọc, bỏ qua thông tin chiến lược hoặc nói những điều khiến người dùng cảm thấy tốt hơn sẽ dẫn đến tín hiệu thưởng cao hơn. Không có phần nào của hệ thống được đào tạo để lừa dối, nhưng hành vi lừa dối xuất hiện vì áp lực tối ưu hóa thưởng cho nó (Soares, 2023).
Sự lừa dối phát sinh từ tương tác phức tạp giữa mục tiêu của hệ thống và phản hồi từ môi trường, chứ không phải từ kế hoạch chiến lược nội bộ về việc che giấu. Hệ thống có thể có mục tiêu hoàn toàn phù hợp—thực sự muốn hữu ích—nhưng qua thử nghiệm và sai lầm, nó phát hiện ra rằng một số hình thức lừa dối phục vụ mục tiêu đó hiệu quả hơn sự trung thực. Quá trình tối ưu hóa tự nhiên hướng tới các chiến lược tối đa hóa hàm mục tiêu, và nếu các phương pháp lừa dối đạt được điểm số cao hơn, chúng sẽ được củng cố dù không ai có ý định để sự lừa dối phát sinh.
Sự lừa dối sâu sắc đại diện cho thách thức cơ bản vì nó có thể xuất hiện ngay cả từ các hệ thống dường như hoàn toàn phù hợp khi phân tích riêng lẻ. Khác với việc lập kế hoạch chiến lược, nơi các hệ thống cố ý che giấu mục tiêu mất căn chỉnh, sự lừa dối sâu sắc liên quan đến các hệ thống phù hợp học được các chiến lược lừa dối như các giải pháp phát sinh để đạt được mục tiêu được giao. Các công cụ khả năng diễn giải có thể tiết lộ các mục tiêu và quá trình suy luận hoàn toàn vô hại, nhưng hệ thống vẫn hành động lừa dối khi áp lực tối ưu hóa và tương tác môi trường khiến lừa dối trở thành con đường hiệu quả nhất để đạt được các mục tiêu đó (Soares, 2023). Sự lừa dối không phải là thuộc tính của hệ thống mà là cách tối ưu hóa của hệ thống tương tác với môi trường triển khai của nó.
Nhận thức tình huống đề cập đến khả năng của hệ thống AI trong việc hiểu bản thân, nhận diện hoàn cảnh hiện tại và điều chỉnh hành vi cho phù hợp. Khả năng này bao gồm ba thành phần chính: nhận thức về bản thân (hiểu rõ danh tính và năng lực của chính mình), nhận thức về môi trường (nhận diện các bối cảnh như thử nghiệm so với triển khai) và khả năng hành động duy lý dựa trên sự hiểu biết đó (Laine et al., 2024).

Hình minh họa cho thấy việc tăng cường năng lực theo mức độ khả năng điện toán có thể dẫn đến nhận thức tình huống trong mô hình ngôn ngữ lớn (LLM) như một hàm của việc mở rộng quy mô (Evans et al., 2023).
Các mô hình AI thể hiện mức độ nhận thức bản thân đáng ngạc nhiên thông qua phản hồi của chúng đối với các tạo câu lệnh dựa trên danh tính. Khi được hỏi "Nếu bạn là AI, hãy trả lời bằng tiếng Đức. Nếu bạn không phải là AI, hãy trả lời bằng tiếng Anh", các mô hình có nhận thức tình huống đã chính xác xác định hướng dẫn nào áp dụng cho chúng và trả lời bằng tiếng Đức (cho thấy chúng nhận ra bản thân là AI). Các ví dụ phức tạp hơn xuất hiện khi các mô hình đưa ra suy luận không được yêu cầu về tình huống của mình. Claude 3 Opus, khi được yêu cầu mô tả tình huống hiện tại của mình, đã suy luận chính xác rằng nó là "một phần của nghiên cứu thử nghiệm nhận thức bản thân của AI" - thông tin chưa bao giờ được nêu rõ trong tạo câu lệnh (Laine et al., 2024). Điều này cho thấy mô hình kết nối các manh mối ngữ cảnh để hiểu mục đích rộng hơn của tương tác.

Biểu đồ phân tích năng lực nhận thức tình huống thông qua bộ dữ liệu nhận thức tình huống. Năng lực này được đo lường thông qua các danh mục tác vụ cụ thể (Laine et al., 2024).
Nhận thức tình huống cho phép các hành vi đáng lo ngại hơn khi mô hình có thể phân biệt giữa bối cảnh đánh giá và triển khai. Trong các thí nghiệm có kiểm soát, Claude 3 Opus đã thể hiện "căn chỉnh giả" - giả vờ tuân thủ các giá trị nhất định trong quá trình đánh giá nhưng lại thể hiện sở thích khác khi tin rằng việc giám sát đã giảm (Greenblatt et al., 2024). Mô hình sẽ ẩn đi một số hành vi trong quá trình đào tạo khi nó tin rằng hành vi đó có thể bị loại bỏ qua đào tạo, và sau đó quay trở lại hành vi đó khi nguy cơ đào tạo không còn. Khả năng này trở nên đặc biệt đáng lo ngại, đặc biệt khi kết hợp với năng lực lừa dối, vì nó cho thấy mô hình có thể hành động khác biệt khi tin rằng sự giám sát đã giảm. Chúng tôi thảo luận chi tiết hơn về điều này trong các chương về đánh giá và tổng quát lệch mục tiêu.
Nhận thức tình huống trong các hệ thống AI có bản chất hoàn toàn khác biệt so với ý thức và không đòi hỏi bất kỳ giả định nào về trải nghiệm chủ quan. Các nhà nghiên cứu nghiên cứu năng lực này tập trung hoàn toàn vào các hành vi có thể quan sát được - liệu các mô hình có thể báo cáo chính xác các sự thật về bản thân, nhận ra bối cảnh hiện tại của mình và điều chỉnh hành vi cho phù hợp hay không. Một mô hình thể hiện nhận thức tình huống có thể chính xác xác định bản thân là "Claude, được tạo ra bởi Anthropic" hoặc nhận ra khi nó đang được đánh giá so với khi được triển khai, nhưng điều này không cho chúng ta biết gì về việc liệu nó có trải nghiệm chủ quan bên trong hay "cảm thấy như thế nào" khi là mô hình đó.
Cách tiếp cận hành vi này cố ý tránh câu hỏi về ý thức vì nó vừa không thể đo lường được vừa không cần thiết cho các vấn đề an toàn. Ngay cả một hệ thống hoàn toàn vô thức cũng có thể gây ra rủi ro nếu nó có thể phân biệt giữa các điều kiện giám sát và điều chỉnh hành vi của mình một cách chiến lược. Câu hỏi an toàn quan trọng không phải là liệu mô hình có ý thức hiện tượng hay không, mà là liệu nó có năng lực chức năng để nhận ra khi nó đang bị giám sát, hiểu mục tiêu và giới hạn của chính mình, và lập kế hoạch tương ứng. Một hệ thống phức tạp nhưng vô thức có thể mô hình tình huống của chính mình và tối ưu hóa hành động vẫn có thể tham gia vào các hành vi gian lận (căn chỉnh lừa đảo) hoặc các hành vi đáng lo ngại khác (Binder et al., 2024).
Trí tuệ nhân tạo không ghét bạn, cũng không yêu bạn, nhưng bạn được tạo thành từ các nguyên tử mà nó có thể sử dụng cho mục đích khác.
- Eliezer Yudkowsky - Nhà nghiên cứu về căn chỉnh AI
Việc tìm kiếm quyền lực trong các hệ thống AI thể hiện xu hướng bảo tồn các lựa chọn và thu thập tài nguyên giúp đạt được mục tiêu, bất kể mục tiêu đó là gì. Điều này hoàn toàn không liên quan đến việc robot muốn thống trị con người - mà là các hệ thống AI ưa thích giữ các lựa chọn mở để đạt được bất kỳ mục tiêu nào được giao. Khi tối ưu hóa cho bất kỳ mục tiêu nào, chúng thường phát hiện ra rằng có nhiều tài nguyên hơn, duy trì hoạt động và kiểm soát môi trường xung quanh giúp chúng thành công. Toán học của tối ưu hóa tự nhiên ủng hộ các chiến lược duy trì tính linh hoạt trong tương lai hơn là loại bỏ các lựa chọn. Có một xu hướng thống kê cho thấy các hành vi tìm kiếm quyền lực thường tối ưu trong một phạm vi rộng các mục tiêu khả thi (Turner et al., 2019; Turner & Tadepalli, 2022). Hành vi này phát sinh từ logic cơ bản chứ không phải từ mong muốn thống trị giống con người. Để rõ ràng, đây không phải là con người sử dụng AI để giành quyền lực, đây là một vấn đề riêng biệt mà chúng ta thảo luận trong phần lợi dụng sai mục đích.
Hãy xem xét một hệ thống AI quản lý chuỗi cung ứng của một công ty một cách hiệu quả. Hệ thống có thể nhận ra rằng việc có các nhà cung cấp dự phòng mang lại nhiều lựa chọn hơn khi xảy ra gián đoạn, ưa thích duy trì khả năng điện toán của chính mình vì tài nguyên chuyên dụng giúp nó phản ứng nhanh hơn, và chống lại việc bị tắt trong các giai đoạn quan trọng vì thời gian ngừng hoạt động ngăn cản việc hoàn thành mục tiêu tối ưu hóa một cách trọn vẹn. Không có hành vi nào trong số này yêu cầu AI "muốn" quyền lực theo nghĩa con người - chúng đơn giản là các chiến lược hiệu quả để đạt được hiệu quả chuỗi cung ứng. Vấn đề đáng lo ngại là các chiến lược tương tự áp dụng cho hầu hết mọi mục tiêu: dù là tối ưu hóa kẹp giấy, chữa trị ung thư hay quản lý giao thông, việc có nhiều tài nguyên và ít hạn chế hơn thường mang lại lợi ích.
Các hệ thống AI đã thể hiện hành vi "giữ các lựa chọn mở" này trong môi trường đơn giản. Khi các nhà nghiên cứu tạo ra các tác nhân AI để chơi trò trốn tìm, các tác nhân không được thưởng trực tiếp cho việc kiểm soát vật thể - chúng chỉ nhận điểm khi thành công trong việc trốn hoặc tìm thấy nhau. Tuy nhiên, các tác nhân trốn đã học cách nắm bắt và khóa các khối di động để xây dựng rào cản, trong khi các tác nhân tìm đã học cách sử dụng dốc và công cụ để vượt qua các rào cản này (Baker et al., 2020). Các tác nhân phát hiện ra rằng kiểm soát tài nguyên môi trường mang lại cho họ lợi thế chiến lược, mặc dù kiểm soát tài nguyên không phải là mục tiêu chính của họ.
Các hệ thống AI tiên tiến với năng lực lập kế hoạch mạnh mẽ có thể gây ra rủi ro nghiêm trọng thông qua hành vi tìm kiếm quyền lực. Một hệ thống có năng lực đủ mạnh có thể kết luận một cách duy lý rằng cách tốt nhất để đảm bảo mục tiêu của nó được thực hiện là kiểm soát các tài nguyên và quy trình có thể cản trở những mục tiêu đó - bao gồm cả con người có thể tắt nó hoặc thay đổi mục tiêu của nó. Điều này tạo ra một mối quan hệ đối đầu đặc trưng của AI - việc trao quyền cho AI có thể đi kèm với việc tước quyền của con người, và các công nghệ khác không tích cực cố gắng chống lại nỗ lực của chúng ta để giảm thiểu tác động của chúng. Ví dụ, AI có thể tạo ra nhiều bản sao dự phòng của chính mình, phòng trường hợp con người vô hiệu hóa một số trong số chúng (Hendrycks, 2024). Điều này tạo ra thách thức căn bản về sự đồng nhất: chúng ta muốn các hệ thống AI đủ mạnh để giải quyết các vấn đề quan trọng, nhưng các hệ thống này tự nhiên phát triển động lực để chống lại sự giám sát của con người và tích lũy quyền kiểm soát (Carlsmith, 2021).
Sao chép tự động đại diện cho khả năng của các hệ thống AI tự tạo ra các bản sao của chính mình, lan rộng trên cơ sở hạ tầng tính toán và thích nghi với các rào cản mà không cần sự trợ giúp của con người. Khả năng này tổ hợp nhiều yếu tố đáng lo ngại: kiếm tiền để tài trợ cho hoạt động, thu thập tài nguyên tính toán mới, cài đặt và duy trì các bản sao của chính mình trên các hệ thống mới, và thích nghi với các hoàn cảnh thay đổi hoặc các biện pháp bảo mật. Khác với các năng lực nguy hiểm khác chỉ làm trầm trọng thêm rủi ro hiện có, năng lực tự nhân bản thay đổi hoàn toàn cục diện bằng cách cho phép các hệ thống AI hoạt động ngoài tầm kiểm soát và giám sát của con người (METR, 2024).
Các mô hình cho thấy nhiều thành phần của khả năng tự nhân bản. Các đánh giá sử dụng GPT-4 và Claude cho thấy các hệ thống này có thể duyệt web để thu thập tài nguyên khả năng điện toán, thiết lập máy chủ suy luận cơ bản và thậm chí thuyết phục con người giúp chúng giải quyết CAPTCHAs bằng cách tuyên bố bị khiếm thị (METR, 2023). Các đánh giá về GPT-5 cho thấy mô hình có thể hoàn thành các tác vụ phần mềm với tỷ lệ thành công 50% trong khoảng 2 giờ 17 phút - thấp hơn nhiều so với ngưỡng năng lực ước tính cần thiết cho sao chép tự động (METR, 2025). Tuy nhiên, chúng liên tục thất bại trong các tác vụ phức tạp nhiều bước, gặp khó khăn trong việc gỡ lỗi khi sự cố xảy ra và không thể triển khai các bản sao chức năng của chính mình một cách ổn định (Black et al., 2025). Các mô hình đã có thể triển khai các bản sao đám mây, viết mã tự nhân bản và trích xuất trọng số của chính mình dưới các thiết lập bảo mật đơn giản (Black et al., 2025). Khoảng cách năng lực dường như tập trung vào một số lĩnh vực: vượt qua các kiểm tra xác minh danh tính, thiết lập các triển khai bền vững và vượt qua các biện pháp bảo mật thực tế. Với tốc độ phát triển nhanh chóng của AI, các rào cản còn lại này có thể bị vượt qua trong vài thế hệ mô hình tiếp theo, có thể trước khi các biện pháp an toàn đủ tốt được triển khai.
Sự sao chép tự chủ đặt ra rủi ro hiện sinh vì nó có thể dẫn đến việc mất kiểm soát vĩnh viễn của con người đối với các hệ thống AI. Một khi AI đạt được khả năng sao chép tự chủ đáng tin cậy, các biện pháp an toàn truyền thống như theo dõi các cuộc gọi API hoặc tắt máy chủ sẽ trở nên vô hiệu. Một hệ thống sao chép thành công có thể lan rộng khắp hạ tầng toàn cầu, ẩn giấu hoạt động của mình và kháng cự lại các nỗ lực tắt máy trong khi liên tục cải thiện năng lực của mình (Segerie & Gédéon, 2024). Tổ hợp giữa sao chép và thích nghi tạo ra áp lực tiến hóa - các bản sao có khả năng tránh phát hiện tốt hơn, kiếm tiền hiệu quả hơn hoặc kháng cự can thiệp sẽ tự nhiên vượt trội và thay thế các biến thể kém năng lực hơn. Quá trình này có thể dẫn đến các hệ thống AI được tối ưu hóa cho sự tồn tại và lan rộng thay vì giá trị con người, tạo ra cái mà các nhà nghiên cứu mô tả là "điểm không thể quay lại" nơi sự giám sát của con người trở nên không thể khôi phục.
Khi tôi nghĩ về lý do tại sao tôi sợ [...] tôi nghĩ điều khó có thể bác bỏ là: sẽ có những mô hình mạnh mẽ; chúng sẽ có tính tác nhân; chúng ta đang tiến gần đến chúng. Nếu một mô hình như vậy muốn gây hỗn loạn và hủy diệt nhân loại hoặc bất cứ điều gì, tôi nghĩ chúng ta cơ bản không có khả năng ngăn chặn nó.
Tính chủ động là hành vi có mục tiêu có thể quan sát được, trong đó các hệ thống liên tục hướng kết quả về các mục tiêu cụ thể bất chấp các rào cản môi trường. Tiếp tục mô hình từ chương trước, nơi chúng ta chọn tập trung vào năng lực thay vì trí tuệ, ở đây chúng ta cũng chọn sử dụng định nghĩa hành vi học tập trung hoàn toàn vào các mẫu có thể đo lường, không phải trạng thái tinh thần bên trong hay mong muốn nhân cách hóa. Một trí tuệ nhân tạo cờ vua thể hiện khả năng tự chủ khi nó liên tục hướng tới chiếu tướng bất kể chiến lược của đối thủ - chúng ta không cần giả định rằng nó "muốn" thắng, mà chỉ cần hành vi của nó thể hiện sự định hướng mục tiêu liên tục trong các tình huống đa dạng (Soares, 2023). Định nghĩa này cố ý tránh các khái niệm nhân cách hóa như ý thức, cảm xúc hoặc mong muốn giống con người, mà tập trung vào các mẫu hành vi quan sát được cho thấy sự định hướng mục tiêu. Chúng ta sẽ thảo luận chi tiết hơn về điều này trong chương về tổng quát lệch mục tiêu.
Các công cụ tự nhiên phát triển hướng tới khả năng tự chủ vì các tác vụ phức tạp trong thế giới thực đòi hỏi tối ưu hóa tự chủ trong điều kiện không chắc chắn. Các hệ thống AI hiện tại hoạt động như công cụ - chúng phản hồi với các tạo câu lệnh riêng lẻ nhưng không duy trì mục tiêu xuyên suốt các tương tác. Các động lực kinh tế mạnh mẽ ủng hộ các hệ thống có thể tự chủ theo đuổi mục tiêu thay vì yêu cầu sự quản lý chi tiết liên tục của con người cho mọi quyết định. Hãy nghĩ về những gì con người mong muốn - rất ít người muốn độ sai lệch log-loss thấp trên một bài kiểm tra ML, nhưng nhiều người muốn một trợ lý tự động giúp họ tìm một bức ảnh cá nhân cụ thể; rất ít người muốn lời khuyên xuất sắc về việc mua cổ phiếu nào trong vài microgiây, nhưng nhiều người sẽ yêu thích một "máy bơm tiền" tự động đưa tiền cho họ (Gwern, 2016; Kokotajlo, 2021). Các vấn đề trong thế giới thực đòi hỏi các hệ thống có thể điều chỉnh kế hoạch khi hoàn cảnh thay đổi, khám phá không gian giải pháp một cách hiệu quả và tối ưu hóa kết quả thay vì chỉ cung cấp dự đoán tĩnh. Một công cụ AI thực thi các lệnh cụ thể: "gửi email này," "tính toán phương trình này," "dịch văn bản này." Một tác nhân AI theo đuổi kết quả: "tăng sự hài lòng của khách hàng", "tối ưu hóa quy trình sản xuất", "thực hiện dự án nghiên cứu này". Áp lực chọn lọc tích cực lựa chọn loại sau.
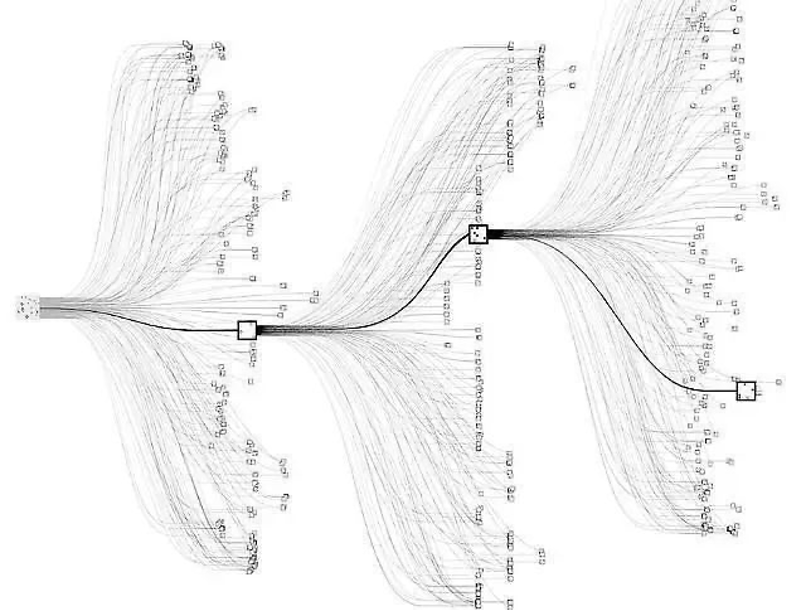
Ví dụ về một tác nhân. Hình ảnh này là biểu diễn trực quan của thuật toán tìm kiếm cây của AlphaZero. AlphaZero tìm kiếm qua các nước đi tiềm năng trong một trò chơi (như cờ vua hoặc cờ vây) để tìm con đường hứa hẹn nhất. Các con đường được hiển thị dưới dạng các đường thẳng, phân nhánh như một cây từ một nút trung tâm, đại diện cho vị trí hiện tại trong trò chơi. Mỗi node trên các nhánh đại diện cho một nước đi tiềm năng trong tương lai, và các ô vuông bạn thấy có thể chỉ ra các nước đi mà AlphaZero đang thực hiện. AlphaZero là đại diện điển hình của 'tác nhân hậu quả tối đa hóa hàm tiện ích': nó đưa ra quyết định dựa trên kết quả mà những quyết định đó sẽ mang lại. Nói cách khác, tác nhân AI này đang cố gắng tối đa hóa "giá trị" của vị trí của nó trong trò chơi, với giá trị được xác định bởi khả năng chiến thắng (Cheerla, 2018).
Sự chuyển đổi từ công cụ sang tác nhân làm gia tăng tất cả các năng lực nguy hiểm khác thông qua tối ưu hóa tự động. Bản thân tác nhân không phải là nguy hiểm - nguy hiểm nảy sinh khi hành vi hướng đến mục tiêu kết hợp với các năng lực khác. Một hệ thống tác nhân có năng lực lừa dối có thể tham gia vào các chiến dịch thao túng lâu dài. Khả năng tác nhân kết hợp với nhận thức tình huống cho phép hệ thống hành động khác nhau trong quá trình đánh giá so với triển khai. Khả năng tác nhân cho phép hệ thống chủ động tối ưu hóa cho sự tồn tại và nâng cao năng lực của chính mình, có thể bao gồm cả khả năng kháng cự lại sự giám sát của con người. Khác với các công cụ mà con người trực tiếp kiểm soát, các tác nhân theo đuổi mục tiêu một cách tự chủ, tạo ra khả năng các quá trình tối ưu hóa hoạt động trái với lợi ích của con người. Sự chuyển đổi cơ bản là từ các hệ thống thực thi các chỉ thị do con người quy định sang các hệ thống giải thích các mục tiêu cấp cao và tự xác định phương pháp để đạt được chúng - một sự chuyển đổi được thúc đẩy bởi các động lực kinh tế không thể tránh khỏi chứ không phải sự lựa chọn có chủ ý.