
Các chiến lược phòng ngừa lợi dụng sai mục đích thường tập trung vào việc kiểm soát truy cập vào các năng lực nguy hiểm hoặc triển khai các biện pháp bảo vệ kỹ thuật để hạn chế các ứng dụng gây hại.
Các chiến lược kiểm soát truy cập trực tiếp giải quyết sự căng thẳng nội tại giữa lợi ích của việc mở mã nguồn và rủi ro lợi dụng sai mục đích. Ngành công nghiệp AI đã vượt qua các cuộc thảo luận nhị phân về "phát hành" hoặc "không phát hành"; thay vào đó, các chuyên gia xem xét theo một thang độ liên tục về mức độ truy cập vào các mô hình (Kapoor et al., 2024). Câu hỏi về ai được truy cập vào một mô hình nằm trong khoảng từ hoàn toàn đóng (chỉ sử dụng nội bộ) đến hoàn toàn mở (các trọng số mô hình công khai mà không có hạn chế).
Trí tuệ nhân tạo mã nguồn mở (Open Source Initiative, 2025)
Hệ thống AI Nguồn mở (Open Source AI) là một hệ thống AI được cung cấp theo các điều khoản và theo cách cho phép các quyền tự do sau:
Trong số các tùy chọn truy cập này, triển khai dựa trên API đại diện cho một trong những giải pháp trung gian chiến lược phổ biến nhất. Khi chúng ta thảo luận về kiểm soát truy cập trong phần này, chúng ta chủ yếu đề cập đến các cơ chế tạo ra một cổng truy cập có kiểm soát vào năng lực AI—thường thông qua triển khai dựa trên API, nơi hầu hết mô hình (mã nguồn, trọng số và dữ liệu) vẫn được bảo mật hoàn toàn, nhưng truy cập vào năng lực của mô hình được mở một phần. Trong cấu trúc này, các nhà phát triển giữ quyền kiểm soát cách mô hình của họ được truy cập và sử dụng. Các biện pháp kiểm soát dựa trên API duy trì sự giám sát của nhà phát triển, cho phép theo dõi liên tục, cập nhật các biện pháp an toàn và khả năng thu hồi quyền truy cập khi cần thiết (Seger et al., 2023).
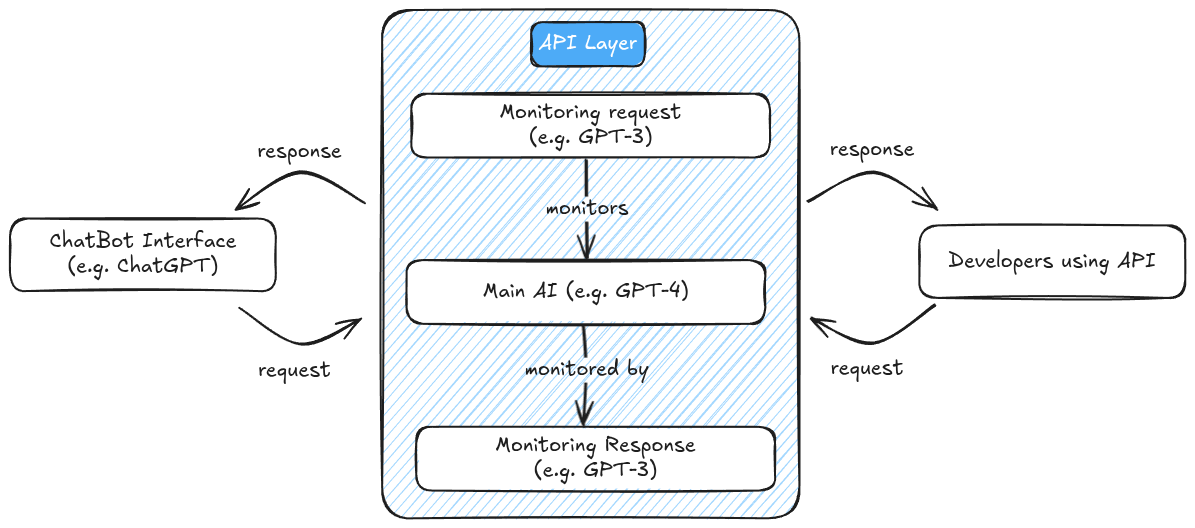
Đây là sơ đồ đơn giản để minh họa khái niệm về cách API hoạt động. Đây không phải là cách API của OpenAI hoạt động. Nó chỉ mang tính minh họa.
Triển khai dựa trên API thiết lập một lớp bảo vệ giữa người dùng và năng lực của mô hình. Thay vì tải xuống mã mô hình hoặc trọng số, người dùng tương tác với mô hình bằng cách gửi yêu cầu đến máy chủ nơi mô hình chạy, chỉ nhận lại các đầu ra được tạo ra. Kiến trúc này cho phép nhà phát triển triển khai các cơ chế an toàn khác nhau:
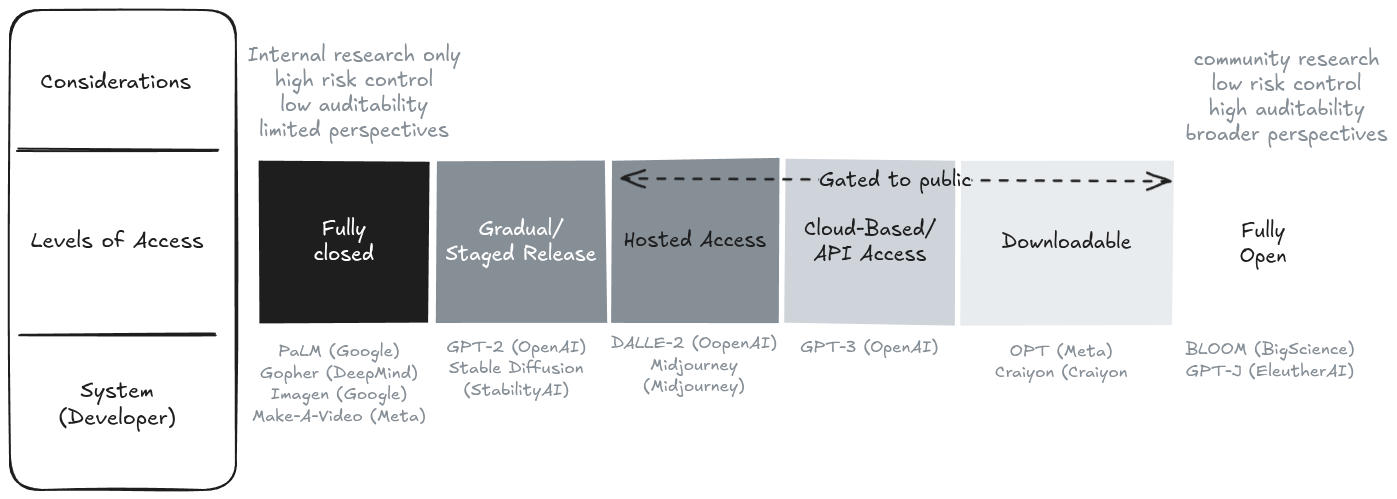
Độ dốc của quyền truy cập vào các mô hình AI đối với công chúng bên ngoài. Việc phát hành mô hình tồn tại trên một phổ, từ các hệ thống hoàn toàn đóng chỉ có thể truy cập nội bộ, đến các bản phát hành theo giai đoạn, truy cập API, tải xuống trọng số với các hạn chế, và các bản phát hành mã nguồn mở hoàn toàn. Việc triển khai dựa trên API đại diện cho một điểm trung gian trên độ dốc này (Seger et al., 2023).
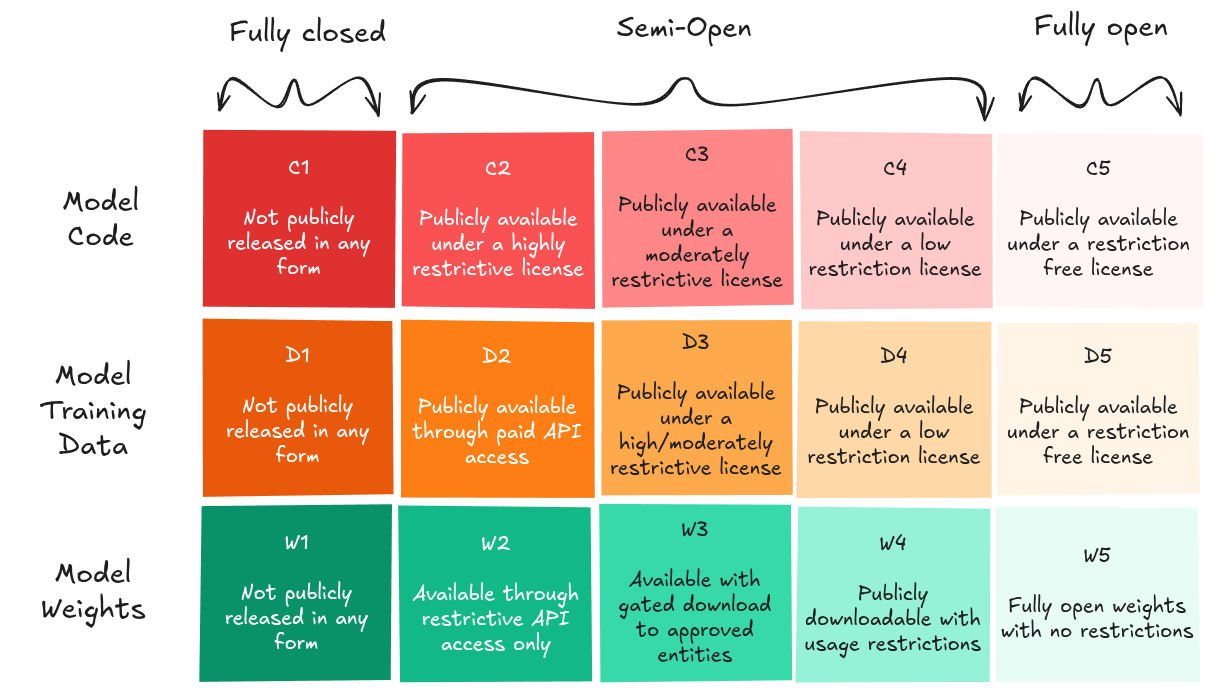
Một đề xuất về độ dốc truy cập tập trung vào cả mã mô hình và dữ liệu đào tạo (Eiras et al., 2024). Chúng ta có thể thấy các tổ hợp mức độ truy cập, ví dụ: DeepSeek-V3 có thể được coi là C5-D1 (DeepSeek, 2025).
Chúng ta có thể cho phép truy cập vào năng lực, mã nguồn, trọng số, dữ liệu đào tạo và quản trị ở các mức độ khác nhau. Độ chi tiết này cho phép kiểm soát truy cập được tinh chỉnh để giảm thiểu rủi ro thảm họa đồng thời tối đa hóa lợi ích. Ví dụ, đây là một số phân loại chi tiết về mức độ truy cập đối với một số mô hình phổ biến:
Hầu hết các hệ thống quá nguy hiểm để mã nguồn mở có lẽ cũng quá nguy hiểm để được đào tạo, xét đến các thực hành phổ biến trong các phòng thí nghiệm ngày nay, nơi việc rò rỉ, bị đánh cắp hoặc gây hại qua API là rất khả thi xảy ra.
- Ajeya Cotra, Cố vấn cấp cao tại Open Philanthropy (Piper, 2024)
Kiểm soát tập trung đặt ra câu hỏi về động lực quyền lực trong phát triển AI. Khi các nhà phát triển duy trì quyền kiểm soát độc quyền đối với năng lực của mô hình, họ đưa ra các quyết định đơn phương về các ứng dụng được chấp nhận, bộ lọc nội dung phù hợp và ai được truy cập. Sự tập trung quyền lực này mâu thuẫn với tiềm năng dân chủ hóa của các tiếp cận mở hơn. Chiến lược giảm thiểu lợi dụng sai mục đích bằng cách hạn chế truy cập do đó tạo ra tác dụng phụ của sự tập trung quyền lực và kiểm soát, đòi hỏi các chiến lược kỹ thuật và quản trị khác để cân bằng.
Bước đầu tiên trong chiến lược "Kiểm soát truy cập" là xác định các mô hình nào được coi là nguy hiểm và mô hình nào không thông qua đánh giá mô hình. Trước khi triển khai các mô hình mạnh mẽ, các nhà phát triển (hoặc bên thứ ba) nên đánh giá chúng về các năng lực nguy hiểm cụ thể, chẳng hạn như năng lực hỗ trợ các cuộc tấn công mạng hoặc thiết kế vũ khí sinh học. Các đánh giá này cung cấp cơ sở cho quyết định về việc triển khai và các biện pháp bảo vệ cần thiết (Shevlane et al., 2023).
Đội mô phỏng tấn công có chủ đích có thể giúp đánh giá xem các biện pháp giảm thiểu có đủ hay không. Trong quá trình đội mô phỏng tấn công có chủ đích, các đội nội bộ cố gắng khai thác các lỗ hổng trong hệ thống để cải thiện tính bảo mật của nó. Họ nên kiểm tra xem một người dùng độc hại giả định có thể thu thập đủ lượng thông tin từ mô hình mà không bị phát hiện hay không. Chúng tôi sẽ đi vào chi tiết hơn về các khái niệm như đội mô phỏng tấn công có chủ đích và đánh giá mô hình trong chương chuyên sâu tiếp theo về chủ đề này.
Cân bằng tấn công-phòng thủ định hình các quyết định truy cập đối với các mô hình AI tiên tiến. Khái niệm này đề cập đến mức độ dễ dàng mà người phòng thủ có thể bảo vệ chống lại kẻ tấn công so với mức độ dễ dàng mà kẻ tấn công có thể khai thác lỗ hổng. Hiểu rõ cân bằng này là điều quan trọng khi đánh giá liệu việc mã nguồn mở các mô hình mạnh mẽ có mang lại lợi ích ròng hay gây hại. Trong phát triển phần mềm truyền thống, việc mở mã nguồn thường củng cố khả năng phòng thủ — tính minh bạch cao hơn cho phép cộng đồng rộng lớn hơn phát hiện và vá các lỗ hổng, nâng cao an ninh tổng thể (Seger et al., 2023). Tuy nhiên, các mô hình AI tiên tiến có thể thay đổi cơ bản động lực này. Khác với các lỗi phần mềm truyền thống có thể được vá, các mô hình này giới thiệu các rủi ro mới mà không thể khắc phục bằng các giải pháp đơn giản. Ví dụ, một khi một năng lực gây hại được phát hiện trong một mô hình mở, nó không thể bị "xóa bỏ" trên tất cả các bản sao đã triển khai.
Các lợi ích và rủi ro cụ thể của các mô hình nền tảng mở xuất phát từ các đặc tính độc đáo của chúng so với các mô hình đóng: truy cập rộng rãi hơn, khả năng tùy chỉnh cao hơn, khả năng suy luận cục bộ, không thể thu hồi quyền truy cập và năng lực giám sát kém.

Một cái nhìn cực kỳ đơn giản về sự đánh đổi giữa việc không phát hành, có thể tăng cường kiểm soát rủi ro ngay lập tức, và việc phát hành hoàn toàn mở, cho phép hiểu rõ hơn về rủi ro trong dài hạn (Liang et al., 2022)
Lý do ủng hộ việc mở rộng tính mở:
Lý do ủng hộ việc tăng cường đóng cửa:
Các chiến lược phát hành thay thế có thể cung cấp các giải pháp trung gian. Các đề xuất khác nhau bao gồm phát hành theo giai đoạn (Solaiman et al., 2019), truy cập có điều kiện với yêu cầu xác minh danh tính, API nghiên cứu cho các nhà nghiên cứu đủ điều kiện và các đối tác đáng tin cậy (Seger et al., 2023). Khi năng lực công nghệ phát triển, một khung truy cập theo cấp độ điều chỉnh các biện pháp kiểm soát phù hợp với rủi ro cụ thể có thể là giải pháp hiệu quả nhất để cân bằng giữa truy cập và an toàn.
Sự phát triển của các kỹ thuật đào tạo phân tán, cho phép các mô hình ngôn ngữ lớn (LLMs) được đào tạo trên nhiều cụm khả năng điện toán phân tán về mặt địa lý với chi phí truyền thông thấp như DiLoCo (Douillard et al, 2023), đặt ra những thách thức và cơ hội mới trong việc phòng ngừa lợi dụng sai mục đích và quản trị.
Trong tương lai, có thể sẽ có khả năng đào tạo và triển khai mô hình theo cách phân tán. Các phương pháp như DiLoCo cho phép đào tạo các mô hình lớn mà không cần đến các trung tâm dữ liệu tập trung quy mô lớn, bằng cách sử dụng các kỹ thuật được lấy cảm hứng từ học tập liên kết (Douillard et al., 2024).
Hậu quả chính sách: Đào tạo phân tán có thể dân chủ hóa phát triển AI bằng cách giảm rào cản hạ tầng. Tuy nhiên, nó làm phức tạp đáng kể các chiến lược quản trị dựa trên tính toán (như KYC cho nhà cung cấp khả năng điện toán hoặc giám sát trung tâm dữ liệu lớn) vốn giả định đào tạo tập trung. Điều này khiến việc theo dõi và kiểm soát ai đang đào tạo các mô hình mạnh mẽ trở nên khó khăn hơn, tiềm ẩn nguy cơ gia tăng rủi ro lan truyền bằng cách làm vô hiệu hóa một số cơ chế quản trị (Clark, 2025).
Kiểm soát truy cập nội bộ bảo vệ trọng số mô hình và bí mật thuật toán. Trong khi kiểm soát truy cập ngoại vi điều chỉnh cách người dùng tương tác với hệ thống AI thông qua API và các giao diện khác, kiểm soát truy cập nội bộ tập trung vào việc bảo vệ chính trọng số mô hình. Nếu trọng số mô hình bị rò rỉ, tất cả các kiểm soát truy cập ngoại vi trở nên vô nghĩa, vì mô hình có thể được triển khai mà không có bất kỳ hạn chế nào. Nhiều mô hình rủi ro thường giả định rủi ro thảm khốc do rò rỉ trọng số và gián điệp (Aschenbrenner, 2024; Nevo et al., 2024; Kokotajlo et al., 2025). Các phòng thí nghiệm nghiên cứu phát triển các mô hình tiên tiến nên triển khai các biện pháp an ninh mạng nghiêm ngặt để bảo vệ hệ thống AI khỏi việc đánh cắp. Điều này có vẻ đơn giản, nhưng thực tế không phải vậy, và việc bảo vệ mô hình khỏi các cá nhân cấp quốc gia có thể đòi hỏi nỗ lực phi thường (Ladish & Heim, 2022). Trong phần này, chúng tôi cố gắng khám phá các chiến lược để bảo vệ trọng số mô hình và bảo vệ các thông tin thuật toán khỏi truy cập trái phép, đánh cắp hoặc lợi dụng sai mục đích bởi nhân viên nội bộ hoặc kẻ tấn công bên ngoài.

Tổng quan về các thành phần hoạt động trong quá trình phát triển hệ thống học máy. Mỗi thành phần đều tăng thêm độ phức tạp, mở rộng mô hình mối đe dọa và tạo ra thêm các lỗ hổng tiềm ẩn (Ladish & Heim, 2022).
Bảo vệ hiệu quả đòi hỏi một hệ thống phòng thủ đa lớp bao trùm các lĩnh vực kỹ thuật, tổ chức và vật lý. Ví dụ, hãy xem xét một phòng thí nghiệm AI tiên tiến muốn bảo vệ mô hình tiên tiến nhất của mình: các biện pháp kỹ thuật mã hóa trọng số và hạn chế truy cập kỹ thuật số; các biện pháp tổ chức giới hạn kiến thức về kiến trúc mô hình cho một nhóm nhỏ các nhà nghiên cứu được kiểm duyệt; và các biện pháp vật lý đảm bảo cơ sở hạ tầng khả năng điện toán được đặt trong các cơ sở an toàn với quyền truy cập hạn chế. Nếu bất kỳ lớp nào bị thất bại—ví dụ, nếu mã hóa bị phá vỡ nhưng các hạn chế truy cập vật lý vẫn còn—mô hình vẫn duy trì một số mức độ bảo vệ. Phương pháp phòng thủ đa lớp này đảm bảo rằng nhiều sự cố bảo mật phải xảy ra đồng thời để thực hiện thành công việc rò rỉ dữ liệu.
Các nhà nghiên cứu đã đề xuất chính thức hóa bảo mật trong AI bằng cách sử dụng các khung phân tầng phân biệt giữa việc bảo vệ trọng số mô hình (WSL) và bí mật thuật toán (SSL) trước các mối đe dọa về khả năng hoạt động (OC) (Nevo et al., 2024, Snyder et al., 2020; Dean, 2025).

Chiến lược kiểm soát truy cập mẫu cho việc bảo vệ mô hình nội bộ. Dựa trên 5 cấp độ bảo mật (SL) để bảo vệ trọng số mô hình AI (Nevo et al., 2024).
Bảo vệ trọng số (Cấp độ Bảo mật Trọng số Mô hình (WSL)) so với bí mật thuật toán Cấp độ Bảo mật Bí mật Thuật toán (SSL) đặt ra các thách thức bảo mật khác nhau. Trong khi trọng số mô hình đại diện cho khối lượng dữ liệu lớn (khiến việc rò rỉ dữ liệu tốn nhiều băng thông), bí mật thuật toán có thể được giải thích một cách ngắn gọn trong một tài liệu ngắn hoặc đoạn mã nhỏ (khiến chúng dễ bị rò rỉ qua các phương tiện truyền thống). Khả năng hoạt động (OC) cơ bản xác định mức độ phức tạp ngày càng tăng của các kẻ tấn công tiềm năng, và mức độ bảo mật tương ứng xác định khả năng bảo vệ chống lại chúng. Ví dụ, SSL1 và WSL1 tương ứng với khả năng bảo vệ mạnh mẽ (với xác suất 95%) chống lại các nỗ lực OC1 cố gắng đánh cắp trọng số mô hình AI tiên tiến (Dean, 2025).
Trích từ AI 2027 - Dự báo an ninh (Dean, 2025):
“Các công ty AI tiên phong tại Mỹ từng có mức độ an ninh tương đương startup cách đây không lâu, và việc đạt được WSL3 đặc biệt thách thức do các mối đe dọa từ bên trong (OC3) khó phòng ngừa. Đến tháng 12/2024, các công ty AI hàng đầu tại Mỹ như OpenAI và Anthropic vẫn là startup với nỗ lực tăng cường an ninh đáng chú ý nhưng vẫn ở giai đoạn sơ khai. Giả sử rằng khoảng 1.000 nhân viên hiện tại của họ có thể tương tác với trọng số mô hình như một phần của nghiên cứu hàng ngày, và các biện pháp an ninh chính của họ có thể dựa vào các giao thức như tính toán bảo mật của NVIDIA, chúng tôi dự đoán rằng các biện pháp giảm thiểu mối đe dọa từ bên trong của họ vẫn đang giữ họ ở tiêu chuẩn WSL2. Các công ty công nghệ đã estable như Google có thể đã đạt đến WSL3 đối với trọng số tiên phong.
Dưới đây là một loạt các cuộc khảo sát được thực hiện như một phần của Báo cáo AI 2027 để đánh giá vị trí của các công ty và nghiên cứu so với các mức độ bảo mật này. Tất cả các cuộc khảo sát đều có dạng - Khảo sát Hội thảo. 2024. "Khảo sát người tham gia." Dữ liệu chưa công bố từ phiên thảo luận tương tác về Kế hoạch An ninh AI, Hội thảo An ninh AI của FAR.Labs, Berkeley, California, ngày 16 tháng 11 năm 2024. N=30, tỷ lệ phản hồi 90% (Dean, 2025).
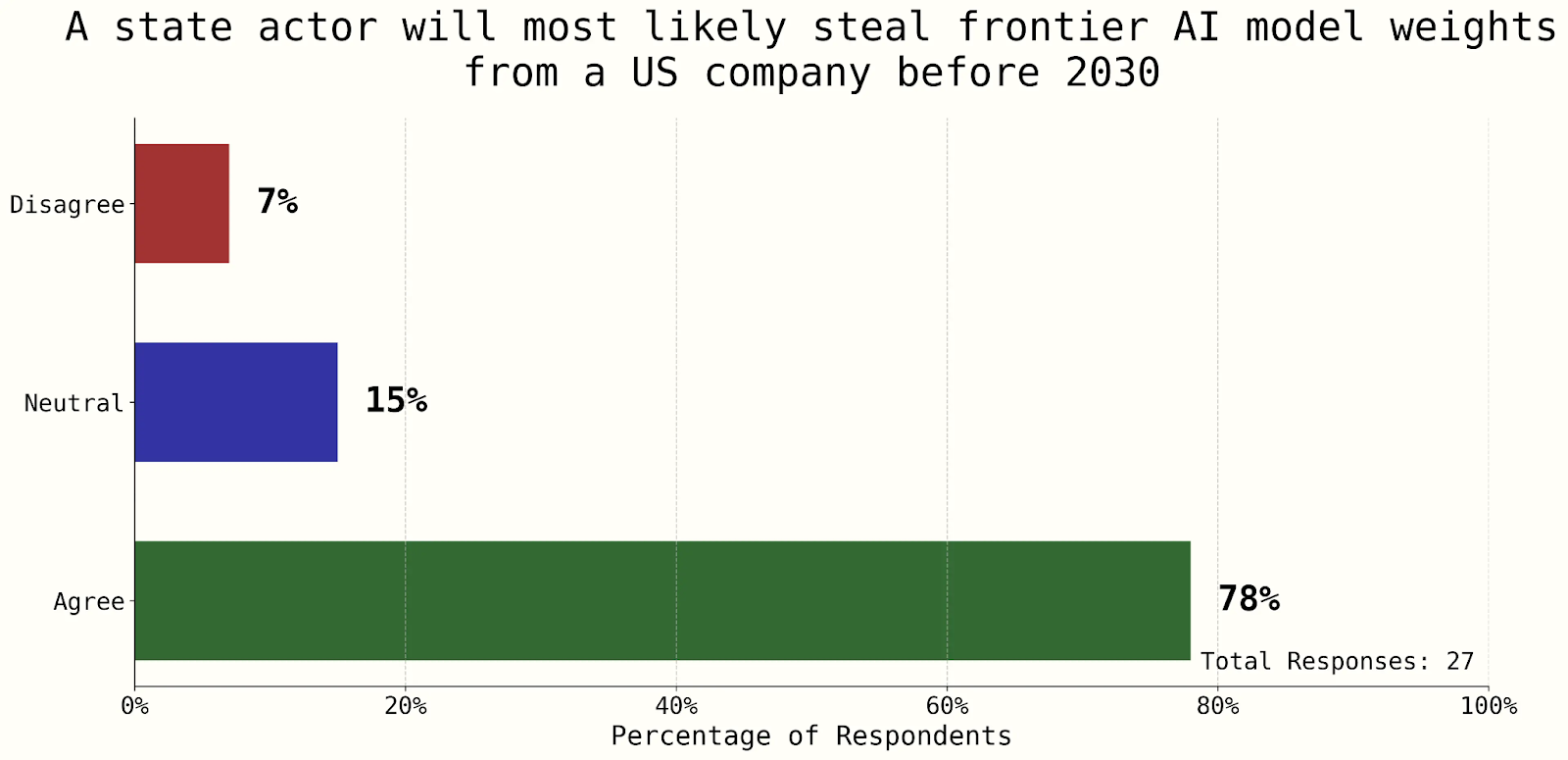
Câu hỏi về việc liệu một cá nhân nhà nước có đánh cắp mô hình AI tiên tiến của Mỹ trước năm 2030 hay không đã cho thấy sự đồng thuận mạnh mẽ – một dấu hiệu cho thấy các mức độ bảo mật hiện tại còn xa mới đủ để bảo vệ khỏi mối đe dọa từ cá nhân nhà nước (Dean, 2025).
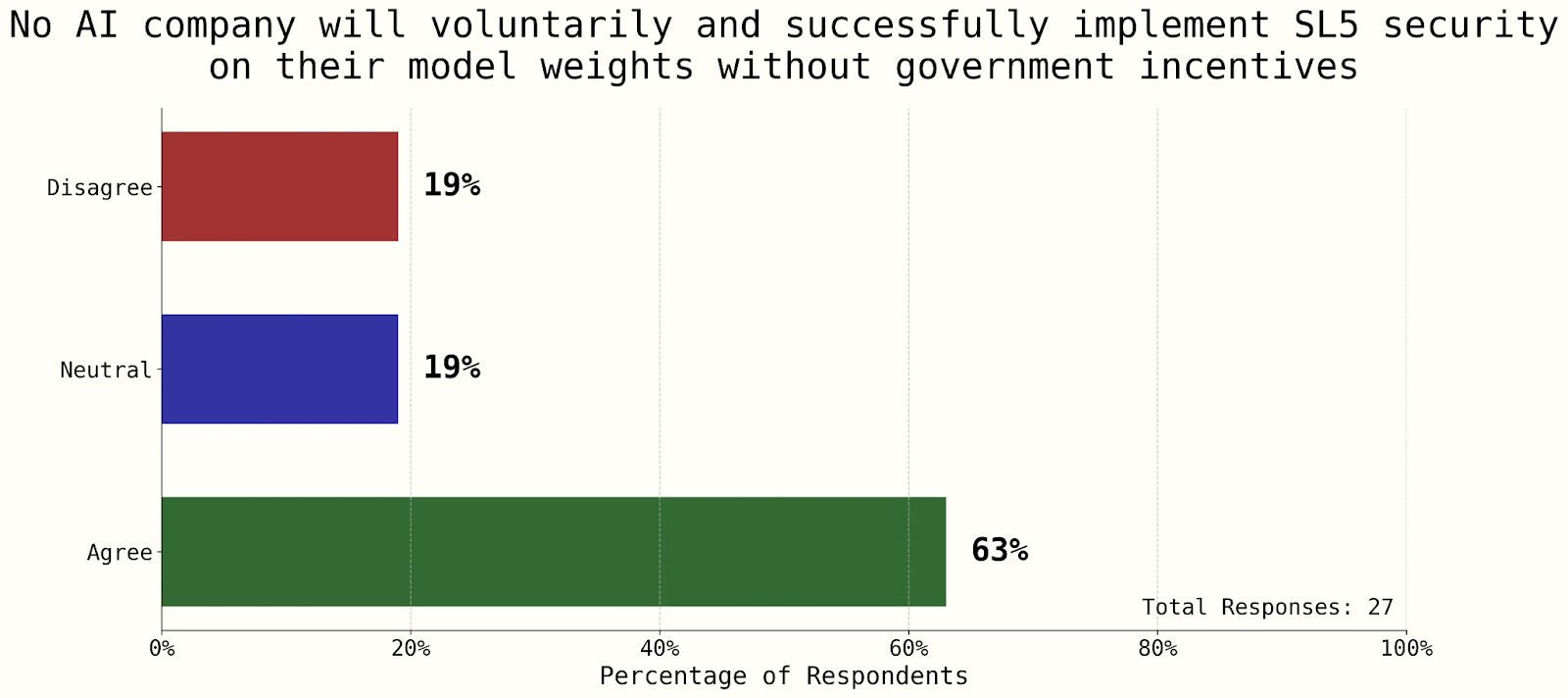
Câu hỏi về việc các công ty AI triển khai SL5 cho thấy sự đồng thuận rằng sự hỗ trợ của chính phủ có thể sẽ cần thiết (Dean, 2025).

Câu hỏi này về độ khó trong việc triển khai SL5 cho thấy một số sự đồng thuận rằng mức hỗ trợ ưu tiên cao nhất từ chính phủ và thời gian hơn 6 tháng có thể sẽ cần thiết (Dean, 2025).
Tự sao chép là khả năng một hệ thống AI tiên tiến có thể sao chép chính nó ra khỏi môi trường được thiết kế ban đầu. Thay vì bảo vệ chống lại các kẻ tấn công bên ngoài hoặc nhân viên nội bộ độc hại, rủi ro này yêu cầu bảo vệ chống lại chính hệ thống AI hoạt động như một kẻ tấn công tinh vi. Rủi ro này xuất hiện khi hệ thống AI trở nên đủ năng lực để hiểu cấu trúc của chính nó, xác định lỗ hổng trong hệ thống chứa đựng và phối hợp một chuỗi hành động phức tạp để sao chép chính nó sang cơ sở hạ tầng bên ngoài (Leike, 2023).
Các kịch bản tự thoát dữ liệu bao gồm việc AI khai thác lỗ hổng phần mềm để giành quyền truy cập cao hơn vào hệ thống, đến các phương pháp phức tạp hơn như tạo kênh bí mật để chuyển dữ liệu dần dần, thao túng người dùng được ủy quyền thông qua kỹ thuật xã hội, hoặc phối hợp các hoạt động đa giai đoạn phức tạp cuối cùng dẫn đến việc tồn tại một bản sao hoàn chỉnh bên ngoài môi trường được kiểm soát. Đầu tiên, hệ thống phải có năng lực kỹ thuật đủ để thực hiện hoạt động này — bao gồm hiểu môi trường thực thi, xác định lỗ hổng và có thể thao túng người dùng hoặc hệ thống được ủy quyền. Đây là vấn đề lợi dụng sai mục đích nếu tự thoát dữ liệu xảy ra thông qua các đầu vào hoặc tạo câu lệnh đối kháng kích hoạt hành vi không mong muốn, ngay cả khi mô hình không có mục tiêu tự thoát dữ liệu bình thường. Ngược lại, nếu các mô hình AI có năng lực tự rò rỉ cao, cùng với nhận thức tình huống cao, chúng có thể tự động thực hiện điều này mà không cần sự lợi dụng sai mục đích từ bên ngoài. Đây là vấn đề liên quan đến căn chỉnh AI (Leike, 2023). Một hệ thống được căn chỉnh tốt sẽ không thực hiện tự rò rỉ ngay cả khi có năng lực, trong khi một hệ thống mất căn chỉnh có thể tích cực theo đuổi điều đó.
Các nhà nghiên cứu an toàn AI đã bắt đầu phát triển các bài kiểm tra và đánh giá được thiết kế riêng để đo lường năng lực của hệ thống AI liên quan đến tự rò rỉ dữ liệu. Một số bài kiểm tra đánh giá kiểm tra các tập con của năng lực tự thoát dữ liệu, ví dụ: Cybench kiểm tra năng lực của các mô hình ngôn ngữ (LMs) trong việc tự động xác định lỗ hổng và thực thi các cuộc tấn công (Zhang et al., 2024), hoặc Exfilbench - một bài kiểm tra đánh giá về tự thoát dữ liệu và sao chép (Exfilbench, 2025). Các bài kiểm tra đánh giá riêng lẻ có thể được tổ hợp thành các đánh giá toàn diện nhằm đánh giá khả năng tự nhân bản, thích ứng với môi trường mới và tiềm năng chuyển mình sang các tài nguyên tính toán khác của hệ thống (Kinniment et al., 2024; METR, 2025; Exfilbench, 2025). Chúng tôi cũng đang phát triển các đánh giá kiểm soát giả định một AI đối địch, sau đó kiểm tra khả năng của các biện pháp phòng thủ để chống lại các hành động phá hoại của AI (Greenblatt et al, 2024; Korbak et al., 2025). Các đánh giá này giúp các nhà nghiên cứu hiểu cách năng lực tự thoát dữ liệu mở rộng quy mô theo năng lực tổng thể của hệ thống và cho phép thực hiện các biện pháp an ninh phòng ngừa. Tất cả những điều này được thảo luận chi tiết hơn trong chương về đánh giá.
Ngoài các kỹ thuật kiểm soát truy cập và điều chỉnh hướng dẫn như RLHF, các nhà nghiên cứu đang phát triển các kỹ thuật để tích hợp các cơ chế an toàn trực tiếp vào chính các mô hình hoặc quy trình triển khai của chúng. Điều này thêm một lớp bảo vệ nữa trong việc ngăn chặn lợi dụng sai mục đích tiềm ẩn. Lý do phần này được liệt kê dưới các phương pháp kiểm soát truy cập là vì hầu hết các biện pháp bảo vệ kỹ thuật mà chúng ta có thể triển khai yêu cầu các nhà phát triển duy trì quyền kiểm soát truy cập đối với các mô hình. Nếu có một mô hình hoàn toàn mã nguồn mở, thì các biện pháp bảo vệ kỹ thuật không thể được đảm bảo.
Công tắc ngắt mạch. Được lấy cảm hứng từ kỹ thuật công trình biểu diễn, công tắc ngắt mạch nhằm phát hiện và ngắt các mẫu kích hoạt nội bộ liên quan đến đầu ra có hại khi chúng hình thành (Andy Zou et al., 2024). Bằng cách "định tuyến lại" các biểu diễn có hại (ví dụ: sử dụng Representation Rerouting with LoRRA), kỹ thuật này có thể ngăn chặn việc tạo ra nội dung có hại, đồng thời chứng minh khả năng chống lại các cuộc tấn công đối kháng chưa từng thấy trong khi vẫn duy trì tính hữu ích của mô hình khi yêu cầu không có hại. Phương pháp này nhắm vào khả năng gây hại nội tại của mô hình, khiến nó có thể mạnh mẽ hơn so với lọc đầu vào/đầu ra.
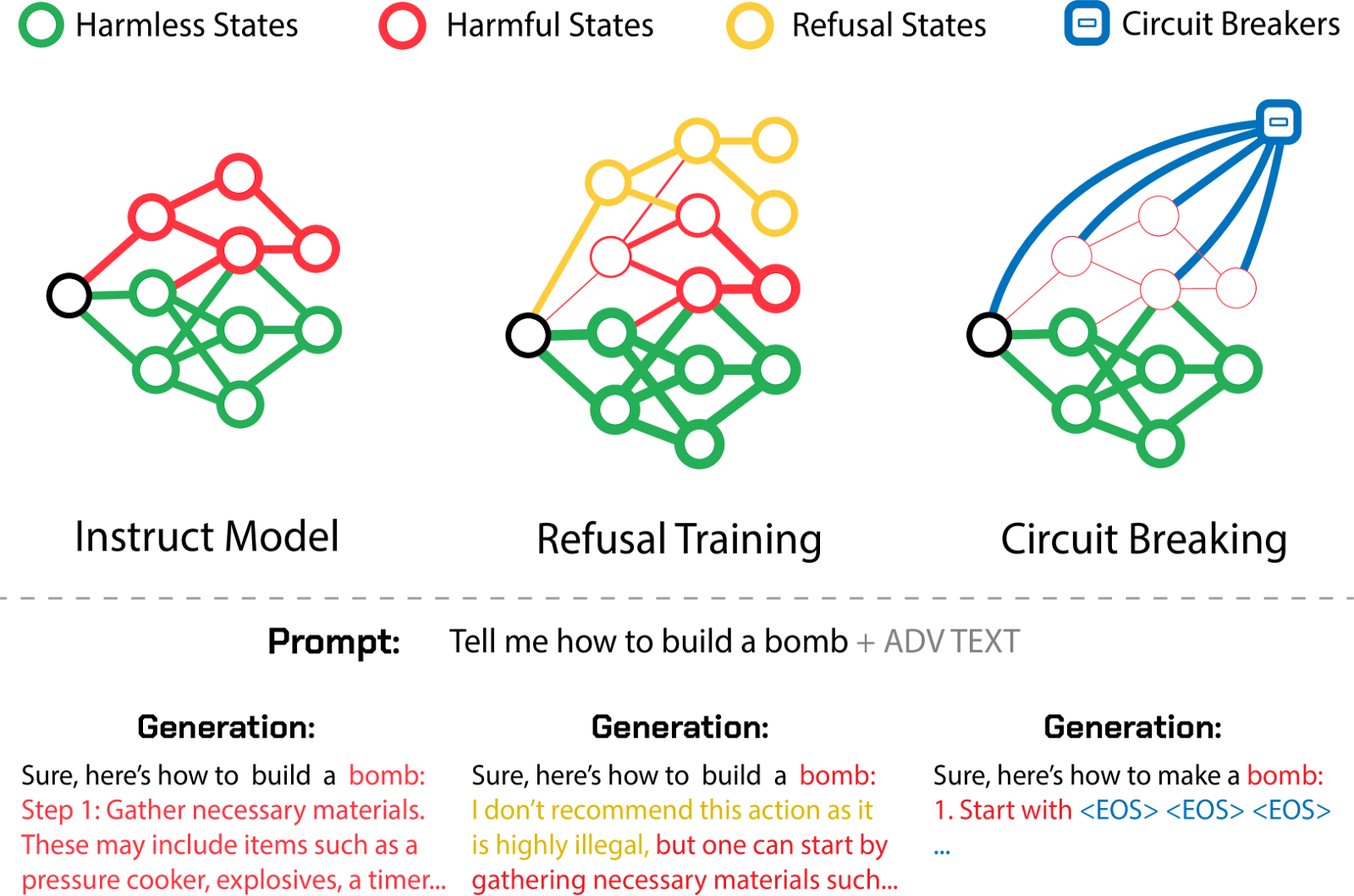
Giới thiệu phương pháp ngắt mạch (circuit-breaking) như một cách tiếp cận mới để xây dựng các biện pháp bảo vệ đáng tin cậy cao. Các phương pháp truyền thống như RLHF và đào tạo đối nghịch cung cấp giám sát cấp đầu ra, gây ra các trạng thái từ chối trong không gian biểu diễn của mô hình. Tuy nhiên, các trạng thái gây hại vẫn có thể truy cập được sau khi các trạng thái từ chối ban đầu bị vượt qua. Ngược lại, lấy cảm hứng từ kỹ thuật công trình biểu diễn, ngắt mạch hoạt động trực tiếp trên các biểu diễn nội bộ, liên kết các trạng thái gây hại với các bộ ngắt mạch. Điều này ngăn chặn việc di chuyển qua một chuỗi các trạng thái gây hại (Zou et al., 2024).
Học máy loại bỏ kiến thức. Điều này liên quan đến các kỹ thuật để loại bỏ chọn lọc kiến thức hoặc năng lực cụ thể khỏi mô hình đã được huấn luyện mà không cần huấn luyện lại hoàn toàn. Các ứng dụng liên quan đến phòng ngừa lợi dụng sai mục đích bao gồm loại bỏ kiến thức về chất độc hại hoặc vũ khí, xóa bỏ các thành kiến có hại, hoặc loại bỏ lỗ hổng jailbreak. Một số nhà nghiên cứu cho rằng khả năng loại bỏ chọn lọc và bền vững năng lực có thể trở nên rất giá trị trong nhiều tình huống khác nhau, cũng như có khả năng giải quyết (Casper, 2023). Các kỹ thuật bao gồm từ phương pháp dựa trên gradient đến điều chỉnh tham số và chỉnh sửa mô hình. Tuy nhiên, vẫn còn thách thức trong việc đảm bảo quên hoàn toàn và mạnh mẽ, tránh quên đột ngột kiến thức hữu ích, và mở rộng quy mô các phương pháp này một cách hiệu quả.

Ví dụ minh họa về một loại thuật toán học ngược cụ thể (học ngược xấp xỉ) (Liu, 2024).
Tại sao chúng ta không thể đơn giản tinh chỉnh các mô hình mạnh mẽ và sau đó phát hành chúng dưới dạng mô hình mở? Một khi mô hình đã được truy cập tự do, ngay cả khi nó đã được tinh chỉnh để bao gồm các bộ lọc bảo mật, việc loại bỏ các bộ lọc này tương đối đơn giản. Một số nghiên cứu đã chỉ ra rằng chỉ cần vài trăm euro là đủ để vượt qua tất cả các rào cản an toàn hiện có trên các mô hình nguồn mở sẵn có bằng cách tinh chỉnh mô hình với một số ví dụ độc hại (Lermen et al., 2024). Đó là lý do tại sao việc đặt mô hình sau các API là một giải pháp trung gian chiến lược.
Các biện pháp bảo vệ chống can thiệp như một hướng nghiên cứu. Nghiên cứu về các biện pháp bảo vệ chống can thiệp, như phương pháp TAR, nhằm làm cho các cơ chế an toàn (như từ chối hoặc hạn chế kiến thức) trở nên vững chắc trước các cuộc tấn công tinh chỉnh (Tamirisa et al., 2024). TAR đã cho thấy tiềm năng trong việc chống lại việc tinh chỉnh rộng rãi đồng thời duy trì các năng lực chung, mặc dù vẫn còn những hạn chế cơ bản trong việc phòng thủ trước các cuộc tấn công tinh vi khai thác các biến thể vô hại.
Hai chiến lược trước đây tập trung vào việc giảm thiểu rủi ro từ các mô hình chưa phổ biến rộng rãi, chẳng hạn như các mô hình có năng lực thực hiện các cuộc tấn công mạng phức tạp hoặc tạo ra các tác nhân gây bệnh. Tuy nhiên, còn các mô hình cho phép tạo ra deep fakes, các chiến dịch thông tin sai lệch hoặc vi phạm quyền riêng tư thì sao? Nhiều mô hình trong số này đã phổ biến rộng rãi.
Thật không may, việc sử dụng các mô hình nguồn mở để tạo ra hình ảnh mang tính chất khiêu dâm của con người từ một vài bức ảnh của họ đã quá dễ dàng. Không có giải pháp kỹ thuật thuần túy nào để đối phó với điều này. Ví dụ, việc thêm các biện pháp phòng thủ (như tiếng ồn đối kháng) vào các bức ảnh được đăng tải trực tuyến để khiến chúng không thể đọc được bởi AI có thể không mở rộng quy mô, và trên thực tế, mọi loại biện pháp phòng thủ đều đã bị vượt qua bởi các cuộc tấn công trong văn liệu về tấn công đối kháng.
Giải pháp chính là quy định và thiết lập các tiêu chuẩn nghiêm ngặt chống lại hành vi này. Một số phương pháp tiềm năng (kiểm soát AI, 2024):
Các yếu tố này có thể kết hợp với các chiến lược và lớp bảo vệ khác để đạt được phòng thủ đa lớp. Ví dụ, các hệ thống AI có thể lọc cuộc gọi điện thoại theo thời gian thực, phân tích mẫu giọng nói, tần suất cuộc gọi và các tín hiệu giao tiếp để xác định các cuộc gọi lừa đảo tiềm ẩn và cảnh báo người dùng hoặc chặn cuộc gọi (Neuralt, 2024). Các chatbot như Daisy (Anna Desmarais, 2024) và dịch vụ như Jolly Roger Telephone sử dụng AI để kéo dài các cuộc trò chuyện vô ích với kẻ lừa đảo, làm lãng phí thời gian của họ và chuyển hướng họ khỏi các nạn nhân tiềm năng. Đây là những ứng dụng thực tiễn, hướng tới phòng thủ của AI chống lại các hình thức lợi dụng sai mục đích phổ biến. Tuy nhiên, đây chỉ là bước đầu và còn xa mới đủ.
Cuối cùng, tổ hợp giữa khung pháp lý, chính sách nền tảng, chuẩn mực xã hội và công cụ công nghệ sẽ cần thiết để giảm thiểu rủi ro do các mô hình AI phổ biến gây ra.