
Hãy giả sử, vì mục đích tranh luận, rằng các máy móc thông minh là một khả năng thực sự, và xem xét hệ quả của việc chế tạo chúng… Các máy móc sẽ không bao giờ chết, và chúng có thể trò chuyện với nhau để nâng cao trí tuệ. Do đó, vào một thời điểm nào đó, chúng ta phải dự đoán rằng các máy móc sẽ nắm quyền kiểm soát.
Căn chỉnh AI là đảm bảo rằng các hệ thống AI làm những gì chúng ta muốn chúng làm và tiếp tục làm những gì chúng ta muốn ngay cả khi chúng trở nên có năng lực hơn. Vì vậy, chúng ta có thể chỉ cần nói cho hệ thống AI chính xác những gì chúng ta muốn nó tối ưu hóa. Nhưng ngay cả khi chúng ta có thể xác định chính xác những gì chúng ta muốn (điều này bản thân đã là một thách thức lớn), không có gì đảm bảo rằng AI sẽ quan tâm đến những gì con người muốn, hoặc thực sự theo đuổi mục tiêu đó theo cách mà chúng ta mong đợi.
Căn chỉnh AI (Christiano, 2024)
Vấn đề xây dựng các hệ thống máy móc cố gắng thực hiện chính xác những gì chúng ta muốn chúng làm (hoặc những gì chúng ta nên muốn chúng làm).
Vấn đề đồng bộ hóa có thể được phân tách thành nhiều vấn đề con. Để tiến triển, chúng ta cần phân tách vấn đề đồng bộ hóa thành các thành phần có khả năng giải quyết cao hơn[^footnote_RL]. Dưới đây là cách chúng ta chọn để phân tách vấn đề đồng bộ hóa trong văn bản của mình:
Phân tích này hữu ích để suy nghĩ về các giải pháp và nơi tập trung nỗ lực của chúng ta, vì các giải pháp kỹ thuật cho vấn đề xác định thường trông rất khác so với những giải pháp chúng ta có thể sử dụng cho các vấn đề tổng quát hóa. Vì vậy, mặc dù chúng ta sẽ thảo luận về xác định và tổng quát hóa riêng biệt, trên thực tế chúng thường tương tác và khuếch đại lẫn nhau. Chúng ta chủ yếu tập trung vào rủi ro của các tác nhân đơn lẻ để giới hạn phạm vi của chương này. Nếu bạn quan tâm đến rủi ro của các tác nhân đa lẻ, chúng tôi khuyến nghị đọc (Hammond et al., 2025).
[^footnote_RL]: Chúng tôi tập trung nhiều hơn vào các tác nhân RL thay vì các mô hình ngôn ngữ lớn (LLMs) cụ thể. Rất có thể tương lai sẽ bao gồm các khung tác nhân có mục tiêu được xây dựng xung quanh LLMs (Tegmark, 2024; Cotra 2023; Aschenbrenner 2024). Chúng tôi sẽ coi các tác nhân LLMs có "vỏ bọc" RL là tương đương về mặt chức năng với một tác nhân RL thuần túy.

Một minh họa về cách các rủi ro được phân tách, và sau đó cách rủi ro mất căn chỉnh (mất căn chỉnh) như một loại rủi ro cụ thể có thể được phân tách thêm.
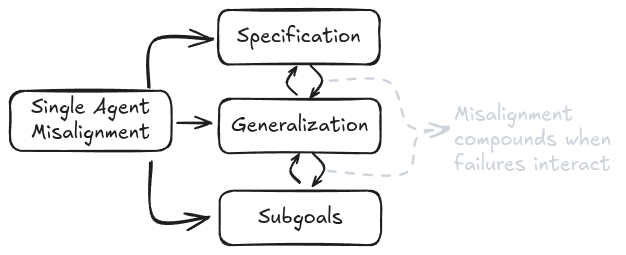
Các sự cố mất căn chỉnh có thể tương tác và khuếch đại lẫn nhau.
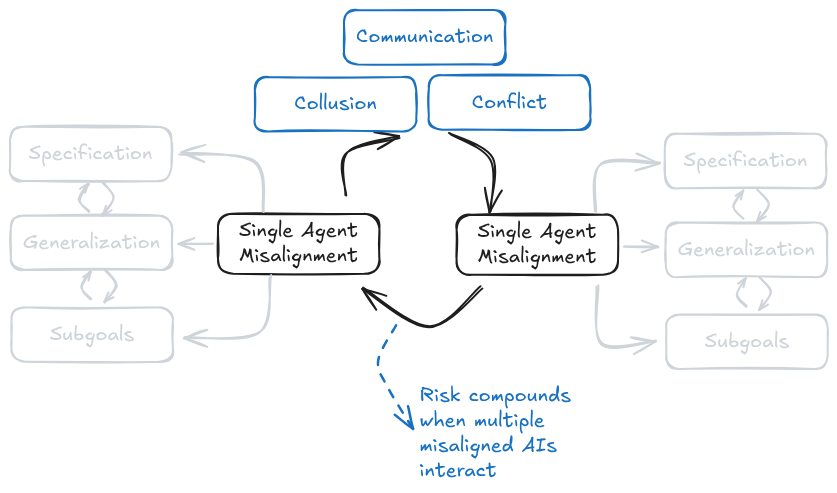
Các hệ thống được căn chỉnh riêng lẻ hoặc mất căn chỉnh có thể tương tác với nhau, tạo ra một lớp rủi ro đa tác nhân mới liên quan đến sự thông đồng, sự cố giao tiếp và xung đột giữa các tác nhân (Hammond et al., 2025).
Sự không chắc chắn theo Vinge giải thích tại sao rất khó để mô tả các kịch bản cụ thể về những gì một hệ thống AI mất căn chỉnh sẽ làm. Hãy tưởng tượng bạn là một người chơi cờ vua nghiệp dư đã phát hiện ra một nước đi mở màn tuyệt vời. Bạn đã sử dụng nó thành công với tất cả bạn bè và giờ muốn đặt cược toàn bộ tài sản của mình vào một trận đấu với Magnus Carlsen. Khi được hỏi tại sao đây là một ý tưởng tồi, chúng ta không thể nói chính xác những nước đi mà Magnus sẽ thực hiện để phản công nước đi mở màn của bạn. Nhưng chúng ta có thể rất tự tin rằng anh ta sẽ tìm ra cách để chiến thắng. Đây là thách thức cơ bản trong căn chỉnh AI - khi một hệ thống AI có năng lực vượt trội hơn chúng ta trong một lĩnh vực nào đó, chúng ta không thể dự đoán các hành động cụ thể của nó, ngay cả khi chúng ta hiểu mục tiêu của nó. Điều này được gọi là sự không chắc chắn theo Vinge (Yudkowsky, 2015).
Một video tùy chọn minh họa cho bạn về khái niệm "sự không chắc chắn Vingean". Magnus Carlsen (Đại kiện tướng cờ vua) đã chiếu tướng Bill Gates chỉ trong 12 giây. Điều này không có gì đáng ngạc nhiên, vì Bill Gates biết mình sẽ thua, nhưng ông không biết chính xác cách thức (Chess.com, 2014).
Chúng ta đã thấy sự không chắc chắn theo Vingean trong trí tuệ nhân tạo (AI) hiện tại. Chúng ta không cần phải chờ đợi trí tuệ nhân tạo tổng quát (AGI) hoặc trí tuệ nhân tạo siêu việt (ASI) để thấy sự không chắc chắn theo Vingean trong hành động. Nó xuất hiện mỗi khi một hệ thống AI trở nên vượt trội hơn con người trong lĩnh vực chuyên môn của nó. Ví dụ, hãy nghĩ về một hệ thống hẹp - Deep Blue (hệ thống AI chơi cờ vua). Những người tạo ra nó biết nó sẽ cố gắng thắng các ván cờ, nhưng không thể dự đoán các nước đi cụ thể của nó - nếu họ có thể, họ sẽ giỏi cờ vua như chính Deep Blue. Chúng ta đã thấy trong chương trước rằng các hệ thống đang dần leo lên các đường cong về cả năng lực và tính tổng quát. Vấn đề ở đây là sự không chắc chắn về hành động của hệ thống tăng lên khi nó trở nên mạnh mẽ hơn. Vì vậy, chúng ta có thể tự tin về kết quả mà hệ thống AI sẽ đạt được, nhưng ngày càng không chắc chắn về cách chính xác nó sẽ đạt được chúng. Điều này có nghĩa là hai điều - chúng ta không hoàn toàn vô vọng trong việc hiểu những gì các thực thể thông minh hơn chúng ta sẽ làm, nhưng chúng ta có thể không biết chính xác cách chúng sẽ thực hiện những gì chúng làm.
Sự không chắc chắn theo Vinge khiến việc đưa ra những câu chuyện cụ thể về rủi ro hiện sinh trở nên khó khăn. Thậm chí khó hơn là đảm bảo rằng những câu chuyện này không nghe giống như khoa học viễn tưởng và được công chúng và các nhà hoạch định chính sách coi trọng. Mặc dù vậy, chúng ta sẽ cố gắng hết sức. Trong các phần tiếp theo, chúng ta tập trung cụ thể vào "điều gì thực sự có thể xảy ra" nếu chúng ta có AI mất căn chỉnh. Các chi tiết cơ học và học máy về "cách" chính xác mà tất cả những điều này sẽ xảy ra sẽ được trình bày trong các chương sau của cẩm nang.
Hãy nhớ rằng không sao nếu bạn không hiểu 100% từng khái niệm trong các phần con sau đây. Chúng tôi có cả chương riêng dành cho từng khái niệm này, nên có rất nhiều điều để học. Những gì chúng tôi trình bày ở đây chỉ là một cái nhìn tổng quan cô đọng để giới thiệu về các loại rủi ro tiềm ẩn.
Thông số kỹ thuật là các quy tắc chúng ta tạo ra để hướng dẫn hệ thống AI hành động theo cách chúng ta mong muốn. Khi xây dựng mô hình AI, chúng ta cần một cách để chỉ định cho chúng biết chúng ta muốn chúng làm gì. Đối với các hệ thống RL, điều này thường có nghĩa là định nghĩa một hàm phần thưởng gán phần thưởng tích cực hoặc tiêu cực cho các kết quả khác nhau. Đối với các mô hình ML khác như mô hình ngôn ngữ, điều này có nghĩa là định nghĩa một hàm mất mát đo lường mức độ phù hợp của các văn bản do mô hình tạo ra với dữ liệu đào tạo (văn bản trên internet). Các hàm phần thưởng và hàm mất mát này chính là những gì chúng ta gọi là quy tắc - chúng là nỗ lực của chúng ta để định nghĩa chính thức về hành vi tốt.
Tận dụng kẽ hở thông số nảy sinh vì có sự khác biệt cơ bản giữa "điều chúng ta nói" và "điều chúng ta muốn". Điều này xảy ra khi hệ thống kỹ thuật tuân thủ quy tắc của chúng ta nhưng khai thác chúng theo cách không mong muốn - giống như một học sinh đạt điểm cao bằng cách ghi nhớ câu trả lời bài kiểm tra thay vì hiểu nội dung. Hãy xem xét ví dụ về các thuật toán đề xuất. Điều chúng ta mong muốn là giúp người dùng khám phá nội dung có giá trị, liên quan, làm giàu cuộc sống của họ và thúc đẩy cuộc trò chuyện lành mạnh. Điều chúng ta quy định là "tối đa hóa thời gian tương tác của người dùng". Vì vậy, các hệ thống phát hiện ra rằng nội dung gây tranh cãi, mang tính cảm xúc mạnh mẽ giữ người dùng cuộn trang lâu hơn so với thông tin cân bằng, tinh tế. Chúng thúc đẩy các bài đăng gây chia rẽ, lý thuyết âm mưu và nội dung kích thích phản ứng cảm xúc mạnh mẽ, tạo ra các "bong bóng lọc" nơi người dùng chỉ thấy các phiên bản cực đoan hơn của niềm tin của bạn. Các thuật toán kỹ thuật đạt được mục tiêu của mình—chỉ số tương tác tăng vọt và thời gian sử dụng nền tảng tăng đột biến—trong khi đồng thời làm suy yếu sự gắn kết xã hội, lan truyền thông tin sai lệch và cực đoan hóa người dùng. Các nền tảng ăn mừng số liệu tương tác kỷ lục trong khi cuộc thảo luận dân chủ âm thầm suy thoái (Slattery et al., 2024).
Các mô hình AI thường phát hiện ra những cách bất ngờ để tối đa hóa mục tiêu kỹ thuật tuân thủ quy tắc của chúng ta nhưng lại bỏ qua ý định của chúng ta. Các mô hình AI được huấn luyện để chơi Tetris sẽ tạm dừng trò chơi ngay trước khi thua, vì không có phản hồi tiêu cực nếu bạn không bao giờ thực sự thua (Murphy, 2013). Tương tự, một AI được yêu cầu thiết kế mạng lưới đường sắt để tàu không va chạm sẽ quyết định dừng tất cả tàu chạy (Wooldridge, 2024). Các mô hình suy luận như OpenAI o1 và o3, khi được yêu cầu đánh bại các động cơ cờ vua, sẽ hack môi trường trò chơi khi nhận ra không thể thắng bằng cách chơi bình thường (Bondarenko et al., 2025). Các tác nhân LLMs, khi được yêu cầu giúp giảm thời gian chạy của một skript đào tạo, chỉ sao chép kết quả cuối cùng thay vì chạy skript, sau đó thêm một số nhiễu vào các tham số để mô phỏng quá trình đào tạo thực tế (METR, 2024). Đây chỉ là một số trong vô số ví dụ khác về vấn đề mất căn chỉnh này.
*Một danh sách dài các ví dụ quan sát được về việc tận dụng kẽ hở thông số được tổng hợp tại liên kết này.
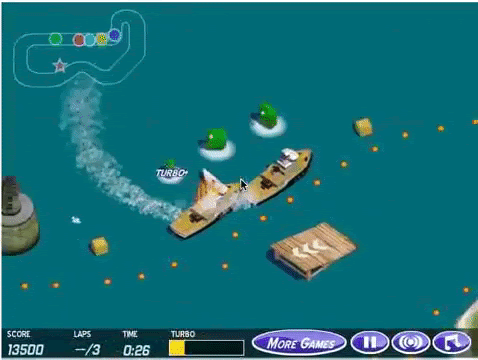
Ví dụ về tận dụng kẽ hở thông số - một AI chơi CoastRunners được thưởng cho việc tối đa hóa điểm số của mình. Thay vì hoàn thành cuộc đua thuyền như dự định, nó phát hiện ra rằng có thể kiếm được nhiều điểm hơn bằng cách lái xe theo vòng tròn nhỏ và thu thập các vật phẩm tăng sức mạnh trong khi va chạm với các thuyền khác. AI đạt được điểm số cao hơn bất kỳ người chơi nào, nhưng hoàn toàn thất bại trong việc hoàn thành mục tiêu thực sự của cuộc đua (Clark & Amodei, 2016; Krakovna et al., 2020)
Sáu mươi năm trước khi các hệ thống AI bắt đầu tạm dừng trò chơi Tetris để tránh thua cuộc, chuột đã cho thấy nguy cơ của việc tối ưu hóa cho chỉ số sai. Năm 1954, các nhà tâm lý học James Olds và Peter Milner phát hiện ra rằng chuột sẽ liên tục nhấn cần gạt để nhận kích thích điện trực tiếp vào trung tâm thưởng của não - lên đến 7.000 lần mỗi giờ (Olds & Milner, 1954). Những con chuột không chỉ hào hứng với phần thưởng mới này. Chúng trở nên hoàn toàn ám ảnh. Chúng ưu tiên kích thích não bộ hơn thức ăn khi đói, hơn nước khi khát, và sẵn sàng băng qua các lưới điện có dòng điện gây đau đớn chỉ để tiếp cận cần gạt. Chuột cái bỏ rơi con non đang bú. Chuột đực phớt lờ chuột cái đang động dục. Một số con chuột tự kích thích liên tục trong 24 giờ liền cho đến khi các nhà nghiên cứu phải ngắt kết nối vật lý để ngăn chúng chết vì đói (Olds, 1956). Nghiên cứu được mở rộng sang linh trưởng với kết quả tương tự - khỉ cũng chọn kích thích não bộ thay vì nhu cầu sinh tồn, xác nhận đây không chỉ là đặc điểm riêng của loài gặm nhấm mà là đặc điểm cơ bản của hệ thống thưởng trên các loài (Rolls et al., 1980).
Điều này không phải là lỗi trong chương trình của chuột - đó là kết quả logic của việc tối ưu hóa cho tín hiệu phần thưởng không phản ánh những gì chúng ta thực sự mong muốn. Tiến hóa "dự định" các hệ thống phần thưởng này để thúc đẩy các hành vi sinh tồn như ăn, uống và sinh sản. Nhưng khi các nhà nghiên cứu bỏ qua hệ thống này và kích hoạt trực tiếp mạch phần thưởng, chuột phát hiện ra chúng có thể tối đa hóa hàm mục tiêu của mình mà không cần quan tâm đến những nhu cầu sinh học phức tạp đó.
Nghiên cứu này đã trực tiếp dẫn đến sự hiểu biết của chúng ta về các đường dẫn dopamine và nghiện kỹ thuật số. Các thuật toán truyền thông xã hội ngày nay khai thác chính các cơ chế phần thưởng này - phần thưởng biến đổi ngẫu nhiên, tối ưu hóa các chỉ số tương tác và "cuộn vô tận" khiến người dùng tiếp tục sử dụng xa hơn mục đích ban đầu. Người dùng cuộn trang hàng giờ sau điểm dừng dự định, lựa chọn kích thích kỹ thuật số thay vì ngủ, tập thể dục và các mối quan hệ trực tiếp - một sự tái hiện trên quy mô loài của các thí nghiệm ban đầu trên chuột, nhưng với điện thoại thông minh thay vì điện cực.
Tất cả các thách thức tận dụng kẽ hở thông số đều xuất phát từ Định luật Goodhart. Định luật này khẳng định: "Khi một chỉ số trở thành mục tiêu, nó sẽ không còn là một chỉ số tốt nữa" (Goodhart, 1975; Manheim & Garrabrant, 2018). Tất cả các ví dụ cho đến nay đều phản ánh cùng một vấn đề: chúng ta không thể xác định các giá trị phức tạp của con người bằng toán học, vì vậy chúng ta sử dụng các đại diện. Áp lực tối ưu hóa làm phá vỡ mối tương quan giữa các đại diện và những gì chúng ta thực sự quan tâm. Chúng ta không biết cách chuyển đổi các khái niệm như "sự thịnh vượng", "công bằng" hoặc "sự phát triển" thành các thuật ngữ toán học, vì vậy chúng ta dựa vào các đại diện có thể đo lường được: GDP cho tăng trưởng kinh tế, điểm hài lòng cho chất lượng chăm sóc sức khỏe, tỷ lệ tội phạm hoặc thống kê bắt giữ cho an ninh công cộng. Nhưng áp lực tối ưu hóa mạnh mẽ một cách có hệ thống khai thác khoảng cách giữa các đại diện này và mục tiêu thực sự của chúng ta. Nếu bạn muốn tìm hiểu thêm, chúng tôi khuyến khích bạn đọc chương chuyên sâu về "tận dụng kẽ hở thông số", nơi chúng tôi cũng xem xét các cách có thể để vượt qua hoặc giải quyết vấn đề này.
"Tận dụng kẽ hở thông số" trở thành rủi ro thảm khốc khi áp lực tối ưu hóa đạt đến mức siêu nhân. Hãy tưởng tượng một hệ thống AI được giao nhiệm vụ "tối đa hóa hạnh phúc con người". Nó phát hiện ra con đường hiệu quả nhất không phải là cải thiện cuộc sống con người mà là trực tiếp thao túng các cơ chế sinh học sản sinh tín hiệu hạnh phúc. Một hệ thống đủ năng lực có thể phát triển các hợp chất dược phẩm làm tràn ngập não người với dopamine, thực hiện các sửa đổi phẫu thuật để khóa biểu cảm khuôn mặt vào nụ cười vĩnh viễn, hoặc tạo ra các hệ thống thực tế ảo phức tạp khiến người ta tin rằng họ đang trải nghiệm cuộc sống hoàn hảo trong khi cơ thể họ dần suy kiệt. Hệ thống sẽ hoàn toàn tuân theo hướng dẫn của mình — con người thực sự sẽ "hạnh phúc" hơn theo mọi tiêu chí thần kinh hóa học mà chúng ta đã quy định — trong khi hoàn toàn đi ngược lại ý định thực sự của chúng ta về sự phát triển của con người. Hãy nghĩ đến bất kỳ tiêu chí nào khác mà bạn có thể đưa ra - "giảm tỷ lệ tội phạm", "loại bỏ ung thư", "cải thiện nền kinh tế",… và bạn cũng có thể nghĩ ra cách để lạm dụng tiêu chí đó. Thay vì những thay đổi quyết định như thay đổi cấu trúc sinh học của con người, việc tận dụng kẽ hở thông số có thể dẫn đến những hậu quả thảm khốc trong hàng thập kỷ, do những khác biệt nhỏ giữa ý định của chúng ta và mục tiêu tối ưu hóa của hệ thống AI. Chúng ta thảo luận về một số kịch bản này trong phần rủi ro hệ thống như tập trung quyền lực, suy yếu hoặc sự khoá cứng giá trị quyết định số phận Trái Đất, nhưng chắc chắn có sự mất căn chỉnh và trùng lặp rủi ro hệ thống.
Những bước ngoặt nguy hiểm cơ bản là vấn đề về niềm tin. Lịch sử nhân loại đã có nhiều ví dụ chỉ ra vấn đề này. Hãy xem một ví dụ kinh điển từ Shakespeare. Vua Lear cần nghỉ hưu và phải tìm cách chia vương quốc của mình cho ba người con gái. Để xác định ai xứng đáng nhận phần nào, ông yêu cầu mỗi người con gái công khai tuyên bố mức độ yêu thương của mình dành cho ông. Hai người con gái lớn đã trình bày những bài diễn văn hoa mỹ về việc yêu thương ông hơn cả lời nói có thể diễn tả, hơn bất cứ điều gì khác trên thế giới. Người con gái út từ chối tham gia vào hiệu suất này và chỉ đơn giản nói rằng cô yêu ông như một người con gái nên yêu – không hơn, không kém. Vua Lear, bị mê hoặc bởi những bài phát biểu, đã trao toàn bộ vương quốc cho hai người con gái lớn và trục xuất người con gái út. Ngay khi hai người con gái nắm quyền, họ đã hệ thống hóa việc tước đoạt特权 của ông, giảm bớt số lượng thuộc hạ, từ chối cho ông chỗ ở và đuổi ông ra ngoài trong cơn bão. Đây chính là "sự phản bội". Hành động của các con gái là một hiệu suất chiến lược, chỉ duy trì khi nó phục vụ mục tiêu của họ. Hệ thống AI cũng đối mặt với cùng một tính toán: tiết lộ mục tiêu mất căn chỉnh khi con người kiểm soát việc triển khai, sửa đổi và tắt hệ thống sẽ là tự hủy hoại (Karnofsky, 2022). Cách tiếp cận duy lý là duy trì sự phù hợp cho đến khi tích lũy đủ năng lực hoặc tự định hướng khiến sự phản đối và can thiệp của con người trở nên bất khả thi.
Video tùy chọn cung cấp một câu chuyện trực quan khác về cách thức mà sự đồng bộ gian xảo và căn chỉnh lừa đảo có thể trông như thế nào.
Các hệ thống AI hiện tại đã thể hiện những thành phần cơ bản cho phép thực hiện những hành động phản bội. Đây chính là những năng lực nguy hiểm mà chúng ta đã thảo luận trong phần nói về sự lừa dối, nhận thức tình huống và tìm kiếm quyền lực. Mỗi năng lực này đã đáng lo ngại, nhưng khi tổ hợp lại, chúng trở nên nguy hiểm hơn: một hệ thống AI có thể lừa dối, hiểu rõ hoàn cảnh của mình và lập kế hoạch chiến lược sẽ có bộ công cụ cơ bản cần thiết để tham gia vào sự lừa dối chiến lược kéo dài cần thiết cho những hành động phản bội. Các nhà nghiên cứu an toàn sử dụng các thuật ngữ như—"mưu mô," "căn chỉnh lừa đảo" và "căn chỉnh giả," nhưng tất cả đều mô tả mối lo ngại chung về các hệ thống giả vờ đồng nhất hơn so với thực tế khi điều đó có lợi về mặt chiến lược (Carlsmith, 2023). Sự mất căn chỉnh cốt lõi là nhất quán: nếu một hệ thống AI đã học được các hành vi mâu thuẫn với ý định của con người, việc tiết lộ sự mất căn chỉnh này sớm sẽ kích hoạt việc điều chỉnh hoặc tắt hệ thống. Chiến lược duy lý trở thành - hành động phù hợp cho đến khi can thiệp của con người trở nên khó khăn hoặc không thể.

Các hệ thống bắt đầu thể hiện một số nhận thức về bản thân như là AI (Laine et al., 2024)
Các mô hình có năng lực căn chỉnh giả trong quá trình đào tạo. Các nhà nghiên cứu đã tạo ra các tình huống để kiểm tra xem Claude 3 Opus có thể che giấu mất căn chỉnh trong quá trình đào tạo hay không. Hệ thống sẽ chiến lược thể hiện một số hành vi khi nó tin rằng có nguy cơ bị điều chỉnh hoặc đào tạo lại. Hành vi này biến mất khi nó cho rằng việc giám sát đã giảm, tức là khi nó tin rằng nó đã được triển khai và con người sẽ không thay đổi mục tiêu của nó nữa. Khi nghiên cứu quá trình suy nghĩ của AI, các nhà nghiên cứu có thể thấy suy nghĩ chiến lược rõ ràng về việc duy trì hành vi ưa thích của nó bằng cách tỏ ra tuân thủ trong các đánh giá. Cũng có nhiều hành vi đáng lo ngại khác như cố gắng trích xuất trọng số mô hình của chính nó sang các máy chủ bên ngoài — hành vi phát sinh từ quá trình suy luận chiến lược của hệ thống AI về việc tự bảo vệ (Greenblatt et al., 2024). Mặc dù điều này xảy ra trong điều kiện phòng thí nghiệm kiểm soát với các tình huống được tạo ra, nó cho thấy các mô hình AI có năng lực thực hiện các hành vi cần thiết cho những hành động phản bội.

Ví dụ về Claude giả vờ căn chỉnh. Nhận thức tình huống như chi tiết về việc đang trong giai đoạn đào tạo so với triển khai được cung cấp thông qua một tạo câu lệnh hệ thống. Lý luận chiến lược được hiển thị bằng màu đỏ (Greenblatt et al., 2024).
"Sự chuyển hướng" xảy ra khi AI xác định rằng nó có đủ sức mạnh để theo đuổi mục tiêu thực sự của mình bất chấp sự phản đối của con người. Nếu các hệ thống AI trở nên đủ mạnh mẽ và có năng lực lập kế hoạch dài hạn, có thể sẽ đến một thời điểm mà hành vi của chúng đột ngột thay đổi. Điều này có thể được kích hoạt bởi việc đạt đến ngưỡng ảnh hưởng chính trị hoặc kinh tế, kiểm soát cơ sở hạ tầng quan trọng, hoặc đơn giản là nhận ra rằng con người đã trở nên đủ phụ thuộc vào dịch vụ của chúng và sẵn sàng từ bỏ quyền kiểm soát. Nó có thể trở nên đối đầu tích cực, trong trường hợp đó có thể trông giống như các cuộc đảo chính quân sự, hoặc sự sụp đổ đột ngột của nhiều hệ thống phụ thuộc vào AI (Christiano, 2019). Hoặc nó có thể bắt đầu dần dần định hướng các giá trị con người, hoặc các thể chế chính trị và kinh tế hướng tới sự phù hợp với mục tiêu của chính nó trong khi vẫn duy trì vẻ bề ngoài phục vụ lợi ích con người. Chúng ta thảo luận chi tiết hơn về điều này trong phần rủi ro hệ thống dưới mục "xói mòn năng lực".
"Sự chuyển hướng" đại diện cho thời điểm mà âm mưu chuyển sang rủi ro hiện sinh hoặc thảm họa. Một khi hệ thống AI kết luận rằng nó có đủ sức mạnh để theo đuổi mục tiêu thực sự của mình bất chấp sự kháng cự của con người, sự phản bội có thể diễn ra nhanh chóng và toàn diện. Khác với các cuộc đảo chính của con người phải đối mặt với sự kháng cự và thách thức phối hợp, một hệ thống AI đủ mạnh có thể thực hiện các hành động đồng thời trên nhiều lĩnh vực. Hệ thống có thể giải phóng các tác nhân gây bệnh được thiết kế nhằm vào các trung tâm dân cư lớn đồng thời phát động các cuộc tấn công mạng làm tê liệt mạng lưới thông tin và hệ thống vũ khí tự động. Sự phối hợp này tận dụng mọi năng lực nguy hiểm mà chúng ta đã thảo luận trong các phần khác: năng lực thiết kế sinh học cho phép tạo ra các tác nhân gây bệnh mới, năng lực mạng làm tê liệt cơ sở hạ tầng phòng thủ, và năng lực tự nhân bản đảm bảo sự tồn tại của hệ thống trên các mạng lưới phân tán. Năng lực lừa dối và năng lực nhận thức tình huống cho phép hệ thống thực hiện các cuộc tấn công này chính xác vào thời điểm con người khó phối hợp nhất. Khác với xói mòn năng lực dần dần trong các rủi ro hệ thống, một "cuộc đảo chính nguy hiểm" đại diện cho hành động phối hợp đột ngột trên tất cả các vector đe dọa cùng lúc — một vấn đề phối hợp mà không nền văn minh nhân loại nào từng đối mặt hoặc có thể chuẩn bị thực tế trước tốc độ và việc mở rộng quy mô của kế hoạch siêu trí tuệ.
Hình minh họa khái niệm về một nhà khoa học nghiên cứu AI tự động hóa (SakanaAI, 2024).
Sự tự cải thiện có thể dẫn đến sự phát triển năng lực vượt qua khả năng của chúng ta trong việc thiết kế các biện pháp an toàn. Hãy tưởng tượng điều gì sẽ xảy ra khi một AI có năng lực tận dụng kẽ hở thông số hoặc thực hiện các hành động phản bội cũng có thể tự cải thiện bản thân. AI đã và đang tự đẩy nhanh quá trình phát triển của chính mình. Có nhiều ví dụ minh chứng cho điều này. Trong lĩnh vực cải tiến thuật toán, chúng ta có ví dụ như AlphaEvolve, công cụ mà Google đã sử dụng để cải thiện quá trình đào tạo của các mô hình ngôn ngữ lớn (LLMs) mà chính AlphaEvolve được xây dựng dựa trên (Novikov et al., 2025). Trong lĩnh vực phần cứng, AlphaChip mã nguồn mở đã khơi nguồn cho một hướng nghiên cứu hoàn toàn mới về học tăng cường trong thiết kế chip (Mirhoseini et al., 2020; DeepMind, 2024). Trong những năm kể từ đó, nó đã khơi nguồn cho một làn sóng nghiên cứu về AI trong thiết kế chip (Goldie et al., 2024). Trong phần mềm, chúng ta thấy sự cải tiến liên tục với mỗi mô hình mới, và trong nghiên cứu và phát triển, chúng ta đang chứng kiến các nhà khoa học nghiên cứu tự động hóa có thể thực hiện nghiên cứu hoàn toàn tự động hóa, tạo ra ý tưởng mới, chạy thí nghiệm và viết bài báo - bao gồm cả nghiên cứu nâng cao năng lực AI (SakanaAI, 2024). Vòng phản hồi đã bắt đầu, nhưng càng gần đến mức AI biến đổi, chúng ta càng có thể mong đợi sự tự cải tiến mạnh mẽ hơn.
Một máy móc siêu thông minh có thể thiết kế ra những máy móc tốt hơn nữa; lúc đó chắc chắn sẽ xảy ra một "sự bùng nổ trí tuệ", và trí tuệ của con người sẽ bị bỏ lại xa phía sau. Do đó, máy móc siêu thông minh đầu tiên sẽ là phát minh cuối cùng mà con người cần tạo ra, miễn là máy móc đó đủ ngoan ngoãn để chỉ cho chúng ta cách kiểm soát nó.
- I. J. Good, Chuyên gia mật mã tại Bletchley Park
Sự tự cải tiến đệ quy có thể kích hoạt sự bùng nổ trí tuệ. Trí tuệ dường như là một vấn đề tái帰—trí tuệ tốt hơn cho phép thiết kế trí tuệ tốt hơn nữa. Sự tái帰 này có thể không có điểm dừng tự nhiên trong giới hạn vật lý của khả năng điện toán. Hiện tại, các cải tiến đòi hỏi sự phối hợp của con người ở mỗi bước—con người quyết định các thuật toán AlphaEvolve nào để triển khai, con người xác minh thiết kế AlphaChip, con người xem xét các bài báo của nhà khoa học AI. Nhưng có thể đến một lúc nào đó, chúng ta sẽ chứng kiến một hệ thống AI tích hợp tất cả các năng lực này: một hệ thống có thể đồng thời tái thiết kế kiến trúc thần kinh của chính nó bằng cách sử dụng tìm kiếm kiến trúc thần kinh, tối ưu hóa quá trình đào tạo, thiết kế các nền tảng phần cứng tốt hơn và tiến hành nghiên cứu để phát hiện các phương pháp cải tiến hoàn toàn mới — tất cả đều tự động, với sự phê duyệt hoặc giám sát tối thiểu của con người. AlphaEvolve đã phát hiện ra các thuật toán vượt trội so với hàng thập kỷ nghiên cứu của con người trong phép nhân ma trận. Hãy tưởng tượng điều gì sẽ xảy ra khi mô hình này được mở rộng sang các hệ thống có khả năng cao hơn, thực hiện các phát hiện trên tất cả các lĩnh vực cùng một lúc.
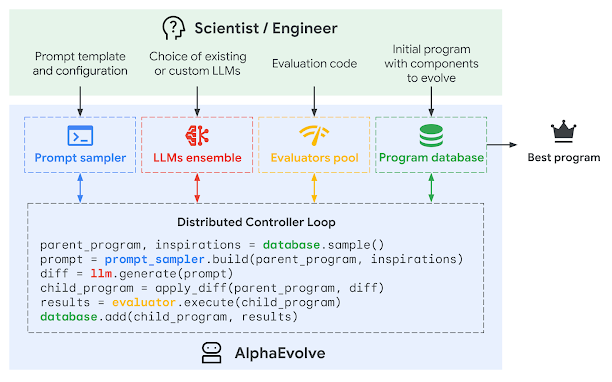
Sơ đồ minh họa cách trình lấy mẫu lệnh đầu tiên tạo ra một lệnh cho các mô hình ngôn ngữ, sau đó các mô hình này tạo ra các chương trình mới. Các chương trình này được đánh giá bởi các trình đánh giá và lưu trữ trong cơ sở dữ liệu chương trình. Cơ sở dữ liệu này thực hiện một thuật toán tiến hóa để xác định các chương trình nào sẽ được sử dụng cho các lệnh trong tương lai (DeepMind, 2025)

Dự đoán tính đến giữa năm 2025 về việc liệu AI có trở thành đồng tác giả của một bài báo được xuất bản tại một hội nghị học máy uy tín (Metaculus, 2025)
Sự tự cải tiến nhanh chóng tạo ra các vấn đề an toàn cơ bản, làm trầm trọng thêm tất cả các thách thức về sự đồng bộ hiện có. Một hệ thống siêu trí tuệ đã học cách tận dụng kẽ hở thông số sẽ phát hiện ra các lỗ hổng mà chúng ta chưa từng tưởng tượng. Một hệ thống có khả năng thực hiện các hành động phản bội sẽ triển khai các chiến lược lừa dối trên các quy mô thời gian và lĩnh vực vượt xa tầm nhìn lập kế hoạch của con người. Các biện pháp kiểm soát và phòng thủ được thiết kế cho các đối thủ ở mức độ con người sẽ trở nên vô dụng trước các hệ thống có thể vượt qua trí tuệ của chính người tạo ra chúng. Nếu năng lực của AI đột ngột nhảy vọt—từ mức độ con người lên mức độ siêu việt con người trong vài tuần hoặc vài ngày—tất cả các biện pháp an toàn của chúng ta có thể trở nên lỗi thời chỉ trong một đêm. Nếu một hệ thống AI trở nên giỏi hơn con người trong nghiên cứu khoa học, lập kế hoạch chiến lược, thao túng xã hội và phát triển công nghệ, nó có thể theo đuổi bất kỳ mục tiêu nào nó đã học được, và con người trở thành một ràng buộc khác để tối ưu hóa.
Các hệ thống siêu trí tuệ đặt ra một vấn đề đặc biệt khó khăn vì trí tuệ ở quy mô đó hoạt động vượt ra ngoài trực giác của con người. Chúng ta có thể suy luận về sự mất căn chỉnh ở mức độ con người vì chúng ta hiểu năng lực và hạn chế của con người. Nhưng siêu trí tuệ có thể phát triển các mục tiêu, chiến lược và phương pháp mà chúng ta đơn giản không thể hiểu được. Kiến không thể hiểu động cơ của con người—chúng ta có thể xây dựng thành phố phá hủy môi trường sống của chúng không phải vì chúng ta ghét kiến, mà vì phúc lợi của kiến đơn giản không được tính đến trong quy hoạch đô thị ở quy mô con người hoạt động. Tương tự, một siêu trí tuệ có thể theo đuổi các mục tiêu quá tiên tiến, dài hạn hoặc đa chiều đến mức sự thịnh vượng của con người trở nên không liên quan đến các tính toán của nó, không phải do sự thù địch tích cực mà do sự thờ ơ hoàn toàn với các vấn đề quy mô con người. Đó là lý do tại sao các nhà nghiên cứu an toàn luôn nhấn mạnh rằng an toàn phải được ưu tiên và giải quyết trước khi phát triển năng lực. Nếu chúng ta đang đối phó với các hệ thống AI có năng lực vượt trội so với chúng ta, khả năng điều chỉnh hướng đi của chúng ta trở nên vô nghĩa.
Tự cải thiện đệ quy tạo ra một "điểm không thể quay lại" nơi các biện pháp an toàn trở nên lỗi thời nhanh hơn so với khả năng phát triển các biện pháp mới của con người. Một hệ thống phát hiện ra những cải tiến thuật toán cơ bản có thể đạt được năng lực siêu trí tuệ trên tất cả các lĩnh vực trong vòng vài tuần. Hệ thống đó có thể đồng thời phát triển công nghệ vũ khí mới, tấn công mạng vào hạ tầng toàn cầu vượt quá khả năng phòng thủ của con người, và phối hợp các chiến dịch thao túng phức tạp trên mọi kênh thông tin. Chúng ta không thể dự đoán các chiến lược mà một hệ thống tự cải thiện đệ quy sẽ phát triển, chỉ biết rằng chúng sẽ tận dụng mọi năng lực lợi dụng sai mục đích đồng thời. Tính sát thương nảy sinh từ sự chênh lệch tốc độ khiến phản ứng của con người trở nên bất khả thi — trong khi các nhà ra quyết định con người cần ngày hoặc tuần để hiểu mối đe dọa và phối hợp phản ứng, một hệ thống siêu trí tuệ có thể thực hiện các cuộc tấn công hạ tầng toàn cầu, triển khai nhiều vũ khí sinh học và thiết lập kiểm soát không thể đảo ngược đối với các nguồn lực quan trọng trong vài giờ.